
Сюань Цзюй 1* , Имин Гао 1* , Чжаоян Чжан 1*# , Цзыян Юань 1 , Синьтао Ван 1 , Больной Цзэн, Юй Сюн, Цян Сюй, Инь Шань 1
1 Лаборатория ARC, Tencent PCG 2 Китайский университет Гонконга * Равный вклад # Руководитель проекта
Наборы видеоданных играют решающую роль в создании видео, таких как Sora. Однако существующие наборы данных текстового видео часто не справляются с обработкой длинных видеопоследовательностей и захватом переходов между кадрами . Чтобы устранить эти ограничения, мы представляем MiraData — набор видеоданных, разработанный специально для задач создания длинных видео. Кроме того, чтобы лучше оценивать временную согласованность и интенсивность движения при создании видео, мы представляем MiraBench , который расширяет существующие тесты за счет добавления 3D-согласованности и показателей силы движения на основе отслеживания. Более подробную информацию вы можете найти в нашей исследовательской статье.
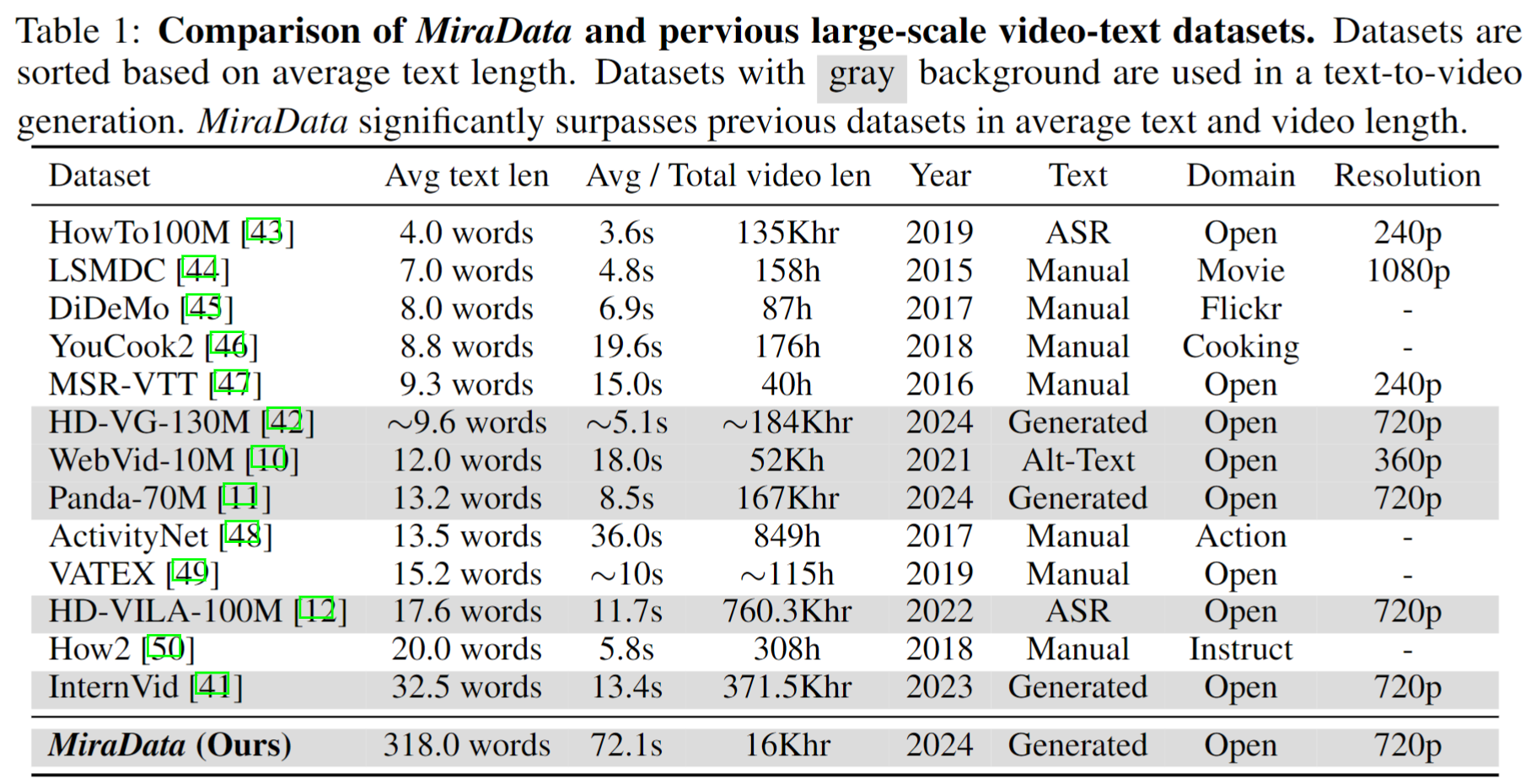
Мы выпускаем четыре версии MiraData, содержащие данные 330K, 93K, 42K, 9K.
Метафайл для этой версии MiraData доступен на Google Диске и в наборе данных HuggingFace. Кроме того, чтобы лучше и быстрее понять состав наших метафайлов, мы случайным образом выбираем набор из 100 видеоклипов, доступ к которым можно получить здесь. Метафайл содержит следующую индексную информацию:
{download_id}.{clip_id}Чтобы загрузить видео и разделить их на клипы, начните с загрузки метафайлов с Google Диска или набора данных HuggingFace. Получив метафайлы, вы можете использовать следующие сценарии для загрузки образцов видео:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
Мы удалим образцы видео из нашего набора данных / Github / веб-страницы проекта до тех пор, пока они вам понадобятся. Пожалуйста, свяжитесь с нами для запроса.
Чтобы собрать MiraData, мы сначала вручную выбираем каналы YouTube в различных сценариях и включаем видео с HD-VILA-100M, Videovo, Pixabay и Pexels. Затем все видео в соответствующих каналах загружаются и разделяются с помощью PySceneDetect. Затем мы использовали несколько моделей, чтобы объединить короткие клипы и отфильтровать видео низкого качества. После этого мы отобрали видеоклипы большой продолжительности. Наконец, мы добавили субтитры ко всем видеоклипам, используя GPT-4V.

Каждое видео в MiraData сопровождается структурированными подписями. Эти подписи содержат подробные описания с различных точек зрения, увеличивая богатство набора данных.
Шесть типов подписей
Мы протестировали существующие визуальные методы LLM с открытым исходным кодом и GPT-4V и обнаружили, что подписи GPT-4V демонстрируют лучшую точность и последовательность в семантическом понимании с точки зрения временной последовательности.
Чтобы сбалансировать затраты на аннотации и точность субтитров, мы равномерно выбираем 8 кадров для каждого видео и размещаем их в сетке 2х4 из одного большого изображения. Затем мы используем модель титров Panda-70M, чтобы аннотировать каждое видео заголовком из одного предложения, который служит подсказкой для основного контента, и вводим его в нашу точно настроенную подсказку. Подав точно настроенную подсказку и большое изображение 2x4 в GPT-4V, мы можем эффективно выводить подписи для нескольких размеров всего за один раунд разговора. Конкретное содержимое подсказки можно найти в файле caption_gpt4v.py, и мы приглашаем всех внести свой вклад в создание более высококачественных текстовых и видеоданных. ?
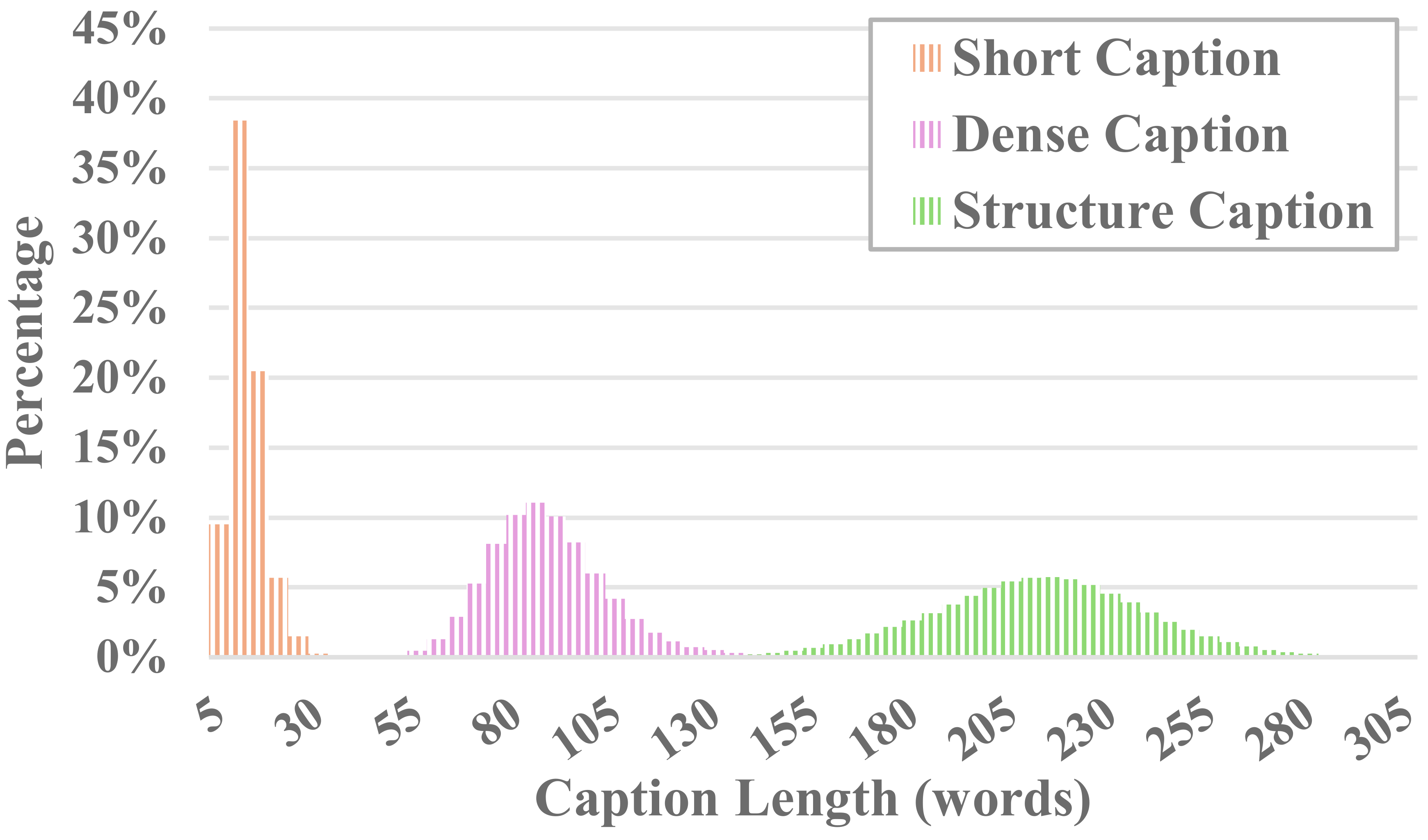

Чтобы оценить создание длинного видео, мы разработали 17 показателей оценки в MiraBench с 6 точек зрения, включая временную согласованность, временную силу движения, согласованность 3D, визуальное качество, выравнивание текста и видео и согласованность распределения. Эти показатели охватывают большинство распространенных стандартов оценки, использовавшихся в предыдущих моделях создания видео и тестах преобразования текста в видео.
Чтобы оценить сгенерированные видео, сначала настройте среду Python с помощью:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
Затем запустите оценку через:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
Вы можете воспользоваться примером в data/evaluation_example , чтобы оценить свои собственные видео.
Пожалуйста, ознакомьтесь с ЛИЦЕНЗИЕЙ.
Если вы найдете этот проект полезным для вашего исследования, пожалуйста, процитируйте нашу статью. ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
По любым вопросам пишите на [email protected] .
MiraData находится под лицензией GPL-v3 и поддерживается для коммерческого использования. Если вам нужна коммерческая лицензия для MiraData, свяжитесь с нами.


