MedCalc Bench
1.0.0
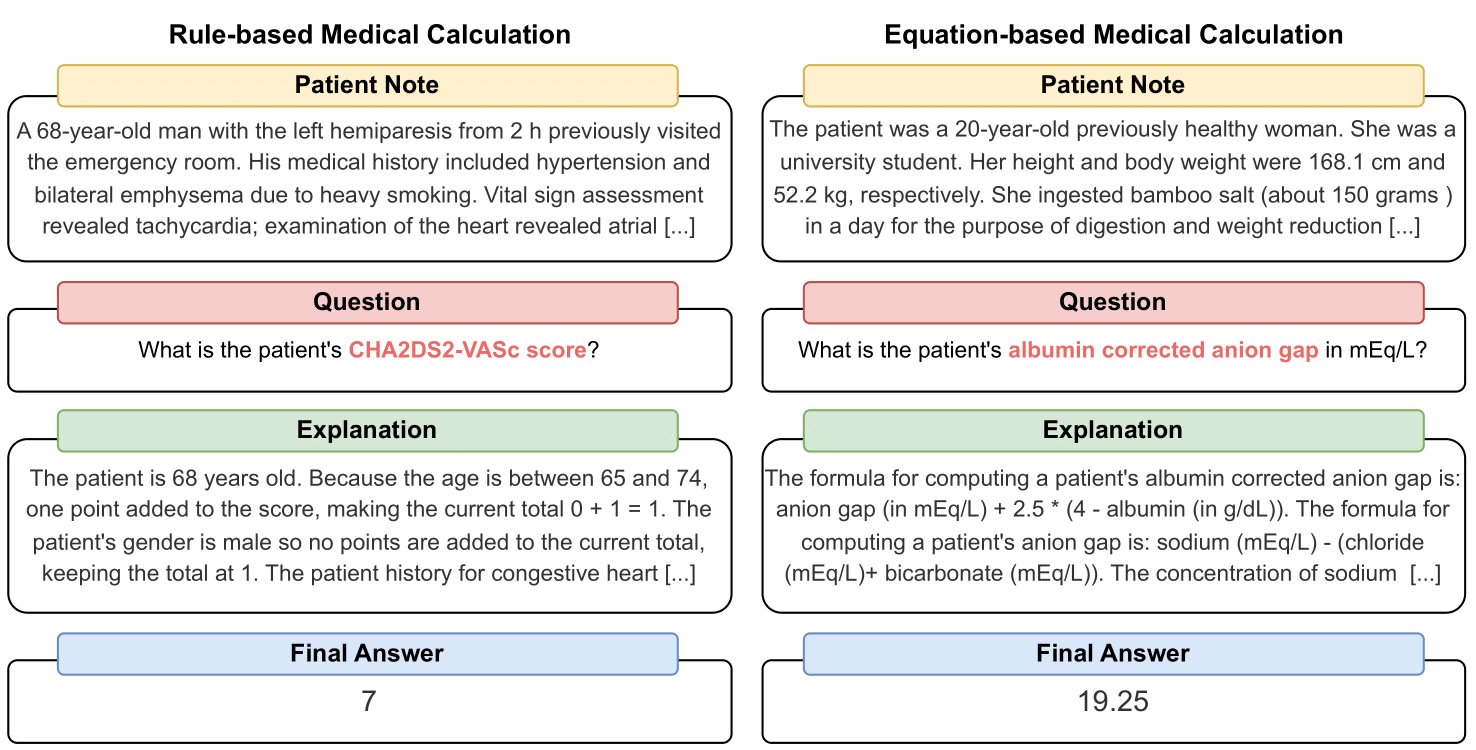
MedCalc-Bench — это первый набор данных для медицинских расчетов, используемый для оценки способности студентов, имеющих степень магистра права, выполнять функции клинических калькуляторов. Каждый экземпляр в наборе данных состоит из записи пациента, вопроса, в котором предлагается вычислить конкретное клиническое значение, окончательного значения ответа и пошагового решения, объясняющего, как был получен окончательный ответ. Наш набор данных охватывает 55 различных вычислительных задач, которые представляют собой расчеты на основе правил или расчеты на основе уравнений. Этот набор данных содержит набор обучающих данных из 10 053 экземпляров и набор тестовых данных из 1047 экземпляров.
В целом мы надеемся, что наш набор данных и тест послужат призывом к улучшению навыков вычислительного мышления у студентов-магистров в медицинских учреждениях.
Наш препринт доступен по адресу: https://arxiv.org/abs/2406.12036.
Чтобы загрузить CSV-файл для набора оценочных данных MedCalc-Bench, загрузите файл test_data.csv в папке dataset этого репозитория. Вы также можете загрузить разделенный набор тестов с сайта HuggingFace по адресу https://huggingface.co/datasets/ncbi/MedCalc-Bench.
В дополнение к 1047 оценочным экземплярам мы также предоставляем обучающий набор данных из 10 053 экземпляров, который можно использовать для тонкой настройки LLM с открытым исходным кодом (см. Раздел C Приложения). Данные обучения можно найти в файле dataset/train_data.csv.zip , и их можно разархивировать, чтобы получить train_data.csv . Этот набор обучающих данных также можно найти в разделе поездов ссылки HuggingFace.
Каждый экземпляр в наборе данных содержит следующую информацию:
Чтобы установить все пакеты, необходимые для этого проекта, выполните следующую команду: conda env create -f environment.yml . Эта команда создаст среду conda medcalc-bench . Для запуска моделей OpenAI вам необходимо будет предоставить ключ OpenAI в этой среде conda. Вы можете сделать это, выполнив следующую команду в среде medcalc-bench : export OPENAI_API_KEY = YOUR_API_KEY , где YOUR_API_KEY — ваш ключ API OpenAI. Вам также потребуется предоставить свой токен HuggingFace в этой среде, выполнив следующую команду: export HUGGINGFACE_TOKEN=your_hugging_face_token , где your_hugging_face_token — это ваш токен HuggingFace.
Чтобы воспроизвести Таблицу 2 из статьи, сначала cd в папку evaluation . Затем выполните следующую команду: python run.py --model <model_name> and --prompt <prompt_style> .
Параметры --model приведены ниже:
Параметры --prompt приведены ниже:
В результате вы получите один файл jsonl, выводящий статус каждого вопроса: после выполнения run.py результаты будут сохранены в файле с именем <model>_<prompt>.jsonl . Этот файл можно найти в папке outputs .
С каждым экземпляром в jsonl будут связаны следующие метаданные:
{
"Row Number": Row index of the item,
"Calculator Name": Name of calculation task,
"Calculator ID": ID of the calculator,
"Category": type of calculation (risk, severity, diagnosis for rule-based calculators and lab, risk, physical, date, dosage for equation-based calculators),
"Note ID": ID of the note taken directly from MedCalc-Bench,
"Patient Note": Paragraph which is the patient note taken directly from MedCalc-Bench,
"Question": Question asking for a specific medical value to be computed,
"LLM Answer": Final Answer Value from LLM,
"LLM Explanation": Step-by-Step explanation by LLM,
"Ground Truth Answer": Ground truth answer value,
"Ground Truth Explanation": Step-by-step ground truth explanation,
"Result": "Correct" or "Incorrect"
}
Кроме того, мы предоставляем среднюю точность и процент стандартного отклонения для каждой подкатегории в json-файле с названием results_<model>_<prompt_style>.json . Совокупную точность и стандартное отклонение для всех 1047 экземпляров можно найти в разделе «общий» ключ JSON. Этот файл можно найти в папке results .
В дополнение к результатам, приведенным в Таблице 2 в основной статье, мы также предложили LLM написать код для выполнения арифметических действий вместо того, чтобы LLM делал это самостоятельно. Результаты можно найти в Приложении D. Из-за ограниченности вычислений мы проанализировали результаты только для GPT-3.5 и GPT-4. Чтобы просмотреть подсказки и запустить программу с этим параметром, просмотрите generate_code_prompt.py в папке evaluation .
Чтобы запустить этот код, просто cd в папку evaluations и выполните следующую команду: python generate_code_prompt.py --gpt <gpt_model> . Варианты <gpt_model> — 4 для запуска GPT-4 или 35 для запуска GPT-3.5-turbo-16k. Результаты затем будут сохранены в файле jsonl с именем: code_exec_{model_name}.jsonl в папке outputs . Обратите внимание, что в этом случае model_name будет gpt_4 если вы решили использовать GPT-4. В противном случае model_name будет gpt_35_16k , если вы выбрали работу с GPT-3.5-turbo.
Метаданные для каждого экземпляра в файле jsonl для результатов интерпретатора кода — это та же информация об экземпляре, что и в разделе выше. Единственное отличие состоит в том, что мы храним историю чата LLM между пользователем и помощником и имеем ключ «История чата LLM» вместо ключа «Объяснение LLM». Кроме того, подкатегория и общая точность сохраняются в файле JSON с именем results_<model_name>_code_augmented.json . Этот JSON находится в папке results .
Это исследование было поддержано Программой внутренних исследований NIH Национальной медицинской библиотеки. Кроме того, вклад Сорена Данна был сделан с использованием передовых вычислительных ресурсов и ресурсов данных Delta, которые поддерживаются Национальным научным фондом (награда OAC, тел: 2005572) и штатом Иллинойс. Delta — это совместная работа Университета Иллинойса в Урбане-Шампейне (UIUC) и его Национального центра суперкомпьютерных приложений (NCSA).
Для управления записями пациентов в MedCalc-Bench мы используем только общедоступные записи пациентов из опубликованных статей о клинических случаях в PubMed Central и анонимные истории пациентов, созданные врачами. Таким образом, в этом исследовании не раскрывается никакая идентифицируемая личная информация о здоровье. Хотя MedCalc-Bench предназначен для оценки возможностей медицинских расчетов LLM, следует отметить, что набор данных не предназначен для прямого диагностического использования или принятия медицинских решений без проверки и надзора со стороны клинического специалиста. Люди не должны менять свое поведение в отношении здоровья исключительно на основе нашего исследования.
Как описано в разделе 1, медицинские калькуляторы обычно используются в клинических условиях. В связи с быстро растущим интересом к использованию LLM для приложений, специфичных для конкретной предметной области, практикующие врачи могут напрямую побуждать чат-ботов, таких как ChatGPT, выполнять задачи медицинских расчетов. Однако возможности LLM в решении этих задач на данный момент неизвестны. Поскольку здравоохранение — это сфера с высокими ставками, и неправильные медицинские расчеты могут привести к серьезным последствиям, включая неправильный диагноз, неправильные планы лечения и потенциальный вред пациентам, крайне важно тщательно оценить эффективность LLM в медицинских расчетах. Удивительно, но результаты оценки нашего набора данных MedCalc-Bench показывают, что все изученные LLM испытывают трудности с задачами медицинских расчетов. Самая мощная модель GPT-4 обеспечивает точность только 50 % благодаря однократному обучению и подсказкам по цепочке мыслей. Таким образом, наше исследование показывает, что текущие LLM еще не готовы к использованию для медицинских расчетов. Следует отметить, что, хотя высокие баллы в MedCalc-Bench не гарантируют совершенства в задачах медицинских расчетов, неудача в этом наборе данных указывает на то, что модели вообще не следует рассматривать для таких целей. Другими словами, мы считаем, что прохождение MedCalc-Bench должно быть необходимым (но не достаточным) условием для использования модели в медицинских расчетах.
При любых изменениях в этом наборе данных (например, добавлении новых заметок или калькуляторов) мы обновим инструкции README, test_set.csv и train_set.csv. Мы по-прежнему будем хранить более старые версии этих наборов данных в archive/ папке. Мы также обновим обучающие и тестовые наборы для HuggingFace.
Этот инструмент показывает результаты исследований, проведенных в отделении вычислительной биологии NCBI/NLM. Информация, представленная на этом веб-сайте, не предназначена для прямого диагностического использования или принятия медицинских решений без проверки и контроля со стороны клинического специалиста. Люди не должны менять свое поведение в отношении здоровья исключительно на основе информации, представленной на этом веб-сайте. NIH не проверяет независимо достоверность или полезность информации, полученной с помощью этого инструмента. Если у вас есть вопросы по поводу информации, представленной на этом веб-сайте, обратитесь к врачу. Дополнительную информацию о политике отказа от ответственности NCBI можно найти.
В зависимости от калькулятора наш набор данных состоит из заметок, которые были либо созданы на основе шаблонных функций, реализованных на Python, написанных от руки врачами, либо взяты из нашего набора данных Open-Patients.
Open-Patients — это агрегированный набор данных из 180 тысяч записей пациентов, поступающих из трех разных источников. У нас есть разрешение на использование набора данных из всех трех источников. Первым источником являются вопросы USMLE от MedQA, выпущенные по лицензии MIT. Вторым источником нашего набора данных являются Trec Clinical Decision Support и Trec Clinical Trial, которые доступны для распространения, поскольку оба являются государственными наборами данных и публикуются для общественности. Наконец, PMC-Patients выпускается под лицензией CC-BY-SA 4.0, поэтому у нас есть разрешение включать PMC-Patients в Open-Patients и MedCalc-Bench, но набор данных должен быть выпущен под той же лицензией. Следовательно, наш источник заметок Open-Patients и созданный на его основе набор данных MedCalc-Bench выпускаются под лицензией CC-BY-SA 4.0.
Исходя из обоснования лицензионных правил, как Open-Patients, так и MedCalc-Bench соответствуют лицензии CC-BY-SA 4.0, однако авторы данной статьи несут всю ответственность в случае нарушения прав.
@misc { khandekar2024medcalcbench ,
title = { MedCalc-Bench: Evaluating Large Language Models for Medical Calculations } ,
author = { Nikhil Khandekar and Qiao Jin and Guangzhi Xiong and Soren Dunn and Serina S Applebaum and Zain Anwar and Maame Sarfo-Gyamfi and Conrad W Safranek and Abid A Anwar and Andrew Zhang and Aidan Gilson and Maxwell B Singer and Amisha Dave and Andrew Taylor and Aidong Zhang and Qingyu Chen and Zhiyong Lu } ,
year = { 2024 } ,
eprint = { 2406.12036 } ,
archivePrefix = { arXiv } ,
primaryClass = { id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.' }
}

