DeepKE
DeepKE 2.2.7
английский | 简体中文
Набор инструментов для извлечения знаний на основе глубокого обучения
для построения графа знаний
DeepKE — это набор инструментов для извлечения знаний для построения графов знаний, поддерживающий cnSchema , малоресурсные сценарии , сценарии на уровне документа и мультимодальные сценарии для извлечения сущностей , отношений и атрибутов . Мы предоставляем документы, онлайн-демонстрацию, бумагу, слайды и плакаты для начинающих.
\ в путях к файлам;wisemodel или modescape .Если у вас возникнут какие-либо проблемы во время установки DeepKE и DeepKE-LLM, ознакомьтесь с советами или немедленно сообщите о проблеме, и мы поможем вам решить проблему!
April, 2024 Мы выпускаем новую двуязычную (китайскую и английскую) модель извлечения информации на основе схемы под названием OneKE на основе Chinese-Alpaca-2-13B.Feb, 2024 Мы выпускаем крупномасштабный (0,32 млрд токенов) высококачественный двуязычный (китайский и английский) набор данных инструкций по извлечению информации (IE) под названием IEPile, а также две модели, обученные с помощью IEPile : baichuan2-13b-iepile-lora и llama2. -13b-iepile-lora.Sep 2023 был выпущен двуязычный набор данных инструкций по извлечению информации (IE) на китайском и английском языках под названием InstructIE для задачи построения графа знаний на основе инструкций (KGC на основе инструкций), как подробно описано здесь.June, 2023 Мы обновляем DeepKE-LLM для поддержки извлечения знаний с помощью KnowLM, ChatGLM, LLaMA-серии, GPT-серии и т. д.Apr, 2023 Мы добавили новые модели, в том числе CP-NER(IJCAI'23), ASP(EMNLP'22), PRGC(ACL'21), PURE(NAACL'21), предоставили возможности извлечения событий (китайский и английский), и предлагалась совместимость с более высокими версиями пакетов Python (например, Transformers).Feb, 2023 Мы поддержали использование LLM (GPT-3) с контекстным обучением (на основе EasyInstruct) и генерацией данных, добавили модель NER W2NER (AAAI'22). Nov, 2022 Добавьте инструкции по аннотации данных для распознавания сущностей и извлечения связей, автоматической маркировки слабо контролируемых данных (извлечение сущностей и извлечение связей), а также оптимизируйте обучение нескольких графических процессоров.
Sept, 2022 Документ DeepKE: набор инструментов для извлечения знаний на основе глубокого обучения для совокупности базы знаний был принят в демонстрационную программу системы EMNLP 2022.
Aug, 2022 Мы добавили поддержку увеличения данных (китайский, английский) для извлечения связей с низким уровнем ресурсов.
June, 2022 Мы добавили мультимодальную поддержку извлечения сущностей и отношений.
May, 2022 Мы выпустили DeepKE-cnschema с готовыми моделями извлечения знаний.
Jan, 2022 Мы выпустили документ DeepKE: набор инструментов для извлечения знаний на основе глубокого обучения для населения базы знаний.
Dec, 2021 Мы добавили dockerfile для автоматического создания среды.
Nov, 2021 Выпущена демо-версия DeepKE, поддерживающая извлечение в реальном времени без развертывания и обучения.
Была выпущена документация DeepKE, содержащая подробную информацию о DeepKE, такую как исходные коды и наборы данных.
Oct, 2021 pip install deepke
Выпущены коды deepke-v2.0.
Aug, 2019 Выпущены коды deepke-v1.0.
Aug, 2018 Вышел стартап проекта DeepKE и коды deepke-v0.1.
Происходит демонстрация предсказания. GIF-файл создается Terminalizer. Получите код. 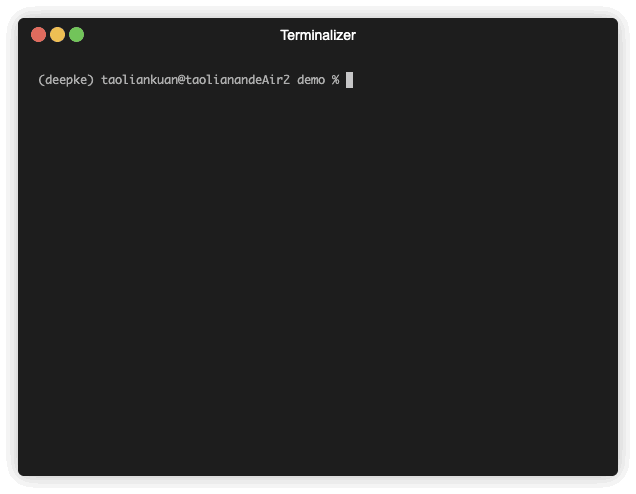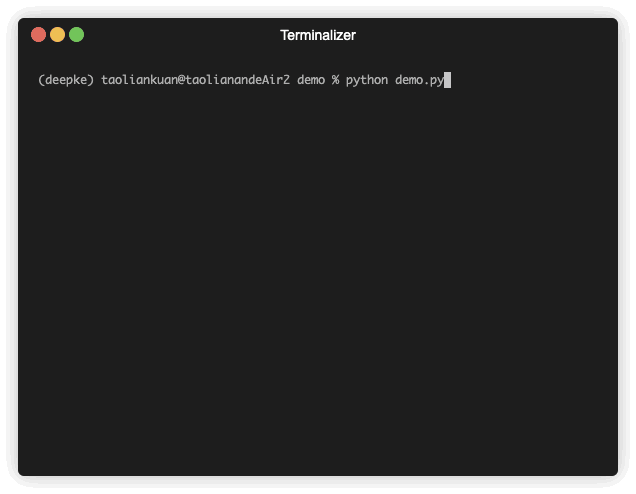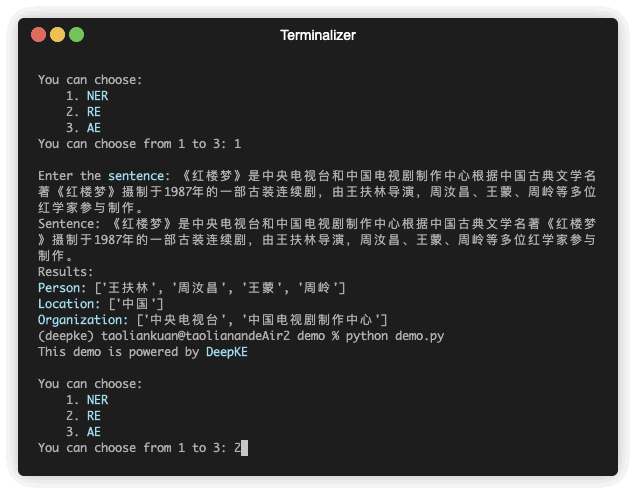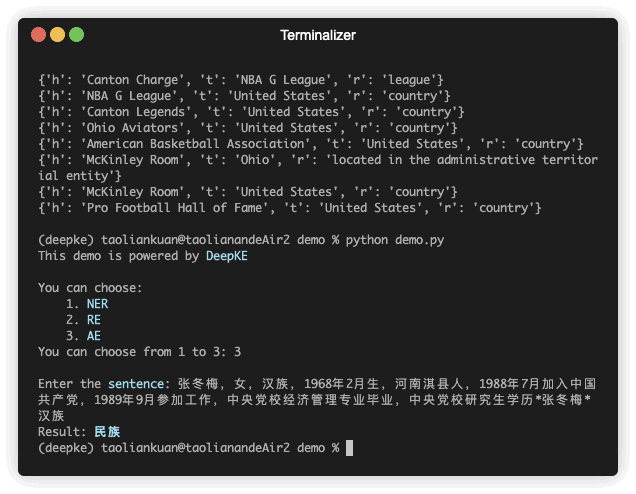
В эпоху больших моделей DeepKE-LLM использует совершенно новую зависимость от среды.
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
Обратите внимание, что файл requirements.txt находится в папке example/llm .
pip install deepke .Шаг 1 Загрузите базовый код
git clone --depth 1 https://github.com/zjunlp/DeepKE.git Шаг 2. Создайте виртуальную среду с помощью Anaconda и войдите в нее.
conda create -n deepke python=3.8
conda activate deepkeУстановите DeepKE с исходным кодом
pip install -r requirements.txt
python setup.py install
python setup.py develop Установите DeepKE с помощью pip ( НЕ рекомендуется! )
pip install deepkeШаг 3. Введите каталог задачи.
cd DeepKE/example/re/standardШаг 4. Загрузите набор данных или следуйте инструкциям в аннотациях, чтобы получить данные.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzПоддерживаются многие типы форматов данных, подробности указаны в каждой части.
Шаг 5. Обучение (Параметры обучения можно изменить в папке conf )
Мы поддерживаем настройку визуальных параметров с помощью wandb .
python run.py Шаг 6. Прогнозирование (Параметры прогнозирования можно изменить в папке conf )
Измените путь обученной модели в predict.yaml . Необходимо использовать абсолютный путь модели, например xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth .
python predict.pyШаг 1. Установите клиент Docker.
Установите Docker и запустите службу Docker.
Шаг 2. Извлеките образ докера и запустите контейнер.
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bashОстальные шаги аналогичны шагу 3 и далее в разделе «Настройка среды вручную» .
питон == 3.8
Распознавание именованных объектов направлено на поиск и классификацию именованных объектов, упомянутых в неструктурированном тексте, по заранее определенным категориям, таким как имена людей, организации, местоположения, организации и т. д.
Данные хранятся в файлах .txt . Вот некоторые примеры (пользователи могут помечать данные с помощью инструментов Doccano, MarkTool или использовать Weak Supervision с DeepKE для автоматического получения данных):
| Предложение | Человек | Расположение | Организация |
|---|---|---|---|
| 9-й день 4-го числа, 杨涌报道: 部分省区人民日报宣传发行工作座谈会9月3日在4日在京举行。 | 杨涌 | 北京 | 人民日报 |
| 《红楼梦》由王扶林导演,周汝昌、王蒙、周岭等多位专家参与制作。 | 王扶林, 周汝昌, 王蒙, 周岭 | ||
| 秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一。 | 秦始皇 | 陕西省, 西安市 |
Прочтите подробный процесс в конкретном README.
СТАНДАРТ (полностью контролируемый)
Мы поддерживаем LLM и предоставляем готовую модель DeepKE-cnSchema-NER, которая позволяет извлекать объекты в cnSchema без обучения.
Шаг 1. Введите DeepKE/example/ner/standard . Загрузите набор данных.
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz Шаг 2. Обучение
Набор данных и параметры можно настроить в папке data и папке conf соответственно.
python run.pyШаг 3. Прогнозирование
python predict.pyНЕСКОЛЬКО ВЫСТРЕЛ
Шаг 1. Введите DeepKE/example/ner/few-shot . Загрузите набор данных.
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz Шаг 2. Обучение в условиях низкого ресурса.
Каталог, в который загружается и сохраняется модель, а параметры конфигурации можно настроить в папке conf .
python run.py +train=few_shot Пользователи могут изменить load_path в conf/train/few_shot.yaml чтобы использовать существующую загруженную модель.
Шаг 3. Добавьте - predict в conf/config.yaml , измените loda_path как путь к модели и write_path как путь, по которому прогнозируемые результаты сохраняются в conf/predict.yaml , а затем запустите python predict.py
python predict.pyМУЛЬТИМОДАЛЬНЫЙ
Шаг 1. Введите DeepKE/example/ner/multimodal . Загрузите набор данных.
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzМы используем обнаруженные объекты RCNN и объекты визуального заземления из исходных изображений в качестве визуальной локальной информации, где RCNN через fast_rcnn и визуальное заземление через onestage_grounding.
Шаг 2 Обучение в мультимодальных условиях
data и папке conf соответственно.load_path в conf/train.yaml как путь, по которому была сохранена модель, обученная в последний раз. Журналы сохранения пути, созданные во время обучения, можно настроить с помощью log_dir . python run.pyШаг 3. Прогнозирование
python predict.pyИзвлечение отношений — это задача извлечения семантических отношений между сущностями из неструктурированного текста.
Данные хранятся в файлах .csv . Вот некоторые примеры (пользователи могут помечать данные с помощью инструментов Doccano, MarkTool или использовать Weak Supervision с DeepKE для автоматического получения данных):
| Предложение | Связь | Голова | Head_offset | Хвост | Tail_offset |
|---|---|---|---|---|---|
| 《岳父也是爹》是王军执导的电视剧,由马恩然、范明主演。 | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》是在纵横中文网连载的一部小说,作者是龙马。 | 连载网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 提起杭州的美景, 西湖总是第一个映入脑海的词语。 | 所在城市 | 西湖 | 8 | 杭州 | 2 |
!ПРИМЕЧАНИЕ. Если для одного отношения существует несколько типов сущностей, типы сущностей могут иметь префикс отношения в качестве входных данных.
Прочтите подробный процесс в конкретном README.
СТАНДАРТ (полностью контролируемый)
Мы поддерживаем LLM и предоставляем готовую модель DeepKE-cnSchema-RE, которая позволяет извлекать отношения в cnSchema без обучения.
Шаг 1. Войдите в папку DeepKE/example/re/standard . Загрузите набор данных.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz Шаг 2. Обучение
Набор данных и параметры можно настроить в папке data и папке conf соответственно.
python run.pyШаг 3. Прогнозирование
python predict.pyНЕСКОЛЬКО ВЫСТРЕЛ
Шаг 1. Введите DeepKE/example/re/few-shot . Загрузите набор данных.
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz Шаг 2. Обучение
data и папке conf соответственно.train_from_saved_model в conf/train.yaml как путь, по которому была сохранена модель, обученная в последний раз. Журналы сохранения пути, созданные во время обучения, можно настроить с помощью log_dir . python run.pyШаг 3. Прогнозирование
python predict.py ДОКУМЕНТ
Шаг 1. Введите DeepKE/example/re/document . Загрузите набор данных.
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz Шаг 2. Обучение
data и папке conf соответственно.train_from_saved_model в conf/train.yaml как путь, по которому была сохранена модель, обученная в последний раз. Журналы сохранения пути, созданные во время обучения, можно настроить с помощью log_dir . python run.pyШаг 3. Прогнозирование
python predict.pyМУЛЬТИМОДАЛЬНЫЙ
Шаг 1. Введите DeepKE/example/re/multimodal . Загрузите набор данных.
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzМы используем обнаруженные объекты RCNN и объекты визуального заземления из исходных изображений в качестве визуальной локальной информации, где RCNN через fast_rcnn и визуальное заземление через onestage_grounding.
Шаг 2. Обучение
data и папке conf соответственно.load_path в conf/train.yaml как путь, по которому была сохранена модель, обученная в последний раз. Журналы сохранения пути, созданные во время обучения, можно настроить с помощью log_dir . python run.pyШаг 3. Прогнозирование
python predict.pyИзвлечение атрибутов предназначено для извлечения атрибутов сущностей в неструктурированном тексте.
Данные хранятся в файлах .csv . Некоторые примеры следующие:
| Предложение | Атт | Энт | Ent_offset | Вал | Val_offset |
|---|---|---|---|---|---|
| 张冬梅, 女, 汉族, 1968 — 2 月生, 河南淇县人 | 民族 | 张冬梅 | 0 | 汉族 | 6 |
| 诸葛亮, 字孔明, 三国时期杰出的军事家、文学家、发明家。 | 朝代 | 诸葛亮 | 0 | 三国时期 | 8 |
| 2014 – 10 сентября 1 года, 鞍华执导的电影《黄金时代》上映 | 上映时间 | 黄金时代 | 19 | 10 сентября 2014 г. | 0 |
Прочтите подробный процесс в конкретном README.
СТАНДАРТ (полностью контролируемый)
Шаг 1. Войдите в папку DeepKE/example/ae/standard . Загрузите набор данных.
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz Шаг 2. Обучение
Набор данных и параметры можно настроить в папке data и папке conf соответственно.
python run.pyШаг 3. Прогнозирование
python predict.py.tsv , в некоторых случаях:| Предложение | Тип события | Курок | Роль | Аргумент | |
|---|---|---|---|---|---|
| 据《欧洲时报》报道,当地时间27日,法国巴黎卢浮宫博物馆员工因不满工作条件恶化而罢工,导致该博物馆也因此闭门谢客一天。 | 组织行为-罢工 | 罢工 | 罢工人员 | 法国巴黎卢浮宫博物馆员工 | |
| 时间 | 当地时间27日 | ||||
| 所属组织 | 法国巴黎卢浮宫博物馆 | ||||
| 中国外运2019年上半年归母净利润增长17%:收购了少数股东股权 | 财经/交易-出售/收购 | 收购 | 出售方 | 少数股东 | |
| 收购方 | 中国外运 | ||||
| 交易物 | 股权 | ||||
| 美国亚特兰大航展13 日发生一起表演机坠机事故,飞行员弹射出舱并安全着陆,事故没有造成人员伤亡。 | 灾害/意外-坠机 | 坠机 | 时间 | 13:00 | |
| 地点 | 美国亚特兰 | ||||
Прочтите подробный процесс в конкретном README.
СТАНДАРТ (полностью контролируемый)
Шаг 1. Войдите в папку DeepKE/example/ee/standard . Загрузите набор данных.
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipШаг 2. Обучение
Набор данных и параметры можно настроить в папке data и папке conf соответственно.
python run.pyШаг 3. Прогнозирование
python predict.py 1. Using nearest mirror THU в Китае ускорит установку Anaconda ; aliyun в Китае ускорит pip install XXX .
2. При обнаружении ModuleNotFoundError: No module named 'past' , запустите pip install future .
3. Установка предварительно обученных языковых моделей онлайн занимает много времени. Рекомендуем перед использованием загрузить предварительно обученные модели и сохранить их в папке pretrained . Прочтите README.md в каждом каталоге задач, чтобы проверить конкретные требования к сохранению предварительно обученных моделей.
4.Старая версия DeepKE находится в ветке deepke-v1.0. Пользователи могут изменить ветку, чтобы использовать старую версию. Старая версия полностью перенесена на стандартное извлечение отношений (example/re/standard).
5.Если вы хотите изменить исходный код, рекомендуется установить DeepKE с исходными кодами. В противном случае модификация не будет работать. Посмотреть проблему
6.Более соответствующие работы по извлечению знаний с низким уровнем ресурсов можно найти в разделе «Извлечение знаний в сценариях с низким уровнем ресурсов: исследование и перспектива».
7. Убедитесь, что в файле requirements.txt указаны точные версии требований.
В следующей версии мы планируем выпустить более мощную версию LLM для KE.
Между тем, мы будем предлагать долгосрочное обслуживание для исправления ошибок , решения проблем и удовлетворения новых запросов . Поэтому, если у вас есть какие-либо проблемы, пожалуйста, задайте их нам.
Data-Efficient Knowledge Graph Construction, 高效知识图谱构建 (Учебное пособие по CCKS 2022) [слайды]
Эффективное и надежное построение графа знаний (Учебное пособие по AACL-IJCNLP 2022) [слайды]
Семья PromptKG: галерея быстрого обучения и исследовательских работ, связанных с КР, наборы инструментов и список статей [Ресурсы]
Извлечение знаний в сценариях с низким уровнем ресурсов: обзор и перспективы [обзор][список статей]
Doccano、MarkTool、LabelStudio: наборы инструментов для аннотаций данных
LambdaKG: библиотека и тест для встраивания KG на основе PLM.
EasyInstruct: простая в использовании платформа для обучения моделям большого языка.
Материалы для чтения :
Data-Efficient Knowledge Graph Construction, 高效知识图谱构建 (Учебное пособие по CCKS 2022) [слайды]
Эффективное и надежное построение графа знаний (Учебное пособие по AACL-IJCNLP 2022) [слайды]
Семья PromptKG: галерея быстрого обучения и исследовательских работ, связанных с КР, наборы инструментов и список статей [Ресурсы]
Извлечение знаний в сценариях с низким уровнем ресурсов: обзор и перспективы [обзор][список статей]
Сопутствующий набор инструментов :
Doccano、MarkTool、LabelStudio: наборы инструментов для аннотаций данных
LambdaKG: библиотека и тест для встраивания KG на основе PLM.
EasyInstruct: простая в использовании платформа для обучения моделям большого языка.
Пожалуйста, цитируйте нашу статью, если вы используете DeepKE в своей работе.
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}Ниню Чжан, Хаофэнь Ван, Фэй Хуан, Фейю Сюн, Лянькуань Тао, Синь Сюй, Хунхао Гуй, Чжэньру Чжан, Чуаньци Тан, Цян Чен, Сяохань Ван, Зекун Си, Синьжун Ли, Хайян Юй, Хунбинь Е, Шуофэй Цяо, Пэн Ван , Юци Чжу, Синь Се, Сян Чен, Чжоубо Ли, Лэй Ли, Сяочжуань Лян, Юньчжи Яо, Цзин Чен, Юци Чжу, Шумин Дэн, Вэнь Чжан, Гочжоу Чжэн, Хуацзюнь Чен
Участники сообщества: thredreams, eltociear, Цзывэнь Сюй, Руй Хуан, Сяолун Венг


