Официальная версия хранилища аналитических данных Apache Kylin v4.0.3
4.0.3
Apache Kylin: инструмент для выполнения запросов за доли секунды для чрезвычайно больших данных
Редактор даункодов
Apache Kylin — это распределенное аналитическое хранилище данных с открытым исходным кодом, которое предоставляет интерфейс SQL-запросов и возможности многомерного анализа (OLAP) поверх Hadoop/Spark и может эффективно обрабатывать чрезвычайно большие данные. Первоначально разработанный eBay и предоставленный сообществом открытого исходного кода, он выполняет запросы к огромным данным за доли секунды.
Три главных шага Кайлина
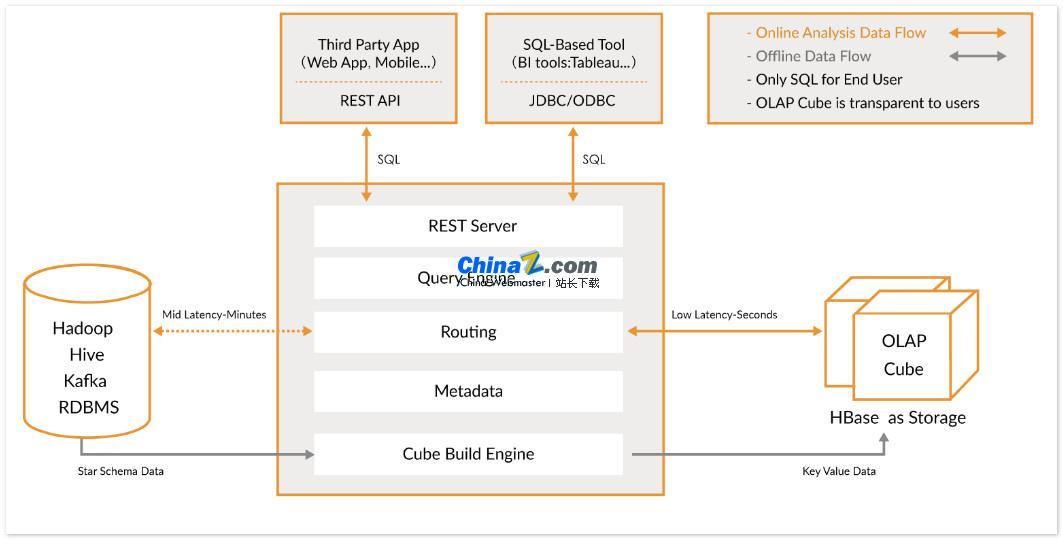
Kylin позволяет пользователям выполнять запросы за доли секунды к очень большим наборам данных всего за три шага:
1. Определите модель звезды или снежинки в своем наборе данных. Сначала вам нужно определить модель звезды или снежинки для описания вашего набора данных. Это поможет Кайлину понять взаимосвязь между данными и тем самым оптимизировать производительность запросов.
2. Создание куба. Создание куба на основе определенной таблицы данных — это модуль Kylin для предварительного вычисления и хранения данных, что может значительно повысить скорость выполнения запросов.
3. Используйте стандартный SQL-запрос. Используйте стандартный синтаксис SQL для запроса Cube через ODBC, JDBC или RESTFUL API. Kylin может возвращать результаты запроса за доли секунды.
Возможности интеграции Kylin
Kylin интегрируется с различными инструментами визуализации данных, такими как Tableau, Power BI и т. д. Пользователи могут использовать эти инструменты BI для анализа данных Hadoop и визуального отображения аналитической информации.
Подвести итог
Apache Kylin — это мощный инструмент, который может помочь пользователям выполнять запросы к чрезвычайно большим данным за доли секунды. Простота использования, масштабируемость и эффективность делают его идеальным для крупномасштабного анализа данных.