Визуальные подписи
v1.0
Инструмент субтитров Visual Captions Visual Captions — это недавно выпущенный мощный инструмент субтитров, который может улучшить отображение большего количества субтитров для рабочих встреч пользователей и сделать офисное общение более удобным. Нуждающиеся пользователи могут прийти и присоединиться к нам.
Google продемонстрировала систему Visual Captions на ACM CHI (Конференция по человеческому фактору в вычислительных системах), ведущей конференции по взаимодействию человека и компьютера, представив новое визуальное решение для удаленных встреч, которое может генерировать или извлекать изображения в контексте разговор для улучшения работы другой стороны. Знание сложных или незнакомых концепций.
Система Visual Captions основана на точно настроенной крупномасштабной языковой модели, которая может заранее рекомендовать соответствующие визуальные элементы в разговорах с открытым словарным запасом, и была интегрирована в проект с открытым исходным кодом ARChat.
В ходе опроса пользователей исследователи пригласили 26 участников в лаборатории и 10 участников за пределами лаборатории оценить систему. Более 80% пользователей в основном согласились с тем, что Video Captions может предоставлять субтитры к видео в различных сценариях, которые являются полезными и содержательными. и улучшить качество общения.
Перед разработкой исследователи сначала пригласили 10 внутренних участников, включая инженеров-программистов, исследователей, UX-дизайнеров, художников-визуалистов, студентов и других практиков с техническим и нетехническим образованием, чтобы обсудить конкретные потребности и требования к услугам визуального улучшения в реальном времени. ожидать.
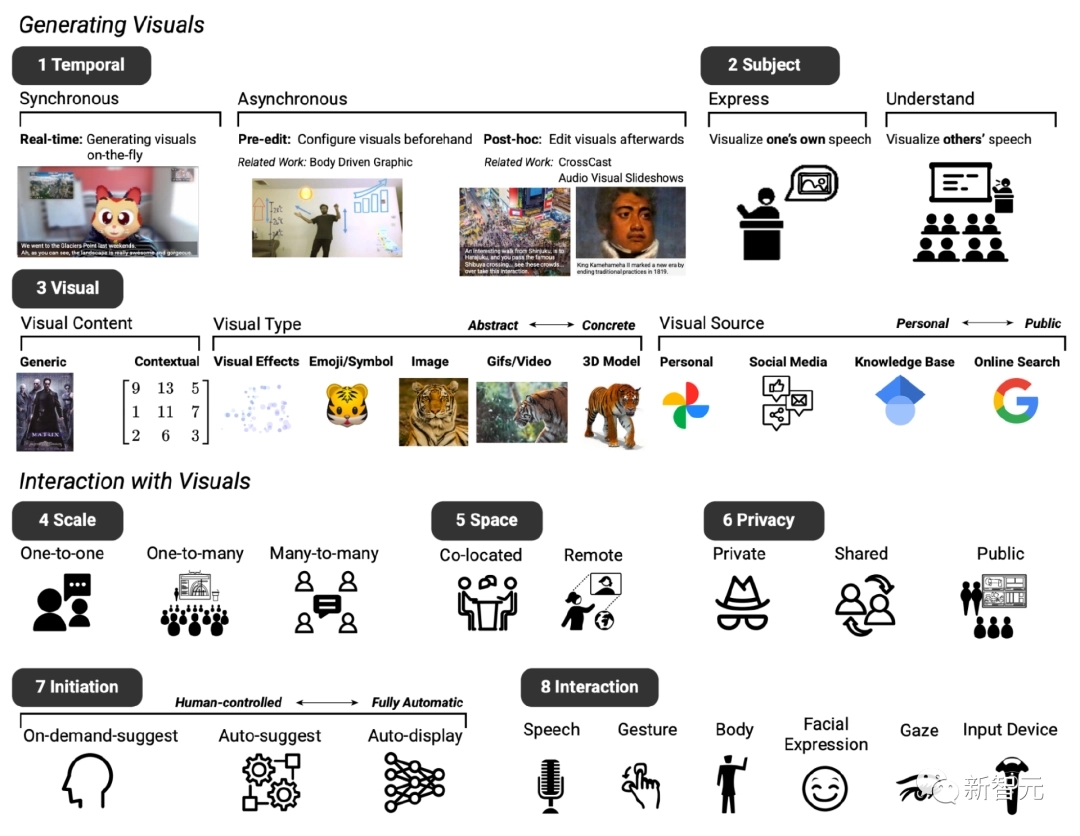
После двух встреч на основе существующей системы преобразования текста в изображение была создана базовая конструкция ожидаемого прототипа системы, в основном включающая восемь измерений (обозначенных как D1–D8).
D1: Тайминг, система визуального улучшения может отображаться синхронно или асинхронно с диалогом.
D2: Тема, которую можно использовать для выражения и понимания содержания речи.
D3: Визуальный, с использованием широкого спектра визуального контента, визуальных типов и визуальных источников.
D4: масштабирование, визуальные улучшения могут различаться в зависимости от размера собрания.
D5: Пространство, независимо от того, проводится ли видеоконференция в одном помещении или в удаленной обстановке.
D6: Конфиденциальность. Эти факторы также влияют на то, следует ли отображать визуальные эффекты конфиденциально, делиться ими между участниками или делать их доступными для всех.
D7: Исходное состояние, участники также определили различные способы, которыми они хотели бы взаимодействовать с системой во время разговора, например, разные уровни «инициативы», когда пользователи могут самостоятельно определять, когда система вмешивается в чат. D8: Взаимодействие, участники предусмотрели различные методы взаимодействия, такие как ввод с помощью голоса или жестов.