storm
v1.0.0 & EMNLP 2024 Paper Accepted!
| Предварительный просмотр исследования | ШТОРМ Бумага | Бумага Co-STORM | Веб-сайт |
Последние новости
[2024/09] Кодовая база Co-STORM теперь выпущена и интегрирована в пакет Python knowledge-storm v1.0.0. Запустите pip install knowledge-storm --upgrade чтобы проверить это.
[2024/09] Мы представляем совместную STORM (Co-STORM) для поддержки совместного курирования знаний человека и искусственного интеллекта! Документ Co-STORM был принят на основную конференцию EMNLP 2024.
[2024/07] Теперь вы можете установить наш пакет с помощью pip install knowledge-storm !
[2024/07] Мы добавляем VectorRM для поддержки работы с документами, предоставленными пользователями, дополняя существующую поддержку поисковых систем ( YouRM , BingSearch ). (проверьте № 58)
[2024/07] Мы выпускаем демонстрационную версию для разработчиков с минимальным пользовательским интерфейсом, созданным с использованием фреймворкаstreamlit на Python, удобным для локальной разработки и хостинга демо (оформление заказа № 54).
[2024/06] Мы представим STORM на NAACL 2024! Найдите нас на стендовой сессии 2 17 июня или ознакомьтесь с нашими презентационными материалами.
[2024/05] Мы добавляем поддержку поиска Bing в rm.py. Протестируйте STORM с GPT-4o — теперь мы настраиваем часть генерации статей в нашей демонстрации, используя модель GPT-4o .
[2024/04] Мы выпускаем обновленную версию кодовой базы STORM! Мы определяем интерфейс для конвейера STORM и переопределяем STORM-wiki (см. src/storm_wiki ), чтобы продемонстрировать, как создать экземпляр конвейера. Мы предоставляем API для поддержки настройки различных языковых моделей и интеграции поиска/поиска.
Хотя система не может создавать готовые к публикации статьи, которые часто требуют значительного количества правок, опытные редакторы Википедии нашли ее полезной на этапе предварительного написания.
Более 70 000 человек попробовали нашу предварительную версию исследования в реальном времени. Попробуйте ее, чтобы увидеть, как STORM может помочь вам в исследовании знаний, и, пожалуйста, оставьте отзыв, чтобы помочь нам улучшить систему!
STORM разбивает создание длинных статей с цитатами на два этапа:
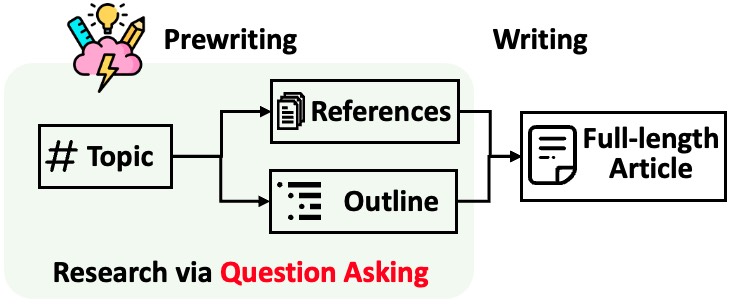
STORM определяет основу автоматизации исследовательского процесса как автоматическое создание хороших вопросов, которые следует задавать. Прямое побуждение языковой модели задавать вопросы не работает. Чтобы улучшить глубину и широту вопросов, STORM использует две стратегии:
Co-STORM предлагает протокол совместного обсуждения , который реализует политику управления очередью для поддержки бесперебойного сотрудничества между
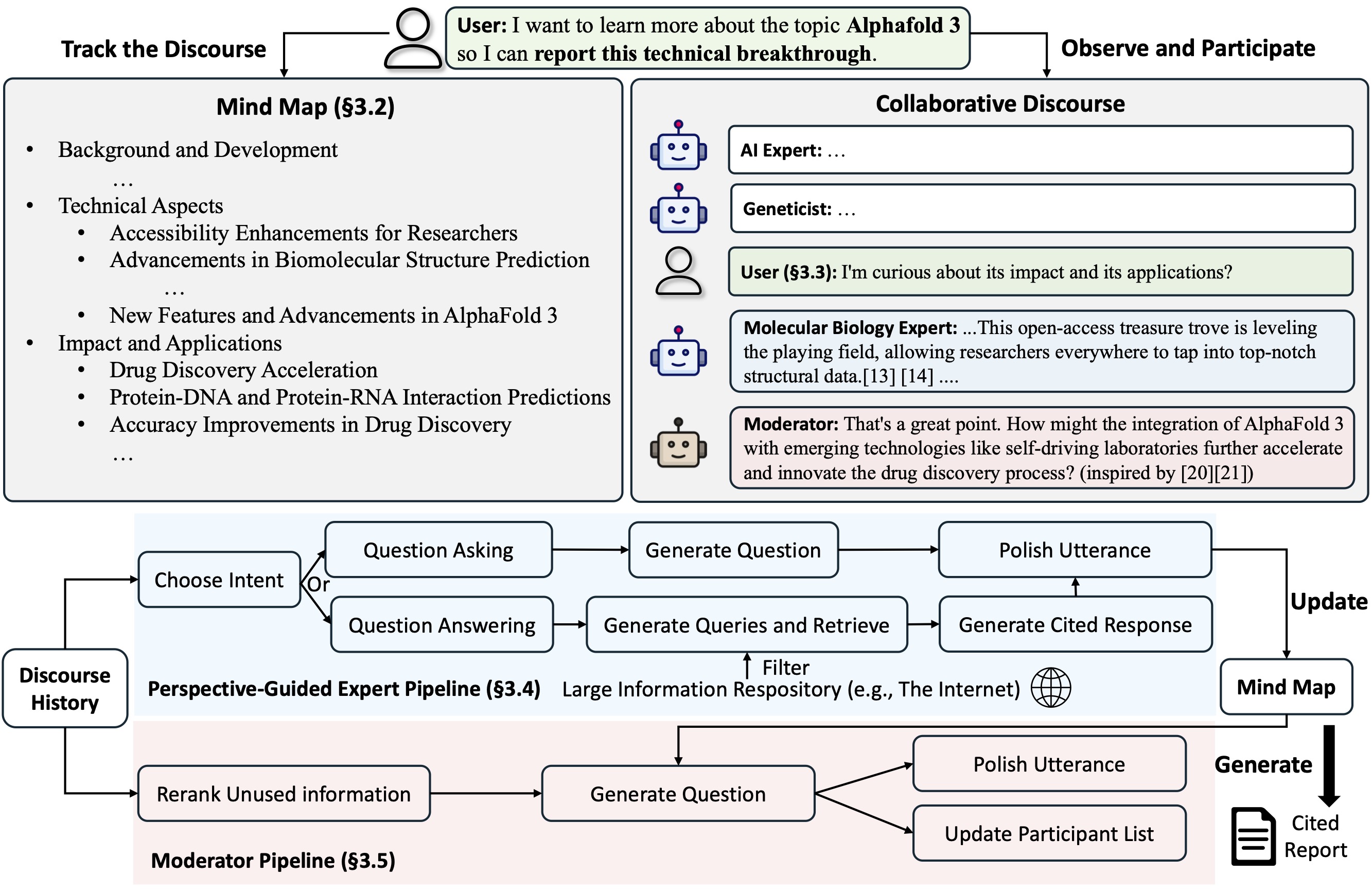
Co-STORM также поддерживает динамическую обновляемую интеллектуальную карту , которая организует собранную информацию в иерархическую концептуальную структуру с целью создания общего концептуального пространства между пользователем-человеком и системой . Доказано, что интеллект-карта помогает снизить умственную нагрузку, когда дискурс идет длинный и глубокий.
И STORM, и Co-STORM реализованы модульным способом с использованием dspy.
Чтобы установить библиотеку Knowledge Storm, используйте pip install knowledge-storm .
Вы также можете установить исходный код, который позволит вам напрямую изменять поведение движка STORM.
Клонируйте репозиторий git.
git clone https://github.com/stanford-oval/storm.git
cd stormУстановите необходимые пакеты.
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txtНа данный момент наш пакет поддерживает:
OpenAIModel , AzureOpenAIModel , ClaudeModel , VLLMClient , TGIClient , TogetherClient , OllamaClient , GoogleModel , DeepSeekModel , GroqModel как компоненты языковой моделиYouRM , BingSearch , VectorRM , SerperRM , BraveRM , SearXNG , DuckDuckGoSearchRM , TavilySearchRM , GoogleSearch и AzureAISearch в качестве компонентов модуля поиска.? Приветствуются PR за интеграцию большего количества языковых моделей в Knowledge_storm/lm.py и поисковых систем/рекреаторов в Knowledge_storm/rm.py!
И STORM, и Co-STORM работают на уровне курирования информации, вам необходимо настроить модуль поиска информации и модуль языковой модели для создания их классов Runner соответственно.
Механизм курирования знаний STORM определяется как простой класс Python STORMWikiRunner . Вот пример использования поисковой системы You.com и моделей OpenAI.
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) Экземпляр STORMWikiRunner можно вызвать с помощью простого метода run :
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : если True, имитировать разговоры с разными точками зрения для сбора информации по теме; в противном случае загрузите результаты.do_generate_outline : если True, создать структуру темы; в противном случае загрузите результаты.do_generate_article : если True, создать статью по теме на основе схемы и собранной информации; в противном случае загрузите результаты.do_polish_article : если True, доработать статью, добавив раздел резюмирования и (необязательно) удалив повторяющийся контент; в противном случае загрузите результаты. Механизм курирования знаний Co-STORM определяется как простой класс Python CoStormRunner . Вот пример использования поисковой системы Bing и моделей OpenAI.
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) Экземпляр CoStormRunner можно вызвать с помощью методов warmstart() и step(...) .
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )Мы предоставляем сценарии в нашей папке примеров для быстрого запуска STORM и Co-STORM с различными конфигурациями.
Мы предлагаем использовать secrets.toml для настройки ключей API. Создайте файл secrets.toml в корневом каталоге и добавьте следующее содержимое:
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " Чтобы запустить STORM с моделями семейства gpt с конфигурациями по умолчанию:
Выполните следующую команду.
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articleЧтобы запустить STORM, используя ваши любимые языковые модели или опираясь на собственный корпус: ознакомьтесь с example/storm_examples/README.md.
Чтобы запустить Co-STORM с моделями семейства gpt с конфигурациями по умолчанию,
BING_SEARCH_API_KEY="xxx" и ENCODER_API_TYPE="xxx" в secrets.tomlpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingЕсли вы установили исходный код, вы можете настроить STORM в соответствии с вашим собственным вариантом использования. Двигатель STORM состоит из 4 модулей:
Интерфейс для каждого модуля определен в knowledge_storm/interface.py , а их реализации создаются в knowledge_storm/storm_wiki/modules/* . Эти модули можно настроить в соответствии с вашими конкретными требованиями (например, создавать разделы в формате маркированного списка вместо полных абзацев).
Если вы установили исходный код, вы можете настроить Co-STORM в соответствии с вашим собственным вариантом использования.
knowledge_storm/interface.py , а его реализация создается в knowledge_storm/collaborative_storm/modules/co_storm_agents.py . Можно настроить различные политики агентов LLM.DiscourseManager в knowledge_storm/collaborative_storm/engine.py . Его можно настраивать и улучшать. Чтобы облегчить изучение автоматического хранения знаний и сложного поиска информации, наш проект выпускает следующие наборы данных:
Набор данных FreshWiki представляет собой коллекцию из 100 высококачественных статей Википедии, посвященных наиболее редактируемым страницам с февраля 2022 года по сентябрь 2023 года. Более подробную информацию см. в разделе 2.1 документа STORM.
Вы можете загрузить набор данных напрямую с сайта Huggingface. Чтобы облегчить проблему загрязнения данных, мы архивируем исходный код конвейера построения данных, который можно повторить в будущем.
Чтобы изучить интересы пользователей в сложных задачах поиска информации в дикой природе, мы использовали данные, собранные в ходе предварительного просмотра веб-исследований, для создания набора данных WildSeek. Мы сократили выборку данных, чтобы обеспечить разнообразие тем и качество данных. Каждая точка данных представляет собой пару, состоящую из темы и цели пользователя для проведения глубокого поиска по этой теме. Для получения более подробной информации обратитесь к разделу 2.2 и приложению A документа Co-STORM.
Набор данных WildSeek доступен здесь.
Для бумажных экспериментов STORM переключитесь на ветку NAACL-2024-code-backup здесь.
Для бумажных экспериментов Co-STORM переключитесь на ветку EMNLP-2024-code-backup (заполнитель на данный момент, скоро будет обновлен).
Наша команда активно работает над:
Если у вас есть какие-либо вопросы или предложения, пожалуйста, не стесняйтесь открыть проблему или запросить извлечение. Мы приветствуем вклад в улучшение системы и кодовой базы!
Контактное лицо: Ицзя Шао и Юйчэн Цзян
Мы хотели бы поблагодарить Википедию за отличный контент с открытым исходным кодом. Набор данных FreshWiki взят из Википедии и доступен по лицензии Creative Commons Attribution-ShareAlike (CC BY-SA).
Мы очень благодарны Мишель Лам за разработку логотипа для этого проекта и Декуну Ма за руководство разработкой пользовательского интерфейса.
Пожалуйста, цитируйте нашу статью, если вы используете этот код или его часть в своей работе:
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

