авто раунд
Intel®
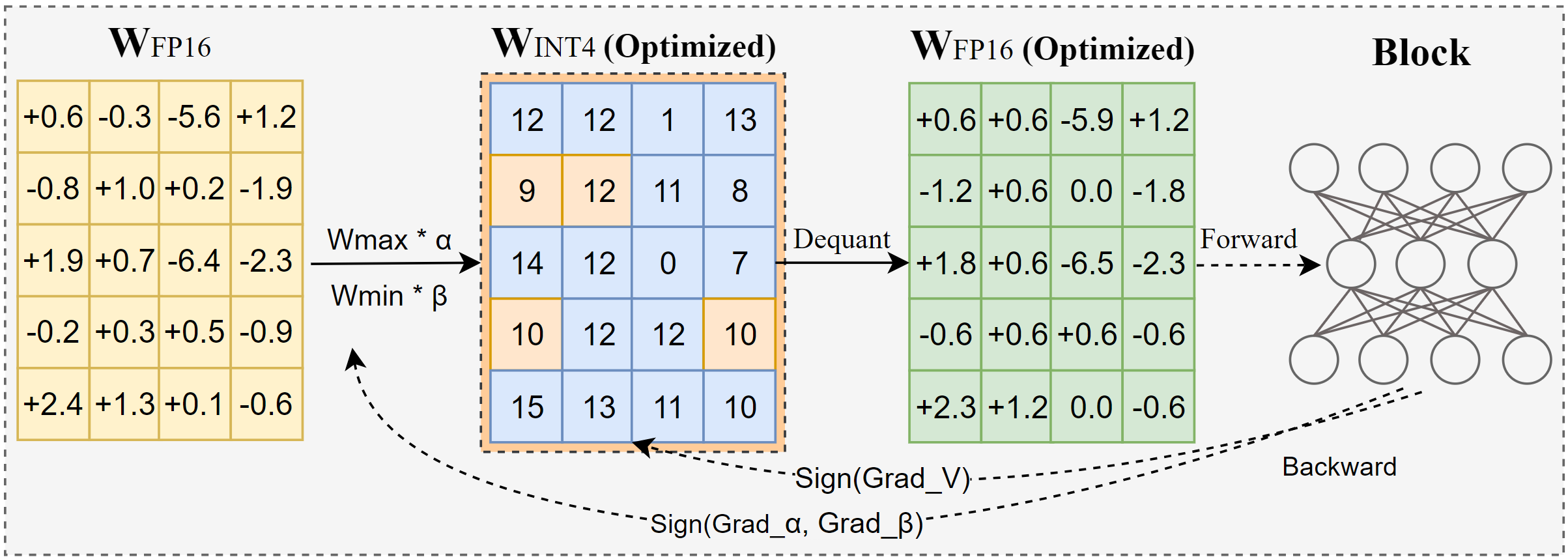
AutoRound — это усовершенствованный алгоритм квантования для вывода LLM с низкими битами. Он предназначен для широкого спектра моделей. AutoRound использует спуск знакового градиента для точной настройки значений округления и минимальных значений весов всего за 200 шагов, что впечатляюще конкурирует с новейшими методами, не внося никаких дополнительных затрат на вывод и сохраняя низкие затраты на настройку. На изображении ниже представлен обзор AutoRound. Ознакомьтесь с нашей статьей об arxiv для получения более подробной информации и посетите low_bit_open_llm_leaderboard для получения более точных данных и рецептов для различных моделей.


[2024/10] AutoRound интегрирован в torch/ao, ознакомьтесь с их примечаниями к выпуску.
[2024/10] Важное обновление: теперь мы поддерживаем полнодиапазонное симметричное квантование и сделали его конфигурацией по умолчанию. Эта конфигурация обычно лучше или сравнима с асимметричным квантованием и значительно превосходит другие симметричные варианты, особенно при низкой разрядности, например 2-битной.
[2024/09] Формат AutoRound поддерживает несколько моделей LVM, посмотрите примеры Qwen2-Vl,Phi-3-vision, Llava
[2024/08] Формат AutoRound поддерживает устройства Intel Gaudi2. Пожалуйста, обратитесь к Intel/Qwen2-7B-int4-inc.
[2024/08] AutoRound представляет несколько экспериментальных функций, включая быструю настройку параметров нормы/смещения (для 2-битного режима и W4A4), квантование активации и тип данных mx_fp.
pip install -vvv --no-build-isolation -e .
pip install автоокругление
Руководство пользователя с подробным описанием полного списка поддерживаемых аргументов можно получить, вызвав auto-round -h на терминале. Альтернативно вы можете использовать auto_round вместо auto-round . Установите нужный формат в format , и поддерживается экспорт нескольких форматов.
CUDA_VISIBLE_DEVICES=0 автоокругление
--модель Facebook/opt-125m
--биты 4
--group_size 128
--format "auto_round,auto_gptq"
--disable_eval
--output_dir ./tmp_autoroundМы предлагаем два рецепта максимальной точности и высокой скорости работы при малом объеме памяти. Подробности, как показано ниже.
## лучшая точность, в 3 раза медленнее, low_gpu_mem_usage может сэкономить ~20 ГБ, но на ~30% медленнееCUDA_VISIBLE_DEVICES=0 автоокругление --модель Facebook/opt-125m --биты 4 --group_size 128 --nsamples 512 --итеров 1000 --low_gpu_mem_usage --disable_eval
## быстрая и малая память, ускорение в 2-3 раза, небольшое снижение точности при автоокруглении W4G128CUDA_VISIBLE_DEVICES=0 --модель Facebook/opt-125m --биты 4 --group_size 128 --nsamples 128 --итеров 200 --seqlen 512 --batch_size 4 --disable_eval
Формат автоокругления : этот формат хорошо подходит для процессоров, устройств HPU, 2 бит, а также для вывода смешанной точности. Поддерживаются биты [2,4]. Он также извлекает выгоду из ядра Marlin, которое может значительно повысить производительность вывода. Однако он еще не получил широкого распространения в обществе.
Формат AutoGPTQ : этот формат хорошо подходит для симметричного квантования на устройствах CUDA и широко принят сообществом, поддерживаются биты [2,3,4,8]. Он также извлекает выгоду из ядра Marlin, которое может значительно повысить производительность вывода. Однако у асимметричного ядра есть проблемы , которые могут привести к значительному падению точности, особенно при 2-битном квантовании и небольших моделях. Кроме того, симметричное квантование имеет тенденцию плохо работать с точностью до 2 бит.
Формат AutoAWQ : этот формат хорошо подходит для асимметричного 4-битного квантования на устройствах CUDA и широко распространен в сообществе, поддерживается только 4-битное квантование. Он имеет специальное слияние слоев, специально разработанное для моделей Llama.
из трансформаторов import AutoModelForCausalLM, AutoTokenizermodel_name = "facebook/opt-125m"model = AutoModelForCausalLM.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)from auto_round import AutoRoundbits, group_size, sym = 4, 128, Trueautoround = AutoRound(model, tokenizer) , bits=bits, group_size=group_size, sym=sym)## лучшая точность, в 3 раза медленнее, low_gpu_mem_usage может сэкономить ~20 ГБ, но на ~30% медленнее# autoround = AutoRound(model, tokenizer, nsamples=512, iters=1000, low_gpu_mem_usage =True, bits=bits, group_size=group_size, sym=sym)## быстрая и низкая память, ускорение в 2-3 раза, небольшое падение точности на W4G128# autoround = AutoRound(model, tokenizer, nsamples=128, iters=200, seqlen =512,atch_size=4,bits=bits, group_size=group_size, sym=sym )autoround.quantize()output_dir = "./tmp_autoround"## format= 'auto_round'(по умолчанию в версии>0.3.0), 'auto_gptq ', 'auto_awq'autoround.save_quantized(output_dir, format='auto_round', inplace=True)
Тестирование проводилось на Nvidia A100 80G с использованием ночной версии PyTorch 2.6.0.dev20241029+cu124. Обратите внимание, что затраты на загрузку и упаковку данных были исключены из оценки. Мы включаем torch.compile для Torch 2.6, но не для 2.5 из-за возникших проблем.
Чтобы оптимизировать использование памяти графического процессора, помимо активации low_gpu_mem_usage , вы можете установитьgradient_accumulate_steps gradient_accumulate_steps=8 и batch_size=1 , хотя это может увеличить время настройки.
Модели 3B и 14B тестировались на Qwen 2.5, модель 8X7B — на Mixtral, а остальные модели использовали LLaMA 3.1.
| Версия горелки/конфигурация W4G128 | 3Б | 8Б | 14Б | 70Б | 8X7B |
|---|---|---|---|---|---|
| 2.6 с компиляцией факела | 7мин 10 ГБ | 12 минут 18 ГБ | 23мин 22 ГБ | 120 минут 42 ГБ | 28 минут 46 ГБ |
| 2.6 с компиляцией факела low_gpu_mem_usage=Истина | 12 минут 6 ГБ | 19 минут 10 ГБ | 33 минуты 11 ГБ | 140 минут 25 ГБ | 38 минут 36 ГБ |
| 2.6 с компиляцией факела low_gpu_mem_usage=Истина gradient_accumulate_steps=8,bs=1 | 15 минут 3 ГБ | 25 минут 6 ГБ | 45мин 7 ГБ | 187 минут 19 ГБ | 75мин 36 ГБ |
| 2.5 без сборки горелки | 8 минут 10 ГБ | 16 минут 20 ГБ | 30 минут 25 ГБ | 140 минут 49 ГБ | 50 минут 49 ГБ |
Пожалуйста, сначала запустите код квантования
ЦП : версия auto_round >0.3.1 , pip install intel-extension-for-pytorch (гораздо более высокая скорость на процессоре Intel) или pip install intel-extension-for-transformers,
HPU : рекомендуется образ докера с Gaudi Software Stack. Более подробную информацию можно найти в Путеводителе Гауди.
CUDA : никаких дополнительных операций для сим-квантования, для асимметрии необходимо установить автоокругление из исходного кода.
из трансформаторов import AutoModelForCausalLM, AutoTokenizerfrom auto_round import AutoRoundConfigbackend = "auto" ##cpu, hpu, cuda, cuda:marlin (поддерживается в auto_round>0.3.1 и 'pip install -v gptqmodel --no-build-isolation')quantization_config = AutoRoundConfig(backend=backend)quantized_model_path = "./tmp_autoround"model = AutoModelForCausalLM.from_pretrained(quantized_model_path, device_map=backend.split(':')[0], quantization_config=quantization_config)tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)text = " Есть девушка, которая любит приключения, "inputs = tokenizer(text, return_tensors="pt").to(model.device)print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]) ) автоматическое округление --model save_quantized_model
--eval
--task Ламбада_openai
--eval_bs 1из трансформеров import AutoModelForCausalLM, AutoTokenizerquantized_model_path = "./tmp_autoround"model = AutoModelForCausalLM.from_pretrained(quantized_model_path, device_map="auto") tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)text = "Есть девушка, которая любит приключения",inputs = tokenizer( text, return_tensors="pt").to(model.device)print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]))
AutoRound поддерживает практически все основные модели больших языков.
Обратите внимание, что звездочка (*) обозначает сторонние квантованные модели, которым могут не хватать данных о точности и использовать другой рецепт. Мы высоко ценим их усилия и призываем больше пользователей делиться своими моделями, поскольку мы не можем выпускать большинство моделей самостоятельно.
| Модель | Поддерживается |
|---|---|
| мета-лама/Мета-Ллама-3.1-70B-Instruct | рецепт |
| мета-лама/Мета-лама-3.1-8B-Instruct | модель-kaitchup-autogptq-int4*, модель-kaitchup-autogptq-sym-int4*, рецепт |
| мета-лама/Мета-лама-3.1-8B | модель-kaitchup-autogptq-sym-int4* |
| Квен/Квен-ВЛ | точность, рецепт |
| Квен/Квен2-7B | модель-autoround-sym-int4, модель-autogptq-sym-int4 |
| Qwen/Qwen2-57B-A14B-Инструктировать | модель-autoround-sym-int4,модель-autogptq-sym-int4 |
| 01-ай/Йи-1.5-9Б | модель-LnL-AI-autogptq-int4* |
| 01-ai/Yi-1.5-9B-Чат | модель-LnL-AI-autogptq-int4* |
| Intel/нейронный чат-7b-v3-3 | модель-autogptq-int4 |
| Intel/нейронный чат-7b-v3-1 | модель-autogptq-int4 |
| TinyLlama-1.1B-средний | модель-LnL-AI-autogptq-int4* |
| мистралай/Мистраль-7Б-v0.1 | модель-autogptq-lmhead-int4, модель-autogptq-int4 |
| гугл/джемма-2b | модель-autogptq-int4 |
| tiiuae/falcon-7b | модель-autogptq-int4-G64 |
| sapienzanlp/modello-italia-9b | модель-fbaldassarri-autogptq-int4* |
| Майкрософт/фи-2 | модель-autoround-sym-int4 модель-autogptq-sym-int4 |
| Microsoft/Phi-3.5-мини-инструкция | модель-kaitchup-autogptq-sym-int4* |
| Microsoft/Phi-3-vision-128k-инструктировать | рецепт |
| мистралай/Mistral-7B-Instruct-v0.2 | точность, рецепт, пример |
| мистралай/Mixtral-8x7B-Instruct-v0.1 | точность, рецепт, пример |
| мистралай/Mixtral-8x7B-v0.1 | точность, рецепт, пример |
| мета-лама/Мета-лама-3-8B-Instruct | точность, рецепт, пример |
| гугл/джемма-7b | точность, рецепт, пример |
| мета-лама/Llama-2-7b-chat-hf | точность, рецепт, пример |
| Qwen/Qwen1.5-7B-Чат | точность, рецепт сима, рецепт асима, пример |
| baichuan-inc/Baichuan2-7B-Чат | точность, рецепт, пример |
| 01-ai/Yi-6B-Чат | точность, рецепт, пример |
| Facebook/opt-2.7b | точность, рецепт, пример |
| большая наука/блум-3b | точность, рецепт, пример |
| ЭлеутерAI/gpt-j-6b | точность, рецепт, пример |
AutoRound интегрирован в несколько репозиториев.
Нейронный компрессор Intel
МодельОблако/GPTQModel
питорч/ао
Если вы считаете, что AutoRound полезен для вашего исследования, процитируйте нашу статью:
@article{cheng2023optimize,
title={Оптимизация округления веса с помощью знакового градиентного спуска для квантования LLM},
автор={Чэн, Вэньхуа и Чжан, Вэйвэй и Шэнь, Хайхао и Цай, Иян и Хэ, Синь и Льв, Каокао и Лю, И},
журнал={препринт arXiv arXiv:2309.05516},
год={2023}
}