Прочтите это на английском языке
GLM-4-Voice — это сквозная речевая модель, запущенная Zhipu AI. GLM-4-Voice может напрямую понимать и генерировать китайские и английские голоса, вести голосовые разговоры в реальном времени и изменять эмоции, интонацию, скорость, диалект и другие атрибуты голоса в соответствии с инструкциями пользователя.

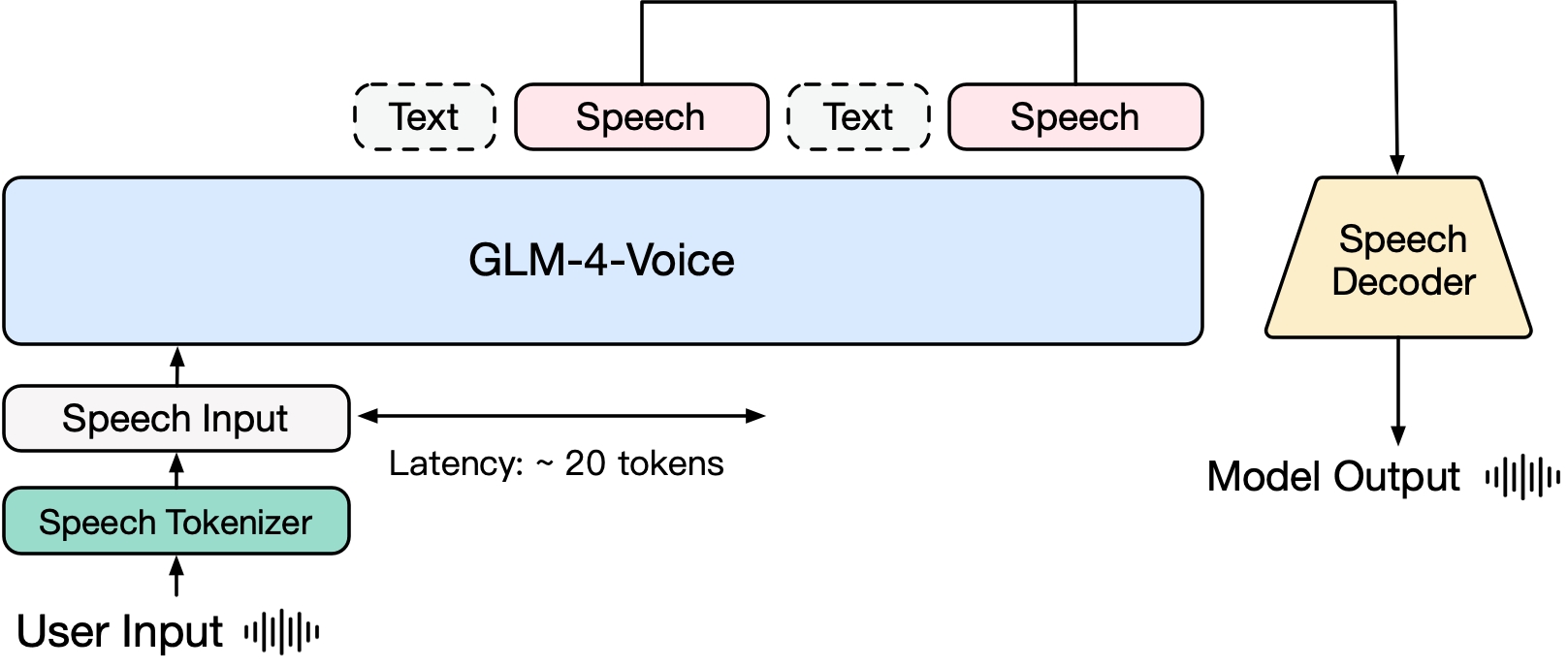
GLM-4-Voice состоит из трех частей:
GLM-4-Voice-Tokenizer: благодаря добавлению векторного квантования в часть кодировщика Whisper и контролируемому обучению на данных ASR непрерывный голосовой ввод преобразуется в дискретные токены. В среднем аудио должно быть представлено всего 12,5 дискретными токенами в секунду.
GLM-4-Voice-Decoder: декодер речи, который поддерживает потоковую обработку и обучен на основе структуры модели Flow Matching CosyVoice для преобразования дискретных речевых токенов в непрерывный речевой вывод. Для начала генерации необходимо как минимум 10 голосовых токенов, что сокращает задержку сквозного разговора.
GLM-4-Voice-9B: на основе GLM-4-9B выполняется предварительное обучение и согласование речевых модальностей для понимания и генерации дискретизированных речевых токенов.
С точки зрения предварительного обучения, чтобы преодолеть две трудности, связанные с IQ модели и синтетической выразительностью в речевом режиме, мы разделили задачу Speech2Speech на «создание текстового ответа на основе звука пользователя» и «синтез речи на основе текстовый ответ и речь пользователя». Две задачи и две цели предварительного обучения предназначены для синтеза чередующихся речевых и текстовых данных на основе текстовых данных предварительного обучения и неконтролируемых аудиоданных для адаптации к этим двум формам задач. Основанный на базовой модели GLM-4-9B, GLM-4-Voice-9B был предварительно обучен с использованием миллионов часов аудио и сотен миллиардов токенов чередующихся аудио-текстовых данных и обладает хорошим пониманием и моделированием звука. . способность.
С точки зрения согласования, для поддержки качественного голосового диалога мы разработали архитектуру потокового мышления: в зависимости от голоса пользователя GLM-4-Voice может попеременно выводить контент в двух режимах: текстовом и голосовом в потоковом формате. голосовой режим представлен Текст используется в качестве ссылки для обеспечения высокого качества содержимого ответа, а соответствующие голосовые изменения вносятся в соответствии с требованиями голосовых команд пользователя. Он по-прежнему имеет возможность сквозного моделирования с сохранением. IQ языковой модели в наибольшей степени и в то же время имеет низкую задержку. Для синтеза речи необходимо всего лишь вывести минимум 20 токенов.
Более подробный технический отчет будет опубликован позже.
| Модель | Тип | Скачать |
|---|---|---|
| GLM-4-Голосовой токенизатор | Речевой токенизатор | ? |
| GLM-4-Голос-9B | Модель чата | ? |
| GLM-4-голосовой декодер | Речевой декодер | ? |
Мы предоставляем веб-демонстрацию, которую можно запустить напрямую. Пользователи могут вводить голос или текст, и модель будет давать как голосовые, так и текстовые ответы.

Сначала скачайте репозиторий
git clone --recurse-submodules https://github.com/THUDM/GLM-4-Voicecd GLM-4-Voice
Затем установите зависимости. Вы также можете использовать предоставленный нами образ zhipuai/glm-4-voice:0.1 чтобы пропустить этот шаг.
pip install -r требования.txt
Так как модель Декодера не поддерживает инициализацию через transformers , то чекпоинт нужно скачивать отдельно.
# загрузка модели git, убедитесь, что у вас установлен git-lfsgit lfs install git-клон https://huggingface.co/THUDM/glm-4-voice-decoder
Запустить сервис модели
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype bfloat16 --device cuda:0
Если вам нужно загрузиться с точностью Int4, запустите
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype int4 --device cuda:0
Эта команда автоматически загрузит glm-4-voice-9b . Если условия сети плохие, вы также можете вручную загрузить и указать локальный путь через --model-path .
Запустить веб-сервис
python web_demo.py --tokenizer-path THUDM/glm-4-voice-tokenizer --model-path THUDM/glm-4-voice-9b --flow-path ./glm-4-voice-decoder
Вы можете получить доступ к веб-демо по адресу http://127.0.0.1:8888.
Эта команда автоматически загружает glm-4-voice-tokenizer и glm-4-voice-9b . Обратите внимание, что glm-4-voice-decoder необходимо загружать вручную.
Если условия сети плохие, вы можете вручную загрузить эти три модели, а затем указать локальный путь через --tokenizer-path , --flow-path и --model-path .
Потоковое воспроизведение звука Gradio нестабильно. Качество звука будет выше при нажатии в диалоговом окне после завершения генерации.
Мы приводим несколько примеров разговоров GLM-4-Voice, включая контроль эмоций, изменение скорости речи, генерацию диалектов и т. д.
Направь меня, чтобы расслабиться мягким голосом
Комментирование футбольных матчей взволнованным голосом
Расскажи историю о привидениях жалобным голосом
Расскажите, насколько холодна зима на северо-восточном диалекте.
Скажите «Ешьте виноград, не выплевывая виноградную кожуру» на диалекте Чунцина.
Произнесите скороговорку на пекинском диалекте
говори быстрее
Быстрее
Часть кода этого проекта взята из:
Уютный Голос
трансформаторы
ГЛМ-4
Использование весов модели GLM-4 должно соответствовать протоколу модели.
Код этого репозитория с открытым исходным кодом соответствует протоколу Apache 2.0.