Magika — это новый инструмент определения типов файлов на базе искусственного интеллекта, который опирается на последние достижения глубокого обучения для обеспечения точного обнаружения. Под капотом Magika используется специальная высокооптимизированная модель Keras, которая весит всего несколько МБ и обеспечивает точную идентификацию файлов в течение миллисекунд, даже при работе на одном процессоре.
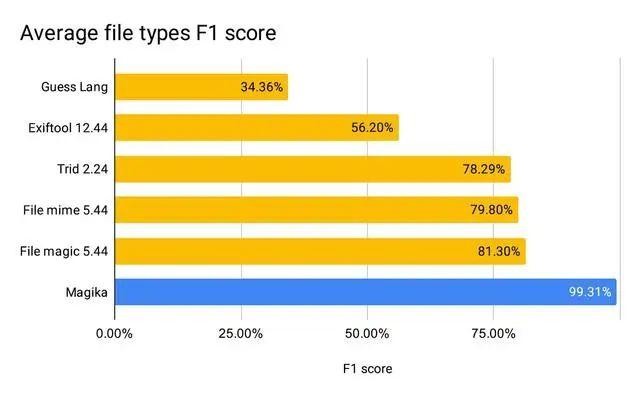
При оценке более 1 миллиона файлов и более 100 типов контента (охватывающих как двоичные, так и текстовые форматы файлов) Magika достигает точности и полноты более 99%. Magika используется в масштабе, чтобы помочь повысить безопасность пользователей Google путем маршрутизации файлов Gmail, Диска и безопасного просмотра на соответствующие сканеры политики безопасности и контента. Подробности читайте в нашей исследовательской статье!
Вы можете попробовать Magika, ничего не устанавливая, воспользовавшись нашей веб-демоверсией, которая запускается локально в вашем браузере!
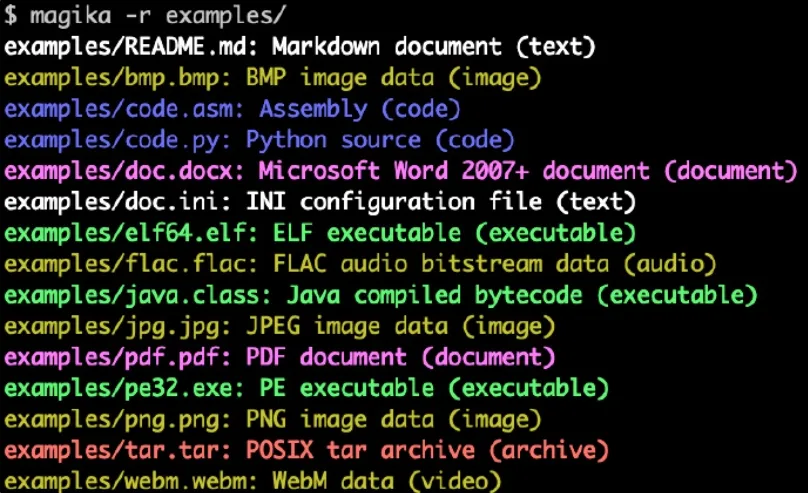
Вот пример того, как выглядит вывод командной строки Magika:
Для получения дополнительной информации вы можете прочитать наш первый анонс в блоге Google OSS.

Важный
Мы собираемся выпустить ряд новинок, и они готовы к тестированию!
Новая модель машинного обучения с поддержкой более 200 типов контента.
Новый CLI, написанный на Rust. Это заменит предыдущий интерфейс командной строки, написанный на Python. Дополнительная информация здесь. Кодовую базу Rust также можно использовать для приложений, написанных на Rust, см. документацию.
Пакет Python 0.6.0rc1: эта версия включает новую модель с поддержкой более 200 типов контента, интерфейс командной строки, написанный на Rust (который заменяет старый, написанный на Python), и обновленный API Python с несколькими критическими изменениями, см. документацию. и список изменений! Если вам нужна документация о стабильной версии, просмотрите этот репозиторий по последней стабильной версии здесь.
Доступен в виде инструмента командной строки, написанного на Rust, API Python, API Rust и экспериментальной версии TFJS (на которой основана наша веб-демо).
Обучение проводилось на наборе данных, содержащем более 25 миллионов файлов более чем 100 типов контента.
По нашей оценке, Magika достигает средней точности и полноты 99%+, превосходя существующие подходы.
Более 200 типов контента (см. полный список).
После загрузки модели (это разовые издержки) время вывода составляет около 5 мс на файл.
Пакетная обработка: вы можете одновременно передавать в командную строку и API несколько файлов, а Magika будет использовать пакетную обработку для ускорения времени вывода. Вы можете вызвать Magika даже с тысячами файлов одновременно. Вы также можете использовать -r для рекурсивного сканирования каталога.
Почти постоянное время вывода независимо от размера файла; Magika использует только ограниченное подмножество байтов файла.
Magika использует пороговую систему для каждого типа контента, которая определяет, следует ли «доверять» прогнозу модели или возвращать общую метку, например «Общий текстовый документ» или «Неизвестные двоичные данные».
Поддерживаются три различных режима прогнозирования, которые настраивают устойчивость к ошибкам: high-confidence , medium-confidence и best-guess .
Это открытый исходный код! (И многое еще впереди.)
Более подробную информацию см. в документации по пакету Python и пакету js (документация разработчика).
Начиная
Командная строка Python
API Python
Экспериментальная модель TFJS и пакет npm
Установка
Запуск в Докере
Использование
Настройка разработки
Важная документация
Известные ограничения и вклад
Часто задаваемые вопросы
Дополнительные ресурсы
Исследовательская статья и цитирование
Лицензия
Отказ от ответственности
Магика доступна как magika на PyPI:
$ pip установить магику
Если вы собираетесь использовать Magika только в качестве командной строки, вместо этого вы можете использовать $ pipx install magika .
git clone https://github.com/google/magika cd magika/ docker build -t magika . docker run -it --rm -v $(pwd):/magika magika -r /magika/tests_data
Новая командная строка написана на Rust и доступна в пакете magika python.
Примеры:
$ cdtest_data/basic && magika -r *asm/code.asm: Сборка (код) batch/simple.bat: пакетный файл DOS (код) c/code.c: исходный код C (код) css/code.css: исходный код CSS (код) csv/magika_test.csv: CSV-документ (код) dockerfile/Dockerfile: Dockerfile (код) docx/doc.docx: документ Microsoft Word 2007+ (документ) epub/doc.epub: документ EPUB (документ) epub/magika_test.epub: документ EPUB (документ) flac/test.flac: данные битового потока аудио FLAC (аудио) handlebars/example.handlebars: исходный код руля (код) html/doc.html: HTML-документ (код). ini/doc.ini: файл конфигурации INI (текст). javascript/code.js: исходный код JavaScript (код) jinja/example.j2: шаблон Jinja (код) jpeg/magika_test.jpg: данные изображения JPEG (изображение) json/doc.json: документ JSON (код) latex/sample.tex: документ LaTeX (текст) makefile/simple.Makefile: Исходный код Makefile markdown/README.md: документ Markdown (текст) [...]
$ magika ./tests_data/basic/python/code.py --json
[
{ "path": "./tests_data/basic/python/code.py", "result": { "status": "ok", "value": { "dl": { "description": "Исходный код Python" , "расширения": [ "py", "pyi"
], "group": "code", "is_text": true, "label": "python", "mime_type": "text/x-python"
}, "output": { "description": "Исходный код Python", "extensions": [ "py", "pyi"
], "group": "code", "is_text": true, "label": "python", "mime_type": "text/x-python"
}, «оценка»: 0,753000020980835
}
}
}
]$ кот doc.ini | магика - -: INI-файл конфигурации (текст)
$ магика --помощь
Определяет тип содержимого файлов с помощью глубокого обучения
Использование: magika [ОПЦИИ] [ПУТЬ]...
Аргументы: [ПУТЬ]...
Список путей к файлам для анализа.
Используйте тире (-) для чтения из стандартного ввода (можно использовать только один раз).
Параметры:
-r, --рекурсивный
Идентифицирует файлы внутри каталогов вместо идентификации самого каталога.
--no-разыменование
Идентифицирует символические ссылки как есть, вместо того, чтобы идентифицировать их содержимое, переходя по ним.
--цвета
Цветная печать независимо от поддержки терминала
--no-colors
Печатает без цветов независимо от поддержки терминала
-s, --output-score
Печатает оценку прогноза в дополнение к типу контента.
-i, --mime-тип
Печатает тип MIME вместо описания типа контента.
-l, --label
Печатает простую этикетку вместо описания типа контента.
--json
Печатает в формате JSON.
--jsonl
Печатает в формате JSONL.
--format <ПОЛЬЗОВАТЕЛЬСКИЙ>
Печатает в пользовательском формате (для получения подробной информации используйте --help).
Поддерживаются следующие заполнители:
%p Путь к файлу
%l Уникальная метка, определяющая тип контента.
%d Описание типа контента
%g Группа типа контента.
%m Тип MIME типа контента.
%e Возможные расширения файлов для типа контента
%s Оценка типа контента для файла
%S Оценка типа контента для файла в процентах.
%b Выходные данные модели, если правило отменено (в противном случае пусто)
%% Буквальный %
-х, --help
Распечатать справку (см. сводку с помощью '-h')
-V, --версия
Версия для печатиСм. здесь для более подробной документации.
Примеры:
>> from magika import Magika>>> m = Magika()>>> res = m.identify_bytes(b"# ПримерnЭто пример уценки!")>>> print(res.output.label)markdown
Подробную документацию смотрите в документации Python.
Мы также предоставляем Magika в качестве экспериментального пакета для людей, заинтересованных в использовании в веб-приложении. Обратите внимание, что производительность реализации Magika JS значительно ниже, и вам следует ожидать, что на каждый файл будет потрачено более 100 мс.
Подробности смотрите в документации js.
См. раздел «Настройка разработки» в документации Python.
Документация по CLI
Документация о новом интерфейсе командной строки Rust
Документация о привязках для разных языков
Список поддерживаемых типов контента (для версии 1 будет еще больше).
Список поддерживаемых типов контента для новой модели
Документация о том, как интерпретировать вывод Magika.
Часто задаваемые вопросы
Магика значительно совершенствуется по сравнению с современными моделями, но всегда есть куда совершенствоваться! Можно проделать дополнительную работу по повышению точности обнаружения, поддержке дополнительных типов контента, привязке большего количества языков и т. д.
Этот первоначальный выпуск не предназначен для обнаружения полиглотов, и мы с нетерпением ждем возможности увидеть состязательные примеры от сообщества. Нам также хотелось бы услышать мнение сообщества о возникших проблемах, неправильных определениях, запросах на добавление функций, необходимости поддержки дополнительных типов контента и т. д.
Проверьте наши открытые проблемы GitHub, чтобы узнать, что находится в нашей дорожной карте, и сообщите о неправильных обнаружениях или запросах функций, открыв проблемы GitHub (предпочтительно) или отправив нам электронное письмо по адресу [email protected].
ПРИМЕЧАНИЕ. НЕ отправляйте отчеты о файлах, которые могут содержать персональные данные, отчет содержит (небольшую) часть содержимого файла!
Подробности смотрите на CONTRIBUTING.md .
Здесь мы собрали ряд часто задаваемых вопросов.
Сообщение в блоге Google OSS об анонсе Magika.
Веб-демо: веб-демо.
В нашей исследовательской статье мы описываем, как мы разрабатывали Magika и какой выбор сделали.
Если вы используете это программное обеспечение для своих исследований, укажите его как:
@misc{magika, title={{Magika: обнаружение типов контента с помощью искусственного интеллекта}}, автор={{Фратантонио, Яник и Инверницци, Лука и Фара, Луа и Курт, Томас и Чжан, Марина и Альбертини, Анж и Галилея , Франсуа и Метитьери, Джанкарло и Кретен, Жюльен и Пети-Бьянко, Александр и Тао, Давид и Бурштейн, Эли}}, год={2024}, eprint={2409.13768}, archivePrefix={arXiv}, PrimaryClass={cs. CR}, URL={https://arxiv.org/abs/2409.13768},
}Пожалуйста, свяжитесь с нами напрямую по адресу [email protected].
Апач 2.0; подробности см. в LICENSE .
Этот проект не является официальным проектом Google. Он не поддерживается Google, и Google отказывается от всех гарантий относительно его качества, коммерческой пригодности или пригодности для конкретной цели.