gpt neox
GPT-NeoX 2.0
В этом репозитории записана библиотека EleutherAI для обучения крупномасштабных языковых моделей на графических процессорах. Наша текущая структура основана на языковой модели NVIDIA Megatron и дополнена методами DeepSpeed, а также некоторыми новыми оптимизациями. Мы стремимся сделать этот репозиторий централизованным и доступным местом для сбора методов обучения крупномасштабных моделей авторегрессионного языка и ускорить исследования в области крупномасштабного обучения. Эта библиотека широко используется в академических, промышленных и государственных лабораториях, в том числе исследователями из Национальной лаборатории Ок-Ридж, CarperAI, Stability AI, Together.ai, Корейского университета, Университета Карнеги-Меллона и Токийского университета и другими. Уникальная среди аналогичных библиотек, GPT-NeoX поддерживает широкий спектр систем и оборудования, включая запуск через Slurm, MPI и IBM Job Step Manager, и масштабно запускалась на AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI и другие.
Если вы не хотите обучать модели с миллиардами параметров с нуля, скорее всего, это неправильная библиотека. Для общих целей вывода мы рекомендуем вместо этого использовать библиотеку transformers Hugging Face, которая поддерживает модели GPT-NeoX.
GPT-NeoX использует многие из тех же функций и технологий, что и популярная библиотека Megatron-DeepSpeed, но с существенно повышенным удобством использования и новыми оптимизациями. Основные функции включают в себя:
[9/9/2024] Теперь мы поддерживаем обучение предпочтениям через DPO, KTO и моделирование вознаграждений.
[9/9/2024] Теперь мы поддерживаем интеграцию с Comet ML, платформой мониторинга машинного обучения.
[21.05.2024] Теперь мы поддерживаем RWKV с конвейерным параллелизмом!. См. PR для RWKV и RWKV+pipeline.
[21.03.2024] Теперь мы поддерживаем смешанный состав экспертов (MoE).
[17.03.2024] Теперь мы поддерживаем графические процессоры AMD MI250X.
[15.03.2024] Теперь мы поддерживаем Mamba с тензорным параллелизмом! Посмотреть PR
[10.08.2023] Теперь мы поддерживаем контрольно-пропускные пункты с помощью AWS S3! Активируйте с помощью опции конфига s3_path (подробнее см. PR)
[20.09.2023] Начиная с #1035, мы прекратили поддержку Flash Attention 0.x и 1.x и перенесли поддержку на Flash Attention 2.x. Мы не считаем, что это вызовет проблемы, но если у вас есть конкретный вариант использования, требующий поддержки старой флэш-памяти с использованием последней версии GPT-NeoX, поднимите проблему.
[10.08.2023] В нашем проекте math-lm реализована экспериментальная поддержка LLaMA 2 и Flash Attention v2, которая будет реализована позднее в этом месяце.
[17.05.2023] После исправления ряда ошибок мы теперь полностью поддерживаем bf16.
[11.04.2023] Мы обновили нашу реализацию Flash Attention, чтобы теперь поддерживать позиционные встраивания Alibi.
[09.03.2023] Мы выпустили GPT-NeoX 2.0.0, обновленную версию, основанную на последней версии DeepSpeed, которая будет регулярно синхронизироваться в дальнейшем.
До 9 марта 2023 г. GPT-NeoX использовал DeepSpeed, основанный на старой версии DeepSpeed (0.3.15). Чтобы перейти на последнюю исходную версию DeepSpeed, предоставив пользователям доступ к старым версиям GPT-NeoX и DeeperSpeed, мы представили две версии для обеих библиотек:
Эта база кода в первую очередь разработана и протестирована для Python 3.8–3.10 и PyTorch 1.8–2.0. Это не строгое требование, могут работать другие версии и комбинации библиотек.
Чтобы установить оставшиеся базовые зависимости, запустите:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometиз корня репозитория.
Предупреждение
Наша кодовая база основана на DeeperSpeed, нашем ответвлении библиотеки DeepSpeed с некоторыми добавленными изменениями. Прежде чем продолжить, мы настоятельно рекомендуем использовать Anaconda, виртуальную машину или какую-либо другую форму изоляции среды. Невыполнение этого требования может привести к поломке других репозиториев, использующих DeepSpeed.
Теперь мы поддерживаем графические процессоры AMD (MI100, MI250X) посредством JIT-компиляции с объединенным ядром. Сплавленные ядра будут собираться и загружаться по мере необходимости. Чтобы избежать ожидания во время запуска задания, вы также можете выполнить следующие действия для предварительной сборки вручную:
python
from megatron . fused_kernels import load
load () Это позволит автоматически адаптировать процесс сборки для разных поставщиков графических процессоров (AMD, NVIDIA) без изменений кода конкретной платформы. Для дальнейшего тестирования объединенных ядер с помощью pytest используйте pytest tests/model/test_fused_kernels.py
Чтобы использовать Flash-Attention, установите дополнительные зависимости в ./requirements/requirements-flashattention.txt и соответствующим образом установите тип внимания в вашей конфигурации (см. конфигурации). Это может обеспечить значительное ускорение по сравнению с обычным использованием определенных архитектур графических процессоров, включая графические процессоры Ampere (например, A100); более подробную информацию смотрите в репозитории.
NeoX и Deep(er)Speed поддерживают обучение на нескольких разных узлах, и у вас есть возможность использовать множество различных средств запуска для управления заданиями на нескольких узлах.
В общем, где-то должен быть «хост-файл», доступный в формате:
node1_ip slots=8
node2_ip slots=8 где первый столбец содержит IP-адрес каждого узла в вашей настройке, а количество слотов — это количество графических процессоров, к которым узел имеет доступ. В вашей конфигурации вы должны указать путь к хост-файлу с помощью "hostfile": "/path/to/hostfile" . В качестве альтернативы путь к хост-файлу может быть указан в переменной среды DLTS_HOSTFILE .
pdsh — это программа запуска по умолчанию, и если вы используете pdsh , все, что вам нужно сделать (кроме проверки того, что pdsh установлен в вашей среде), — это установить {"launcher": "pdsh"} в ваших файлах конфигурации.
Если вы используете MPI, вам необходимо указать библиотеку MPI (DeepSpeed/GPT-NeoX в настоящее время поддерживает mvapich , openmpi , mpich и impi , хотя openmpi является наиболее часто используемым и тестируемым), а также передать флаг deepspeed_mpi в вашем файле конфигурации:
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} Если ваша среда правильно настроена и правильные файлы конфигурации, вы можете использовать deepy.py как обычный скрипт Python и начать (например) задание по обучению с помощью:
python3 deepy.py train.py /path/to/configs/my_model.yml
Использование Slurm может быть немного более сложным. Как и в случае с MPI, вы должны добавить в свою конфигурацию следующее:
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} Если у вас нет доступа по SSH к вычислительным узлам вашего кластера Slurm, вам необходимо добавить {"no_ssh_check": true}
Во многих случаях вышеуказанных параметров запуска по умолчанию недостаточно.
В этих случаях вам нужно будет изменить утилиту запуска нескольких узлов DeepSpeed для поддержки вашего варианта использования. В целом эти улучшения делятся на две категории:
В этом случае вам необходимо добавить новый класс бегуна с несколькими узлами в deepspeed/launcher/multinode_runner.py и предоставить его в качестве параметра конфигурации в GPT-NeoX. Примеры того, как мы это сделали для Summit JSRun, приведены в коммите DeeperSpeed и коммите GPT-NeoX соответственно.
Мы сталкивались со многими случаями, когда нам хотелось изменить команду запуска MPI/Slurm для оптимизации или отладки (например, чтобы изменить привязку процессора Slurm srun или пометить журналы MPI рангом). В этом случае вам необходимо изменить команду запуска класса многоузлового бегуна с помощью его метода get_cmd (например, mpirun_cmd для OpenMPI). Примеры того, как мы это сделали, чтобы предоставить оптимизированные и помеченные рангом команды запуска с использованием Slurm и OpenMPI для кластера Stability, находятся в этой ветке DeeperSpeed.
Как правило, вы не сможете иметь один фиксированный хост-файл, поэтому вам нужен сценарий для его динамического создания при запуске вашего задания. Пример сценария для динамического создания хост-файла с использованием Slurm и 8 графических процессоров на узел:
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID и $SLURM_NODELIST — переменные среды, которые Slurm создаст для вас. Полный список доступных переменных среды Slurm, установленных во время создания задания, см. в документации по пакету.
Затем вы можете создать пакетный скрипт, с помощью которого можно запустить задание GPT-NeoX. Упрощенный пакетный скрипт в кластере на базе Slurm с 8 графическими процессорами на узел будет выглядеть так:
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
Затем вы можете начать тренировочный прогон с помощью sbatch my_sbatch_script.sh
Мы также предоставляем Dockerfile и конфигурацию docker-compose, если вы предпочитаете запускать NeoX в контейнере.
Для запуска контейнера необходимы соответствующие драйверы графического процессора, последняя версия Docker и установленный набор инструментов nvidia-container. Чтобы проверить, хороша ли ваша установка, вы можете использовать их «пример рабочей нагрузки», а именно:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
При условии, что это запустится, вам необходимо экспортировать NEOX_DATA_PATH и NEOX_CHECKPOINT_PATH в вашу среду, чтобы указать каталог данных и каталог для хранения и загрузки контрольных точек:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
А затем из каталога gpt-neox вы можете собрать образ и запустить оболочку в контейнере с
docker compose run gpt-neox bash
После сборки вы сможете сделать это:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
Для длительной работы вам следует запустить
docker compose up -d
чтобы запустить контейнер в отключенном режиме, а затем в отдельном сеансе терминала запустите
docker compose exec gpt-neox bash
Затем вы можете запустить любое задание из контейнера.
Проблемы, возникающие при длительной работе или в автономном режиме, включают:
Если вы предпочитаете запускать готовый образ контейнера из dockerhub, вы можете вместо этого запускать команды docker Compose с помощью -f docker-compose-dockerhub.yml , например:
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
Все функции должны запускаться с помощью deepy.py — оболочки программы запуска deepspeed .
На данный момент мы предлагаем три основные функции:
train.py используется для обучения и точной настройки моделей.eval.py используется для оценки обученной модели с использованием средства оценки языковой модели.generate.py используется для выборки текста из обученной модели.который можно запустить с помощью:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]Например, чтобы запустить обучение, вы можете запустить
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlБолее подробную информацию о каждой точке входа см. в разделах «Обучение и точная настройка», «Выводы» и «Оценка» соответственно.
Параметры GPT-NeoX определяются в файле конфигурации YAML, который передается в программу запуска deepy.py. Мы предоставили несколько примеров файлов .yml в конфигурациях, демонстрирующих разнообразный набор функций и размеров моделей.
Эти файлы обычно полны, но неоптимальны. Например, в зависимости от конкретной конфигурации графического процессора вам может потребоваться изменить некоторые настройки, такие как pipe-parallel-size , model-parallel-size чтобы увеличить или уменьшить степень параллелизации, train_micro_batch_size_per_gpu или gradient-accumulation-steps для изменения размера пакета. связанные настройки или дикт zero_optimization , чтобы изменить способ распараллеливания состояний оптимизатора между рабочими процессами.
Более подробное руководство по доступным функциям и способам их настройки см. в README конфигурации, а документацию по каждому возможному аргументу см. в configs/neox_arguments.md.
GPT-NeoX включает в себя несколько экспертных реализаций для Министерства образования. Чтобы выбрать между ними, укажите moe_type megablocks (по умолчанию) или deepspeed .
Оба основаны на платформе параллелизма DeepSpeed MoE, которая поддерживает параллелизм тензор-эксперт-данные. Оба позволяют переключаться между сбросом токенов и без сброса (по умолчанию, и именно для этого был разработан Megablocks). Скоро появится маршрут Sinkhorn!
Пример базовой полной конфигурации см. в configs/125M-dmoe.yml (для Megablocksless) или configs/125M-moe.yml.
Большинство аргументов конфигурации, связанных с MoE, имеют префикс moe . Некоторые общие параметры конфигурации и их значения по умолчанию:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed можно дополнительно настроить следующим образом:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
Один слой MoE присутствует в каждом слое преобразователя expert_interval , включая первый, то есть всего 12 слоев:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
Эксперты будут находиться на следующих уровнях:
0, 2, 4, 6, 8, 10
По умолчанию мы используем параллелизм экспертных данных, поэтому для экспертной маршрутизации будет использоваться любой доступный тензорный параллелизм ( model_parallel_size ). Например, учитывая следующее:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
При 32 графических процессорах поведение будет выглядеть так:
expert_parallel_size == model_parallel_size . Настройка enable_expert_tensor_parallelism включает параллелизм тензорных экспертных данных (TED). Тогда способ интерпретации вышеизложенного будет следующим:
expert_parallel_size == 1 или model_parallel_size == 1 .Обратите внимание, что DP должен делиться на (MP * EP). Более подробную информацию можно найти в документе TED.
Конвейерный параллелизм пока не поддерживается. Скоро!
Доступно несколько предварительно настроенных наборов данных, включая большинство компонентов из Pile, а также сам набор поездов Pile, для простой токенизации с использованием точки входа prepare_data.py .
Например, чтобы загрузить и токенизировать набор данных enwik8 с помощью токенизатора GPT2, сохранив их в ./data вы можете запустить:
python prepare_data.py -d ./data
или один фрагмент стопки ( pile_subset ) с токенизатором GPT-NeoX-20B (при условии, что он сохранен в ./20B_checkpoints/20B_tokenizer.json ):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
Токенизированные данные будут сохранены в двух файлах: [data-dir]/[dataset-name]/[dataset-name]_text_document.bin и [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . Вам нужно будет добавить префикс, который используется обоими этими файлами, в файл конфигурации обучения в поле data-path . НАПРИМЕР:
" data-path " : " ./data/enwik8/enwik8_text_document " , Чтобы подготовить собственный набор данных для обучения с использованием пользовательских данных, отформатируйте его как один большой файл в формате JSONL, где каждый элемент списка словарей будет отдельным документом. Текст документа должен быть сгруппирован по одному ключу JSON, т.е. "text" . Любые вспомогательные данные, хранящиеся в других полях, использоваться не будут.
Затем обязательно загрузите словарь токенизатора GPT2 и объедините файлы по следующим ссылкам:
Или используйте токенизатор 20B (для которого нужен только один файл Vocab):
(в качестве альтернативы вы можете предоставить любой файл токенизатора, который может быть загружен библиотекой токенизаторов Hugging Face с помощью команды Tokenizer.from_pretrained() )
Теперь вы можете предварительно токенизировать свои данные, используя tools/datasets/preprocess_data.py , аргументы для которых подробно описаны ниже:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
Например:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodЗатем вы запустите обучение со следующими настройками, добавленными в ваш файл конфигурации:
" data-path " : " data/mydataset_text_document " , Обучение запускается с помощью deepy.py — оболочки модуля запуска DeepSpeed, которая запускает один и тот же сценарий параллельно на многих графических процессорах/узлах.
Общая схема использования:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...Вы можете передать произвольное количество конфигураций, которые будут объединены во время выполнения.
Вы также можете при желании передать префикс конфигурации, который будет предполагать, что все ваши конфигурации находятся в одной папке, и добавить этот префикс к их пути.
Например:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml Это приведет к развертыванию сценария train.py на всех узлах с одним процессом на каждый графический процессор. Рабочие узлы и количество графических процессоров указаны в файле /job/hostfile (см. документацию по параметрам) или могут быть просто переданы в качестве аргумента num_gpus , если выполняется установка с одним узлом.
Хотя это не является строго необходимым, мы считаем полезным определить параметры модели в одном файле конфигурации (например, configs/125M.yml ), а параметры пути к данным — в другом (например, configs/local_setup.yml ).
GPT-NeoX-20B — это авторегрессионная языковая модель с 20 миллиардами параметров, обученная на Pile. Технические подробности о GPT-NeoX-20B можно найти в соответствующем документе. Файл конфигурации для этой модели доступен по адресу ./configs/20B.yml и включен в ссылки для загрузки ниже.
Тонкие веса - (без состояний оптимизатора, для вывода или точной настройки, 39 ГБ)
Чтобы загрузить из командной строки в папку с именем 20B_checkpoints , используйте следующую команду:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsПолный вес — (включая состояния оптимизатора, 268 ГБ)
Чтобы загрузить из командной строки в папку с именем 20B_checkpoints , используйте следующую команду:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsАльтернативно веса можно загрузить с помощью BitTorrent-клиента. Торрент-файлы можно скачать здесь: Slim Weights, Full Weights.
Кроме того, на протяжении всего обучения мы сохраняем 150 контрольных точек, по одной на каждые 1000 шагов. Мы работаем над тем, как лучше всего обеспечить их масштабное обслуживание, а пока люди, заинтересованные в работе с частично обученными контрольно-пропускными пунктами, могут написать нам по адресу [email protected], чтобы организовать доступ.
Pythia Scaling Suite — это набор моделей с числом параметров от 70M до 12B, обученных на Pile, предназначенный для содействия исследованиям интерпретируемости и динамики обучения больших языковых моделей. Более подробную информацию о проекте и ссылки на модели можно найти в статье и на GitHub проекта.
Проект «Полиглот» — это попытка обучить мощные предварительно обученные языковые модели, отличные от английского, чтобы сделать эту технологию доступной для исследователей, не являющихся доминирующими центрами машинного обучения. EleutherAI обучила и выпустила модели корейского языка с параметрами 1,3B, 3,8B и 5,8B, крупнейшая из которых превосходит все другие общедоступные языковые модели при решении задач на корейском языке. Более подробную информацию о проекте и ссылки на модели можно найти здесь.
В большинстве случаев мы рекомендуем развертывать модели, обученные с помощью библиотеки GPT-NeoX, через библиотеку Hugging Face Transformers, которая лучше оптимизирована для вывода.
Мы поддерживаем три типа генерации из предварительно обученной модели:
Все три типа генерации текста можно запустить через python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml с соответствующими значениями, установленными в configs/text_generation.yml .
GPT-NeoX поддерживает оценку последующих задач с помощью средства оценки языковой модели.
Чтобы оценить обученную модель в оценочной программе, просто запустите:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn где --eval_tasks — это список задач оценки, за которыми следуют пробелы, например --eval_tasks lambada hellaswag piqa sciq . Подробную информацию обо всех доступных задачах можно найти в репозитории lm-evaluation-harness.
GPT-NeoX сильно оптимизирован только для обучения, а контрольные точки модели GPT-NeoX несовместимы с другими библиотеками глубокого обучения. Чтобы модели можно было легко загружать и предоставлять к ним общий доступ конечным пользователям, а также для дальнейшего экспорта в различные другие платформы, GPT-NeoX поддерживает преобразование контрольных точек в формат Hugging Face Transformers.
Хотя NeoX поддерживает ряд различных архитектурных конфигураций, включая позиционные встраивания AliBi, не все из этих конфигураций четко соответствуют поддерживаемым конфигурациям в Hugging Face Transformers.
NeoX поддерживает экспорт совместимых моделей в следующие архитектуры:
Обучение модели, которая не вписывается ни в одну из этих архитектур Hugging Face Transformers, потребует написания специального кода моделирования для экспортируемой модели.
Чтобы преобразовать контрольную точку библиотеки GPT-NeoX в загружаемый формат Hugging Face, запустите:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}Затем, чтобы загрузить модель в Hugging Face Hub, запустите:
huggingface-cli login
python ./tools/ckpts/upload.pyи введите запрошенную информацию, включая токен пользователя ВЧ-концентратора.
NeoX предоставляет несколько утилит для преобразования предварительно обученной контрольной точки модели в формат, который можно обучать в библиотеке.
В GPT-NeoX можно загрузить следующие модели или семейства моделей:
Мы предоставляем две утилиты для преобразования двух разных форматов контрольных точек в формат, совместимый с GPT-NeoX.
Чтобы преобразовать контрольную точку Llama 1 или Llama 2, распространяемую Meta AI, из исходного формата файла (можно загрузить здесь или здесь) в библиотеку GPT-NeoX, запустите
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
Чтобы преобразовать модель Hugging Face в загружаемую NeoX, запуститеtools tools/ckpts/convert_hf_to_sequential.py . Дополнительные параметры см. в документации в этом файле.
Помимо локального хранения журналов, мы предоставляем встроенную поддержку двух популярных платформ мониторинга экспериментов: Weights & Biases, TensorBoard и Comet.
Weights & Biases для записи наших экспериментов — это платформа мониторинга машинного обучения. Чтобы использовать wandb для мониторинга экспериментов с gpt-neox:
wandb login — ваши пробежки будут автоматически записываться../requirements/requirements-wandb.txt . Пример конфигурации представлен в ./configs/local_setup_wandb.yml .wandb_group позволяет вам назвать группу прогонов, а wandb_team позволяет назначать ваши пробежки учетной записи организации или команды. Пример конфигурации представлен в ./configs/local_setup_wandb.yml . Мы поддерживаем использование TensorBoard через поле tensorboard-dir . Зависимости, необходимые для мониторинга TensorBoard, можно найти и установить из ./requirements/requirements-tensorboard.txt .
Comet — это платформа мониторинга машинного обучения. Чтобы использовать Comet для мониторинга экспериментов с gpt-neox:
comet login или передав export COMET_API_KEY=<your-key-here>comet_ml и все библиотеки зависимостей с помощью pip install -r requirements/requirements-comet.txtuse_comet: True . Вы также можете настроить место регистрации данных с помощью comet_workspace и comet_project . Полный пример конфигурации с включенной Comet представлен в configs/local_setup_comet.yml . Если вам необходимо предоставить хост-файл для использования с программой запуска DeepSpeed на основе MPI, вы можете установить переменную среды DLTS_HOSTFILE , чтобы она указывала на хост-файл.
Мы поддерживаем профилирование с помощью Nsight Systems, PyTorch Profiler и PyTorch Memory Profiling.
Чтобы использовать профилирование Nsight Systems, установите параметры конфигурации profile , profile_step_start и profile_step_stop (см. здесь использование аргументов и здесь пример конфигурации).
Чтобы заполнить метрики nsys, запустите обучение с помощью:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
Сгенерированный выходной файл затем можно просмотреть с помощью графического интерфейса Nsight Systems:
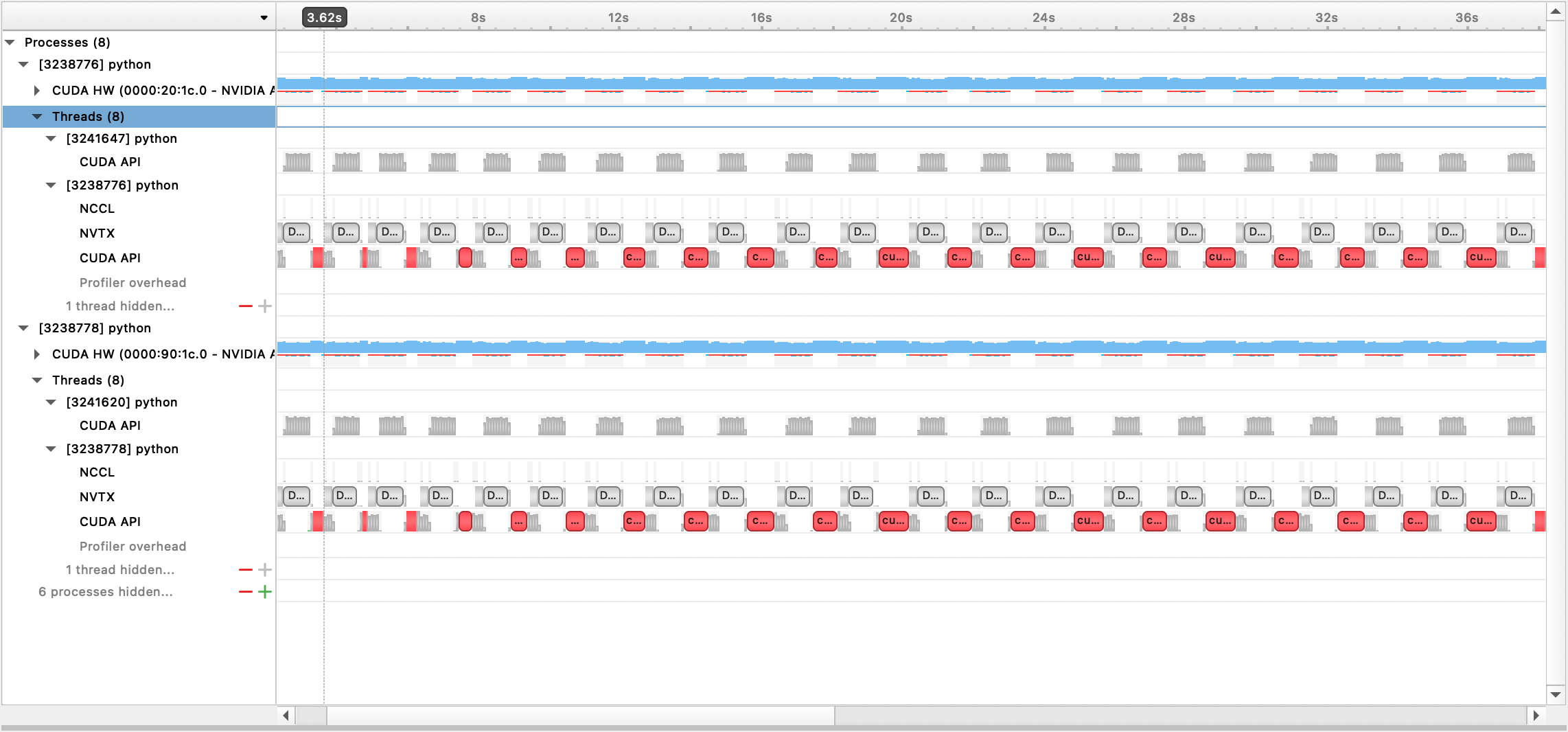
Чтобы использовать встроенный профилировщик PyTorch, установите параметры конфигурации profile , profile_step_start и profile_step_stop (см. здесь использование аргументов и здесь пример конфигурации).
Профилировщик PyTorch сохранит трассировки в каталоге журналов вашей tensorboard . Вы можете просмотреть эти трассировки в TensorBoard, выполнив следующие действия.
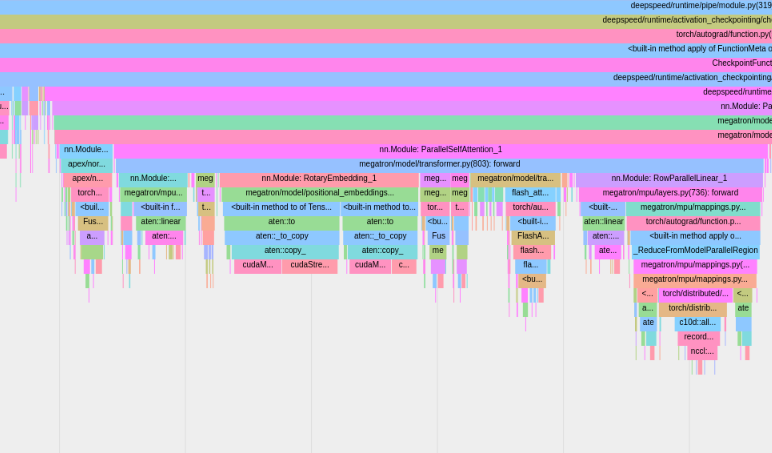
Чтобы использовать профилирование памяти PyTorch, установите параметры конфигурации memory_profiling и memory_profiling_path (см. здесь использование аргументов и здесь пример конфигурации).
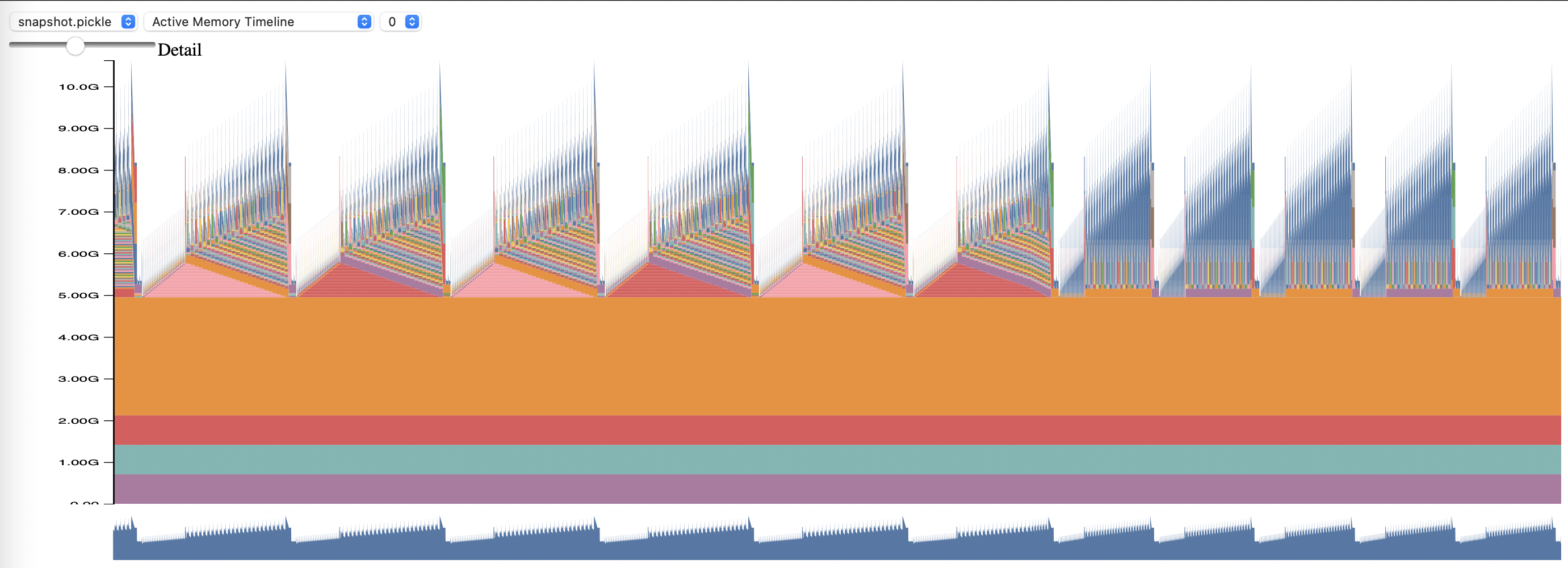
Просмотрите созданный профиль с помощью скрипта Memory_viz.py. Запустить с:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
Библиотека GPT-NeoX была широко принята академическими и отраслевыми исследователями и перенесена на многие системы HPC.
Если вы нашли эту библиотеку полезной в своих исследованиях, свяжитесь с нами и сообщите нам об этом! Мы будем рады добавить вас в наши списки.
EleutherAI и наши сотрудники использовали его в следующих публикациях:
Следующие публикации других исследовательских групп используют эту библиотеку:


