O mais recente modelo ChatQA2 lançado pela Nvidia AI alcançou avanços significativos no campo de compreensão de contexto de texto longo e geração aprimorada de recuperação (RAG). Ele é baseado no poderoso modelo Llama3, que melhora significativamente os recursos de acompanhamento de instruções, o desempenho do RAG e os recursos de compreensão de textos longos, estendendo a janela de contexto para tokens de 128K e adotando o ajuste fino de instruções em três estágios. ChatQA2 é capaz de manter coerência contextual e alta recuperação ao processar dados de texto massivos e demonstrou desempenho comparável ao GPT-4-Turbo em vários testes de benchmark, e até o superou em alguns aspectos. Isto marca um avanço significativo na capacidade de grandes modelos de linguagem lidarem com textos longos.
Avanço no desempenho: o ChatQA2 melhora significativamente os recursos de acompanhamento de instruções, o desempenho do RAG e a compreensão de textos longos, estendendo a janela de contexto para tokens de 128 mil e adotando um processo de ajuste de instruções em três estágios. Este avanço tecnológico permite que o modelo mantenha coerência contextual e alta recuperação ao processar conjuntos de dados de até 1 bilhão de tokens.
Detalhes técnicos: ChatQA2 foi desenvolvido utilizando soluções técnicas detalhadas e reproduzíveis. O modelo primeiro expande a janela de contexto do Llama3-70B de 8K para 128K tokens por meio de pré-treinamento contínuo. Em seguida, um processo de ajuste de instruções em três estágios foi aplicado para garantir que o modelo pudesse lidar com eficácia com uma variedade de tarefas.
Resultados da avaliação: Na avaliação do InfiniteBench, o ChatQA2 alcançou precisão comparável ao GPT-4-Turbo-2024-0409 em tarefas como resumo de texto longo, perguntas e respostas, múltipla escolha e diálogo, e superou-o no benchmark RAG. Essa conquista destaca os recursos abrangentes do ChatQA2 em diferentes comprimentos de contexto e recursos.
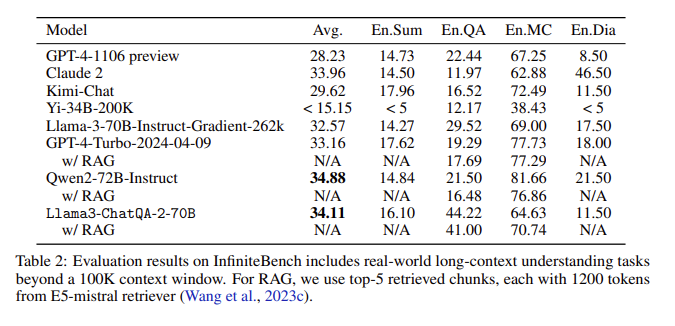
Abordando questões-chave: O ChatQA2 aborda questões-chave no processo RAG, como fragmentação de contexto e baixa recuperação, usando um recuperador de texto longo de última geração para melhorar a precisão e a eficiência da recuperação.
Ao estender a janela de contexto e implementar um processo de ajuste de instruções de três estágios, o ChatQA2 alcança compreensão de textos longos e desempenho RAG comparável ao GPT-4-Turbo. Este modelo fornece soluções flexíveis para uma variedade de tarefas posteriores, equilibrando precisão e eficiência por meio de técnicas avançadas de geração de texto longo e recuperação aprimorada.
Entrada de papel: https://arxiv.org/abs/2407.14482
O surgimento do ChatQA2 traz novas possibilidades para processamento de textos longos e aplicações RAG. Sua eficiência e precisão fornecem um valor de referência importante para o desenvolvimento futuro da inteligência artificial. A investigação aberta sobre este modelo também promove a colaboração entre a academia e a indústria, impulsionando o progresso contínuo neste campo. Esperamos ver aplicações mais inovadoras baseadas neste modelo no futuro.