ВикиЧат
v2.0!
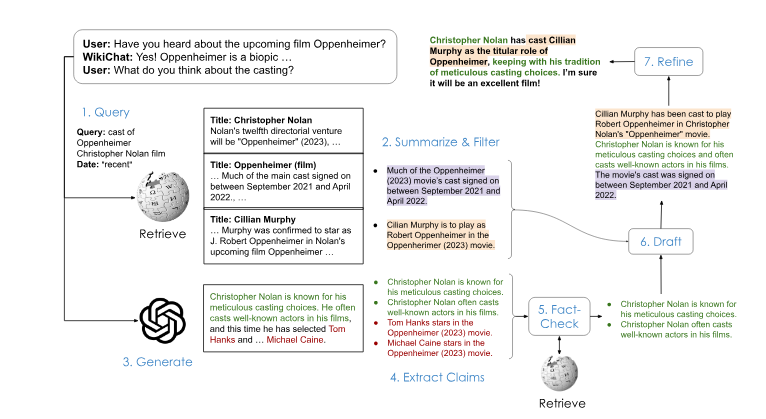
Чат-боты с большой языковой моделью (LLM), такие как ChatGPT и GPT-4, часто ошибаются, особенно если информация, которую вы ищете, свежа («Расскажите мне о Суперкубке 2024 года») или на менее популярные темы («Что такое какие хорошие фильмы посмотреть [вставьте своего любимого иностранного режиссёра]?»). WikiChat использует Википедию и следующий семиэтапный конвейер, чтобы гарантировать достоверность ответов. Каждый пронумерованный этап включает в себя один или несколько вызовов LLM.

Более подробную информацию можно найти в нашей статье: Сина Дж. Семнани, Вайолет З. Яо*, Хайди К. Чжан* и Моника С. Лам. 2023. WikiChat: Остановить галлюцинации чат-ботов с большими языковыми моделями путем краткого изучения Википедии. В выводах Ассоциации компьютерной лингвистики: EMNLP 2023, Сингапур. Ассоциация компьютерной лингвистики.
(22 августа 2024 г.) WikiChat 2.0 теперь доступен! Ключевые обновления включают в себя:
Теперь поддерживается извлечение не только текста, но и структурированных данных, таких как таблицы, информационные поля и списки.
Имеет общедоступные сценарии предварительной обработки Википедии высочайшего качества.
Использует современную многоязычную поисковую модель BGE-M3.
Использует Qdrant для масштабируемого векторного поиска.
Использует RankGPT для изменения рейтинга результатов поиска.
Многоязычная поддержка: по умолчанию извлекает информацию из 10 различных Википедий: ?? Английский, ?? Китайский, ?? Испанский, ?? Португальский, ?? Русский, ?? Немецкий, ?? Фарси, ?? японец, ?? Французский и ?? Итальянский.
Улучшенный поиск информации
Бесплатный многоязычный API поиска в Википедии: мы предлагаем высококачественный бесплатный (но с ограничениями по скорости) API поиска для доступа к 10 Википедиям, охватывающим более 180 миллионов векторных вложений.
Расширенная совместимость с LLM: поддержка более 100 LLM через единый интерфейс благодаря LiteLLM.
Оптимизированный конвейер: вариант более быстрого и экономичного конвейера за счет объединения этапов «генерации» и «извлечения претензий» WikiChat.
Совместимость с LangChain: Полностью совместим с LangChain ?️?.
И многое другое!
(20 июня 2024 г.) WikiChat получил премию Wikimedia Research Award 2024!
Награда @Wikimedia Research Award 2024 года достается теме «Викичат: остановить галлюцинации чат-ботов с большими языковыми моделями путем краткого изучения Википедии» ⚡
— Wiki Workshop 2024 (@wikiworkshop), 20 июня 2024 г.
? https://t.co/d2M8Qrarkw pic.twitter.com/P2Sh47vkyi
(16 мая 2024 г.) Наша дополнительная статья «? СПАГЕТТИ: ответы на вопросы в открытой области из гетерогенных источников данных с поиском и семантическим анализом» принята к выводам ACL 2024. В этом документе добавлена поддержка структурированных данных, таких как таблицы и информационные окна. и списки.
(8 января 2024 г.) Выпущены дистиллированные модели LLaMA-2. Вы можете запускать эти модели локально, чтобы получить более дешевую и быструю альтернативу платным API.
(8 декабря 2023 г.) Мы представляем нашу работу на выставке EMNLP 2023.
(27 октября 2023 г.) Версия нашей статьи для камеры теперь доступна на arXiv.
(6 октября 2023 г.) Наша статья принята в список выводов EMNLP 2023.
Установка WikiChat включает в себя следующие шаги:
Установить зависимости
Настройте LLM по вашему выбору. WikiChat поддерживает более 100 LLM, включая модели OpenAI, Azure, Anthropic, Mistral, HuggingFace, Together.ai и Groq.
Выберите источник получения информации. Это может быть любая конечная точка HTTP, соответствующая интерфейсу, определенному в файле retriever/retriever_server.py. Мы предоставляем инструкции и скрипты для следующих вариантов:
Используйте наш бесплатный API с ограниченной скоростью для Википедии на 10 языках.
Загрузите и разместите предоставленный индекс Википедии самостоятельно.
Создайте и запустите новый пользовательский индекс из ваших собственных документов.
Запустите WikiChat с желаемой конфигурацией.
[Необязательно] Разверните WikiChat для многопользовательского доступа. Мы предоставляем код для развертывания простого внешнего и внутреннего интерфейса, а также инструкции по подключению к базе данных Azure Cosmos DB для хранения разговоров.
Этот проект был протестирован с Python 3.10 в Ubuntu 20.04 LTS (Focal Fossa), но он должен быть совместим со многими другими дистрибутивами Linux. Если вы планируете использовать это в Windows WSL или macOS или с другой версией Python, будьте готовы к возможным устранению неполадок во время установки.
Требования к оборудованию различаются в зависимости от предполагаемого использования:
Базовое использование: запуск WikiChat с API LLM и нашим API поиска в Википедии имеет минимальные требования к оборудованию и должен работать на большинстве систем.
Индекс локального поиска. Если вы планируете разместить индекс поиска локально, убедитесь, что у вас достаточно места на диске для индекса. Для больших индексов задержка получения сильно зависит от скорости диска, поэтому мы рекомендуем использовать твердотельные накопители и предпочтительно диски NVMe. Например, для этого подходят виртуальные машины с оптимизацией хранилища, такие как Standard_L8s_v3 в Azure.
Локальный LLM: если вы планируете использовать WikiChat с локальным LLM, для размещения модели необходим графический процессор.
Создание нового индекса поиска. Если вы хотите индексировать коллекцию, вам понадобится графический процессор для встраивания документов в векторы. Для работы модели внедрения по умолчанию (BAAI/BGE-M3) требуется не менее 13 ГБ памяти графического процессора.
Сначала клонируйте репозиторий:
git-клон https://github.com/stanford-oval/WikiChat.git компакт-диск ВикиЧат
Мы рекомендуем использовать среду conda, указанную в conda_env.yaml. Эта среда включает Python 3.10, pip, gcc, g++, make, Redis и все необходимые пакеты Python.
Убедитесь, что у вас установлена Conda, Anaconda или Miniconda. Затем создайте и активируйте среду conda:
conda env create --file conda_env.yaml Конда активирует викичат python -m spacy скачать en_core_web_sm # Spacy необходим только для определенных конфигураций WikiChat
Если после запуска чат-бота вы видите сообщение «Ошибка: поиск Redis не выполнен», это, вероятно, означает, что Redis установлен неправильно. Вы можете попробовать переустановить его, следуя официальной документации.
Держите эту среду активированной для всех последующих команд.
Установите Docker для вашей операционной системы, следуя инструкциям на странице https://docs.docker.com/engine/install/. WikiChat использует Docker в первую очередь для создания и обслуживания векторных баз данных для поиска, в частности? Вывод встраивания текста и Qdrant. В последних версиях Ubuntu вы можете попробовать запустить inv install-docker. Для других операционных систем следуйте инструкциям на сайте докера.
WikiChat использует функцию вызова для добавления пользовательских команд для различных целей. Чтобы просмотреть все доступные команды и их описания, выполните:
вызвать --list
или сокращение:
инв -л
Для получения более подробной информации о конкретной команде используйте:
inv [имя команды] --help
Эти команды реализованы в папке Tasks/.
WikiChat совместим с различными LLM, включая модели OpenAI, Azure, Anthropic, Mistral, Together.ai и Groq. Вы также можете использовать WikiChat со многими локально размещенными моделями через HuggingFace.
Чтобы настроить LLM:
Заполните соответствующие поля в llm_config.yaml.
Создайте файл с именем API_KEYS (который включен в .gitignore).
В файле API_KEYS установите ключ API для конечной точки LLM, которую вы хотите использовать. Имя ключа API должно совпадать с именем, которое вы указали в llm_config.yaml в разделе api_key. Например, если вы используете модели OpenAI через конечные точки openai.com и Mistral, ваш файл API_KEYS может выглядеть так:
# Заполните следующие значения своими ключами API. Убедитесь, что после ключа нет лишнего места. # Изменения в этом файле игнорируются git, поэтому вы можете безопасно хранить здесь свои ключи во время разработки. OPENAI_API_KEY=[Ваш ключ API OpenAI с https://platform.openai.com/ API-ключи] MISTRAL_API_KEY=[Ваш API-ключ Mistral с https://console.mistral.ai/api-keys/]
Обратите внимание, что локально размещенным моделям НЕ нужен ключ API, но вам необходимо предоставить OpenAI-совместимую конечную точку в api_base. Код был протестирован с помощью ? Вывод генерации текста.
По умолчанию WikiChat получает информацию из 10 Википедий через конечную точку https://wikichat.genie.stanford.edu/search/. Если вы хотите просто попробовать WikiChat, вам не нужно ничего менять.
Загрузите индекс 10 языков Википедии по состоянию на 1 августа 2024 г. с сайта ? Hub и извлеките его:
inv download-wikipedia-index --workdir ./workdir
Обратите внимание, что этот индекс содержит около 180 миллионов векторных вложений и поэтому требует не менее 500 ГБ пустого дискового пространства. Он использует двоичное квантование Qdrant для снижения требований к оперативной памяти до 55 ГБ без ущерба для точности и задержки.
Запустите сервер FastAPI, аналогичный варианту 1, который отвечает на запросы HTTP POST:
inv start-retriever --embedding-model BAAI/bge-m3 --retriever-port <номер порта>
Запустите WikiChat, передав URL-адрес этого ретривера. Например:
inv demo --retriever-endpoint "http://0.0.0.0:<номер порта>/search"
Обратите внимание, что этот сервер и его встроенная модель работают на ЦП и не требуют графического процессора. Для повышения производительности в совместимых системах вы можете добавить --use-onnx, чтобы использовать версию модели внедрения ONNX, чтобы значительно снизить задержку внедрения.
Следующая команда загрузит, предварительно обработает и проиндексирует последний дамп HTML курдской Википедии, который мы используем в этом примере из-за его относительно небольшого размера.
inv index-wikipedia-dump --embedding-model BAAI/bge-m3 --workdir ./workdir --language ku
Предварительно обработайте данные в файл строк JSON (с расширением .jsonl или .jsonl.gz), где каждая строка имеет следующие поля:
{"id": "integer", "content_string": "string", "article_title": "string", "full_section_title": "string", "block_type": "string", "language": "string", " Last_edit_date": "строка (необязательно)", "num_tokens": "целое число (необязательно)"}content_string должен представлять собой фрагментированный текст ваших документов. Мы рекомендуем разбивать токенизатор модели внедрения на менее чем 500 токенов. См. здесь обзор методов фрагментации.block_type и язык используются только для фильтрации результатов поиска. Если они вам не нужны, вы можете просто установить для них значения Block_type=text и Language=en. Скрипт передаст full_section_title и content_string в модель внедрения для создания векторов внедрения.
См. preprocessing/preprocess_wikipedia_html_dump.py для получения подробной информации о том, как это реализовано для дампов HTML Википедии.
Запустите команду индексирования:
inv index-collection --collection-path <путь к предварительно обработанному JSONL> --collection-name <имя>
Эта команда запускает контейнеры докеров для? Вывод встраивания текста (по одному на каждый доступный графический процессор). По умолчанию используется образ докера, совместимый с графическими процессорами NVIDIA с архитектурой Ampere 80, например A100. Также доступна поддержка некоторых других графических процессоров, но вам нужно будет выбрать правильный образ Docker из доступных образов Docker.
(Необязательно) Добавьте индекс полезной нагрузки
получение Python/add_payload_index.py
Это позволит выполнять запросы с фильтрацией по языку или типу блока. Обратите внимание, что для больших индексов может потребоваться несколько минут, чтобы индекс снова стал доступен.
После индексации загрузите и используйте индекс, как в варианте 2. Например:
inv start-retriever --embedding-model BAAI/bge-m3 --retriever-port <номер порта>curl -X POST 0.0.0.0:5100/search -H "Тип контента: application/json" -d '{" query": ["Что такое GPT-4?", "Что такое LLaMA-3?"], "num_blocks": 3}'Запустите WikiChat, передав URL-адрес этого ретривера. Например:
inv demo --retriever-endpoint "http://0.0.0.0:<номер порта>/search"
Разделите индекс на более мелкие части:
tar -cvf - <путь к индексной папке Qdrant> | свинья -п 14 | Split --bytes=10GB --numeric-suffixes=0 --suffix-length=4 - <путь к выходной папке>/qdrant_index.tar.gz.part-
Загрузите получившиеся части:
python retrival/upload_folder_to_hf_hub.py --folder_path <путь к выходной папке> --repo_id <идентификатор репозитория на ? Хаб>
Вы можете запускать различные конфигурации WikiChat, используя такие команды:
inv demo --engine gpt-4o # engine может иметь любое значение, настроенное в llm_config, например, mistral-large, claude-sonnet-35, local inv demo --pipelinegenerate_and_correct # доступные конвейеры: Early_combine,generate_and_correct иget_and_generate inv demo --temperature 0.9 # изменяет температуру этапов взаимодействия с пользователем, таких как уточнение
Чтобы получить полный список всех доступных опций, вы можете запустить inv demo --help
Этот репозиторий предоставляет код для развертывания веб-интерфейса чата через Chainlit и хранения разговоров пользователей в базе данных Cosmos DB. Они реализованы в файлах backend_server.py и data.py соответственно. Если вы хотите использовать другие базы данных или интерфейсы, вам необходимо изменить эти файлы. Для разработки должно быть просто удалить зависимость от Cosmos DB и просто хранить разговоры в памяти. Вы также можете настроить параметры чат-бота, определенные в backend_server.py, например, для использования другого LLM или добавления/удаления этапов WikiChat.
После создания экземпляра через Azure получите строку подключения и добавьте это значение в API_KEYS.
COSMOS_CONNECTION_STRING=[Ваша строка подключения к Cosmos DB]
Запустив это, вы запустите внутренние и внешние серверы. Затем вы можете получить доступ к внешнему интерфейсу по указанному порту (по умолчанию 5001).inv Chainlit --backend-port 5001
Вы можете использовать эту конечную точку API для создания прототипов высококачественных систем RAG. См. https://wikichat.genie.stanford.edu/search/redoc для получения полной спецификации.
Обратите внимание, что мы не предоставляем никаких гарантий относительно этой конечной точки, и она не подходит для производства.
(Вскоре...)
Мы публично публикуем предварительно обработанную Википедию на 10 языках.
WikiChat 2.0 несовместим с выпущенными доработанными контрольно-пропускными пунктами LLaMA-2. Пожалуйста, обратитесь к версии 1.0 на данный момент.
Чтобы оценить чат-бота, вы можете смоделировать разговоры с помощью симулятора пользователя. Параметр subset может быть одним из head, Tail или недавних, что соответствует трем подмножествам, представленным в документе WikiChat. Вы также можете указать язык пользователя (ВикиЧат всегда отвечает на языке пользователя). Этот скрипт считывает тему (т. е. заголовок и статью Википедии) из соответствующего файла эталонного теста/topics/{subset}_articles_{language}.json. Используйте --num-dialogues, чтобы установить количество генерируемых смоделированных диалогов, и --num-turns, чтобы указать количество поворотов в каждом диалоге.
inv имитации-пользователей --num-dialogues 1 --num-turns 2 --simulation-mode проход --language en --subset head
В зависимости от используемого вами двигателя это может занять некоторое время. Имитированные диалоги и файлы журналов будут сохранены в сравнительном каталоге «benchmark/simulated_dialogues/». Вы также можете указать любой из параметров конвейера, указанных выше. Вы можете поэкспериментировать с различными характеристиками пользователя, изменив user_characteristics в бенчмарке/user_simulator.py.
Код WikiChat, а также модели и данные выпускаются под лицензией Apache-2.0.
Если вы использовали код или данные из этого репозитория, дайте ссылку на следующие документы:
@inproceedings{semnani-etal-2023-wikichat,title = "{W}iki{C}hat: Остановить галлюцинацию чат-ботов с большими языковыми моделями путем краткого изучения {Википедии",author = "Семнани, Сина и Яо, Вайолет и Чжан, Хайди и Лам, Моника",editor = "Буамор, Худа и Пино, Хуан и Бали, Калика",booktitle = "Выводы Ассоциации компьютерной лингвистики: EMNLP 2023", месяц = декабрь, год = "2023",address = "Сингапур",publisher = "Ассоциация компьютерной лингвистики",url = "https://aclanthology.org/2023.findings-emnlp.157",pages = "2387--2413",
}@inproceedings{zhang-etal-2024-spaghetti,title = "{СПАГЕТТИ}: ответы на вопросы открытой области из гетерогенных источников данных с поиском и семантическим анализом",author = "Чжан, Хайди и Семнани, Сина и Гассеми, Фархад и Сюй, Цзялян и Лю, Шичэн и Лам, Моника",редактор = "Ку, Лунь-Вэй и Мартинс, Андре и Шрикумар, Вивек",booktitle = "Выводы Ассоциации компьютерной лингвистики ACL 2024", месяц = август, год = "2024", адрес = "Бангкок, Таиланд и виртуальная встреча", издатель = "Ассоциация компьютерной лингвистики", URL = "https://aclanthology.org/2024.findings-acl.96",pages = "1663- -1678",
}