Камил Словиковски
2024-04-22
Оглавление
Здесь мы публикуем один файл afnd.tsv (5,99 МБ) в формате с разделителями-табуляциями со всеми частотами аллелей для 8 генов HLA, 18 генов KIR, 2 генов MIC и 29 генов цитокинов из базы данных сети частот аллелей (AFND).
Скрипт allelefrequency.py автоматически загружает частоты аллелей с сайта.
Что такое база данных сети частот аллелей?
База данных частот аллелей (AFND) представляет собой общедоступную базу данных, которая содержит информацию о частоте нескольких иммунных генов, таких как человеческие лейкоцитарные антигены (HLA), иммуноглобулиноподобные рецепторы киллерных клеток (KIR), главный комплекс гистосовместимости, связанный с цепочкой I класса (MIC). ) гены и ряд полиморфизмов генов цитокинов.
Файл afnd.tsv выглядит следующим образом:
d <- fread( " afnd.tsv " )
head( d ) ## group gene allele population indivs_over_n alleles_over_2n n
## 1: hla A A*01:01 Argentina Rosario Toba 15.1 0.0760 86
## 2: hla A A*01:01 Armenia combined Regions 0.1250 100
## 3: hla A A*01:01 Australia Cape York Peninsula Aborigine 0.0530 103
## 4: hla A A*01:01 Australia Groote Eylandt Aborigine 0.0270 75
## 5: hla A A*01:01 Australia New South Wales Caucasian 0.1870 134
## 6: hla A A*01:01 Australia Yuendumu Aborigine 0.0080 191
Определения:
alleles_over_2n (Аллели / 2n) Частота аллели: общее количество копий аллели в выборке населения в трехдесятичном формате.
indivs_over_n (100 * Индивидуумы/n) Процент особей, имеющих аллель или ген.
n (Особи) Число особей, отобранных из генеральной совокупности.
Вот несколько примеров того, как мы можем использовать R для анализа этих данных.
Просмотрите самые большие и самые маленькие популяции, доступные в данных:
d % > %
mutate( n = parse_number( n )) % > %
select( population , n ) % > %
unique() % > %
arrange( - n ) ## population n
## 1: Germany DKMS - German donors 3456066
## 2: USA NMDP European Caucasian 1242890
## 3: USA NMDP African American pop 2 416581
## 4: USA NMDP Mexican or Chicano 261235
## 5: USA NMDP South Asian Indian 185391
## ---
## 1489: Cameroon Sawa 13
## 1490: Paraguay/Argentina Ache NA-DHS_24 (G) 13
## 1491: Malaysia Orang Kanaq Cytokine 11
## 1492: Cameroon Baka Pygmy 10
## 1493: Paraguay/Argentina Guarani NA-DHS_23 (G) 10
Подсчитайте количество аллелей каждого гена:
d % > %
count( group , gene , allele ) % > %
count( group , gene ) % > %
arrange( - n ) % > %
head( 15 ) ## group gene n
## 1: hla B 1979
## 2: hla A 1394
## 3: hla C 1209
## 4: hla DRB1 954
## 5: hla DPB1 384
## 6: hla DQB1 351
## 7: kir 3DL1 90
## 8: mic MICA 69
## 9: kir 3DL3 67
## 10: kir 2DL1 52
## 11: kir 2DL4 35
## 12: mic MICB 34
## 13: hla DQA1 30
## 14: kir 3DL2 30
## 15: kir 2DL5B 24
Суммируйте частоты аллелей для каждого гена в каждой популяции. Это позволяет нам увидеть, какие популяции имеют набор частот аллелей, составляющий в сумме 100 процентов:
d % > %
mutate( alleles_over_2n = parse_number( alleles_over_2n )) % > %
filter( alleles_over_2n > 0 ) % > %
group_by( group , gene , population ) % > %
summarize( sum = sum( alleles_over_2n )) % > %
count( sum == 1 ) ## `summarise()` has grouped output by 'group', 'gene'. You can override using the `.groups` argument.
## # A tibble: 44 × 4
## # Groups: group, gene [28]
## group gene `sum == 1` n
##
## 1 hla A FALSE 420
## 2 hla A TRUE 18
## 3 hla B FALSE 513
## 4 hla B TRUE 19
## 5 hla C FALSE 323
## 6 hla C TRUE 19
## 7 hla DPA1 FALSE 54
## 8 hla DPA1 TRUE 6
## 9 hla DPB1 FALSE 207
## 10 hla DPB1 TRUE 39
## # ℹ 34 more rows
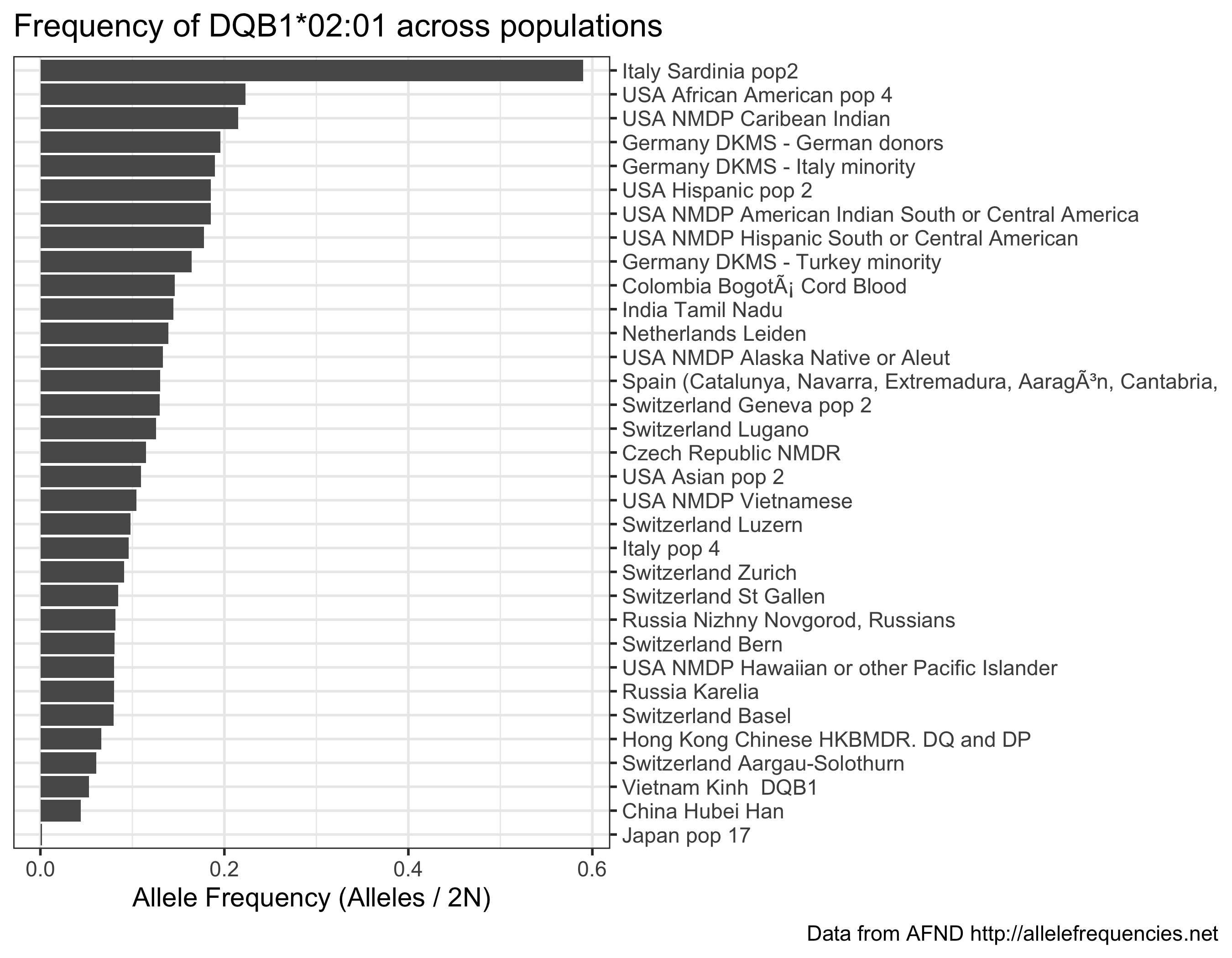
Постройте частоту определенного аллеля в популяциях с более чем 1000 выборками:
my_allele <- " DQB1*02:01 "
my_d <- d % > % filter( allele == my_allele ) % > %
mutate(
n = parse_number( n ),
alleles_over_2n = parse_number( alleles_over_2n )
) % > %
filter( n > 1000 ) % > %
arrange( - alleles_over_2n )
ggplot( my_d ) +
aes( x = alleles_over_2n , y = reorder( population , alleles_over_2n )) +
scale_y_discrete( position = " right " ) +
geom_colh() +
labs(
x = " Allele Frequency (Alleles / 2N) " ,
y = NULL ,
title = glue( " Frequency of {my_allele} across populations " ),
caption = " Data from AFND http://allelefrequencies.net "
)
Если вы используете эти данные, процитируйте последнюю рукопись о базе данных сети частот аллелей :
@ARTICLE{Gonzalez-Galarza2020,
title = "{Allele frequency net database (AFND) 2020 update: gold-standard
data classification, open access genotype data and new query
tools}",
author = "Gonzalez-Galarza, Faviel F and McCabe, Antony and Santos, Eduardo
J Melo Dos and Jones, James and Takeshita, Louise and
Ortega-Rivera, Nestor D and Cid-Pavon, Glenda M Del and
Ramsbottom, Kerry and Ghattaoraya, Gurpreet and Alfirevic, Ana
and Middleton, Derek and Jones, Andrew R",
journal = "Nucleic acids research",
volume = 48,
number = "D1",
pages = "D783--D788",
month = jan,
year = 2020,
language = "en",
issn = "0305-1048, 1362-4962",
pmid = "31722398",
doi = "10.1093/nar/gkz1029",
pmc = "PMC7145554"
}
Вот все ресурсы, которые я смог найти, которые содержат информацию о частотах аллелей HLA в разных популяциях.
https://github.com/Vaccitech/HLAfreq/
Авторы предоставляют файлы xlsx на этом сайте:
Но информация о частоте разбита на категории:
Существует инструмент под названием HLA-Net, который обеспечивает визуализацию данных CIWD.
http://tools.iedb.org/population/download
На странице инструментов IEDB мы можем найти инструмент под названием «Охват населения» . Авторы загрузили информацию о частоте HLA из AFND и сохранили ее в файле рассола Python.
https://www.ncbi.nlm.nih.gov/gv/mhc
База данных и веб-сайт dbMHC, похоже, больше не поддерживаются. Но архив старых файлов по-прежнему доступен по FTP.
https://bioinformatics.bethematchclinical.org/hla-resources/haplotype-frequency/high-разрешение-hla-alleles-and-haplotypes-in-the-us-population/
Спасибо Дэвиду А. Уэллсу за то, что поделился ScrapeAF, который вдохновил меня на работу над этим проектом.