bulk
1.0.0
Bulk — это быстрый инструмент разработчика, позволяющий применять массовые метки. Учитывая подготовленный набор данных с 2D-вложениями, он может создать интерфейс, который позволяет быстро добавлять объемные, хотя и менее точные, аннотации.
python -m pip install --upgrade pip
python -m pip install bulk
Будущее массового бизнеса – это виджеты, которые могут помочь вам в записной книжке. На данный момент BaseTextExplorer является основным поддерживаемым виджетом. Имея некоторые предварительно обработанные данные, вы можете использовать проводник для просмотра 2D UMAP вложений текста.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]Чтобы использовать виджет, вам просто нужно запустить это:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()Это позволит нам быстро исследовать кластеры, которые появляются в наших данных. Вы можете удерживать курсор мыши, чтобы перейти в режим выбора, и когда вы выбираете элементы, справа вы увидите случайное подмножество. Вы можете выполнить повторную выборку из вашего выбора, нажав кнопку повторной выборки.
Когда вы делаете выбор, вы можете увидеть виджет в правильном обновлении, но вы также можете получить данные из атрибута Python.
widget . selected_idx
widget . selected_texts
widget . selected_dataframeВозможность исследовать эти кластеры — это здорово, но кажется, что нам было бы легче исследовать все, если бы в нашем распоряжении было еще несколько инструментов. В частности, мы хотим иметь кодировщик, чтобы мы могли использовать запросы во встроенном пространстве. Приведенный ниже пользовательский интерфейс позволит нам исследовать гораздо более интерактивно, обновляя цвета с помощью текстовой подсказки.
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()Благодаря таким инструментам, как ipywidget и Anywidget, мы действительно можем начать создавать некоторые инструменты, которые сделают блокнот идеальным местом для хранения ваших данных. Если у вас есть правильные виджеты, вы никогда не сможете превзойти блокнот Jupyter!
Основной интерес этого проекта — работа над инструментами для обеспечения качества данных. Возможность массового выбора точек данных кажется отличным началом. Возможно, вам удастся сначала найти интересное подмножество для аннотирования, возможно, вы удивитесь, когда увидите два разных кластера, которые должны быть одним. Все эти хорошие вещи могут произойти в блокноте!
Bulk также поставляется с небольшим веб-приложением, которое использует Bokeh для предоставления вам интерфейсов аннотаций на основе представлений вложений UMAP. Он предлагает интерфейс для текста. Этот интерфейс был исходным интерфейсом/функцией этого проекта.
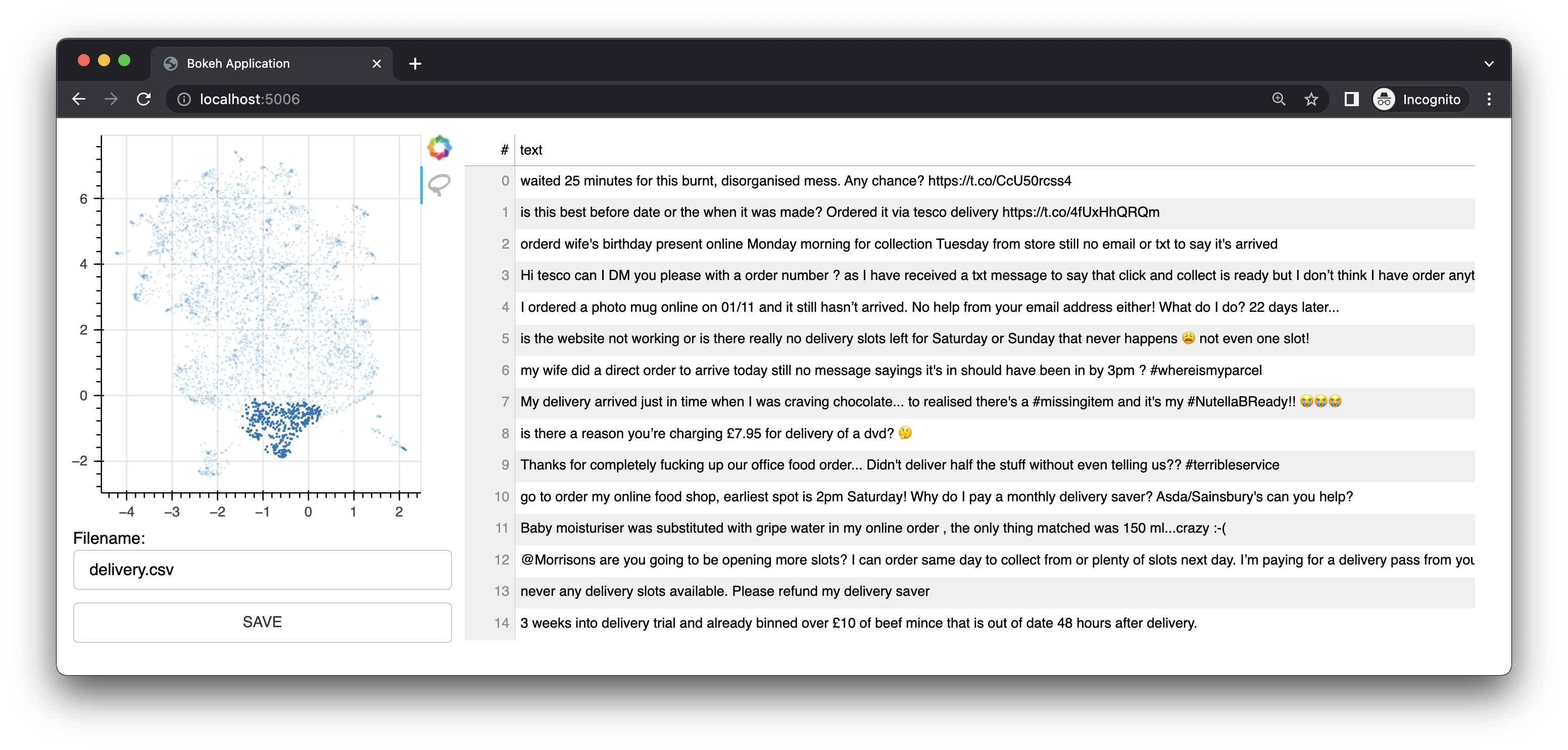
Он также имеет графический интерфейс.
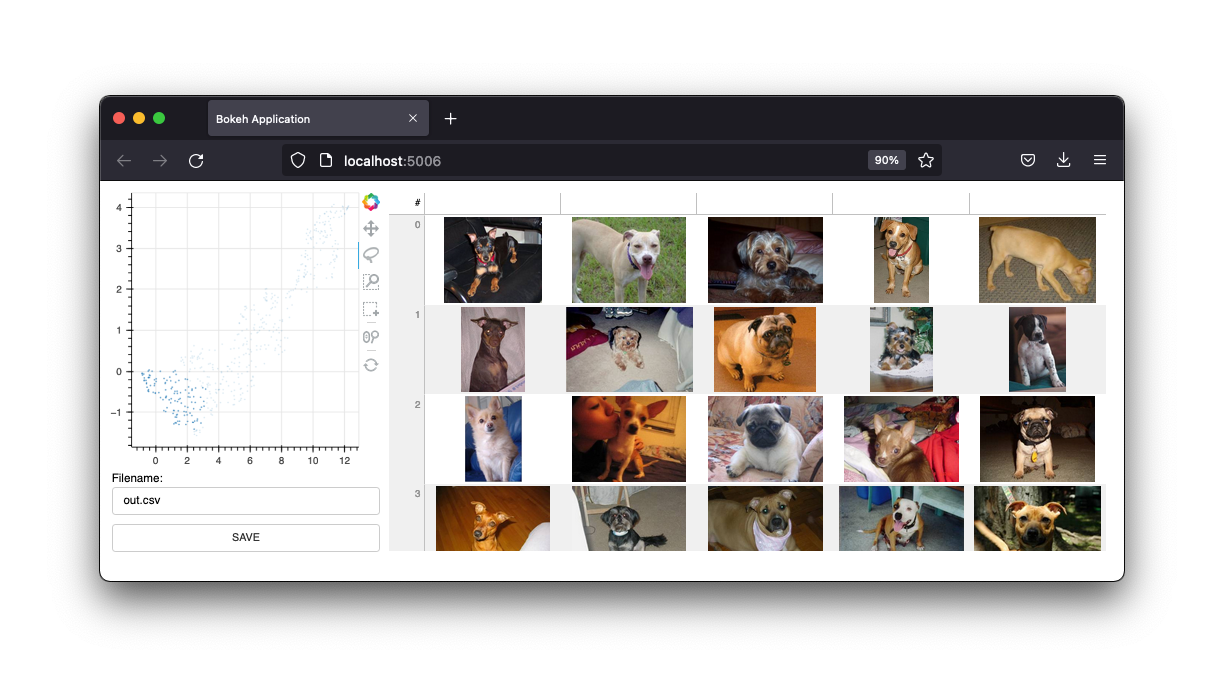
Мы сохраним эти интерфейсы, но будущее этого проекта — это виджеты из блокнота Jupyter. Однако веб-приложение, безусловно, по-прежнему полезно.
Если вам интересно узнать больше, вы можете оценить это видео на YouTube для текста и это видео на YouTube для компьютерного зрения.
Чтобы использовать объемный текст для текста, сначала необходимо подготовить файл CSV.
Примечание
В приведенном ниже примере используется embetter для создания вложений и umap для уменьшения размеров. Но вы можете совершенно свободно использовать любой инструмент для встраивания текста, который вам нравится. Вам нужно будет установить эти инструменты отдельно. Обратите внимание, что embetter использует преобразователи предложений под капотом.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) Теперь вы можете использовать этот ready.csv файл CSV для нанесения массовой маркировки.
python -m bulk text ready.csv
Если вы ищете файл примера для эксперимента, вы можете загрузить демонстрационный файл .csv из этого репозитория. Этот набор данных содержит подмножество набора данных, найденного на Kaggle. Оригинал вы можете найти здесь.
Вы также можете передать в CSV-файл дополнительный столбец под названием «цвет». Этот столбец затем будет использоваться для раскрашивания точек в интерфейсе.
Вы также можете передать --keywords в приложение командной строки, чтобы выделить элементы, содержащие определенные ключевые слова.
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
В приведенном ниже примере используется библиотека embetter для создания набора данных для изображений с массовой маркировкой.
Примечание
В приведенном ниже примере используется embetter для создания вложений и umap для уменьшения размеров. Но вы можете совершенно свободно использовать любой инструмент для встраивания текста, который вам нравится. Вам нужно будет установить эти инструменты отдельно. Обратите внимание, что embetter использует под капотом TIMM.
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )При этом создается файл csv, который можно загрузить массово через;
python -m bulk image ready.csv
Вы также можете создать набор миниатюр для ваших изображений. Это может быть полезно, если вы работаете с большим набором данных.
python -m bulk util resize ready.csv ready2.csv temp
Это создаст папку temp со всеми изображениями с измененным размером. Затем вы можете использовать эту папку в качестве аргумента --thumbnail-path .
python -m bulk image ready2.csv --thumbnail-path temp
Вы также можете использовать массовую загрузку некоторых наборов данных для игры. Для получения дополнительной информации:
python -m bulk download --help
Интерфейс может помочь вам разметить очень быстро, но сами надписи могут быть довольно шумными. Предполагаемый вариант использования этого инструмента — подготовка интересных подмножеств для последующего использования в prodi.gy.


