CQN
1.0.0
Повторная реализация Q-Network от грубого до мелкого (CQN) , эффективного по выборке алгоритма RL на основе значений для непрерывного управления, представленного в:
Непрерывный контроль с грубым и точным обучением с подкреплением
Ёнгё Со, Джафар Уруч, Стивен Джеймс
Наша ключевая идея — изучить агентов RL, которые масштабируют пространство непрерывных действий от грубого до мелкого, что позволяет нам обучать агентов RL, основанных на ценности, для непрерывного контроля с небольшим количеством дискретных действий на каждом уровне.
Дополнительную информацию можно найти на веб-странице нашего проекта https://youngyo.me/cqn/.
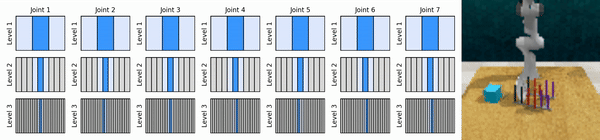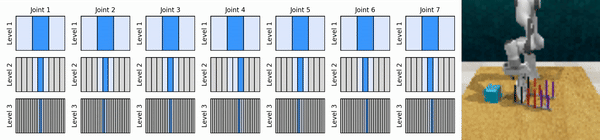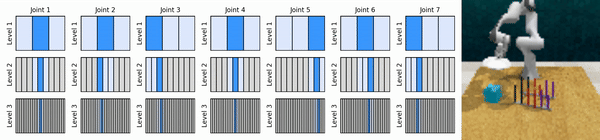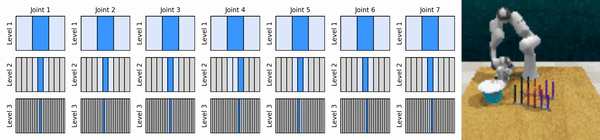
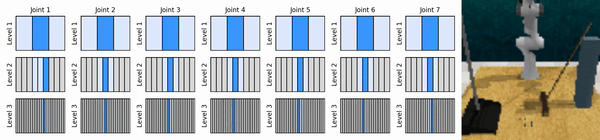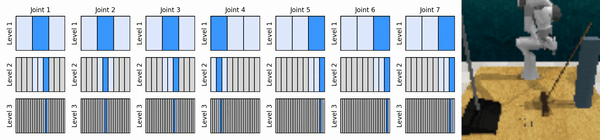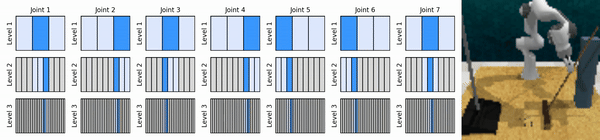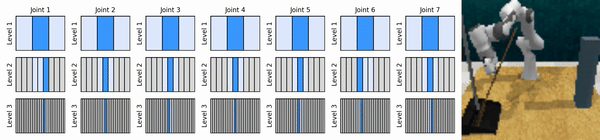
Установите среду conda:
conda env create -f conda_env.yml
conda activate cqn
Установите RLBench и PyRep (должны использоваться последние версии на дату 10 июля 2024 г.). Следуйте инструкциям в исходных репозиториях для (1) установки RLBench и PyRep и (2) включения безгласного режима. (Информацию об установке RLBench см. в разделе README в RLBench & Robobase.)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
Демонстрации предварительного сбора
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
Запуск экспериментов (CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Запустите базовые эксперименты (DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Проведите эксперименты:
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
Предупреждение: CQN не подвергается тщательному тестированию в DMC.
Этот репозиторий основан на общедоступной реализации DrQ-v2.
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


