Awesome Attention Heads
vey on LLM attention heads
Важный
Об этом репо. Это платформа, на которой можно получить последние исследования различных видов Attention Heads от LLM. Также мы выпустили опрос на основе этих фантастических произведений.
Если вы хотите процитировать нашу работу , вот наша запись в bibtex: CITATION.bib.
Если вы хотите просмотреть только список соответствующих документов , перейдите прямо сюда.
Если вы хотите внести свой вклад в это репо, перейдите сюда.
С развитием модели большого языка (LLM) тщательно изучается лежащая в ее основе сетевая структура — преобразователь. Исследование структуры Трансформера помогает нам лучше понять этот «черный ящик» и улучшить интерпретируемость модели. В последнее время появляется все больше работ, предполагающих, что модель содержит два отдельных раздела: механизмы внимания, используемые для поведения, умозаключений и анализа, и сети прямой связи (FFN) для хранения знаний. Первое имеет решающее значение для выявления функциональных возможностей модели, что привело к серии исследований, изучающих различные функции механизмов внимания, которые мы назвали «Attention Head Mining» .
В этом обзоре мы углубимся в потенциальные механизмы того, как головы внимания в LLM способствуют процессу рассуждения.
Основные моменты:
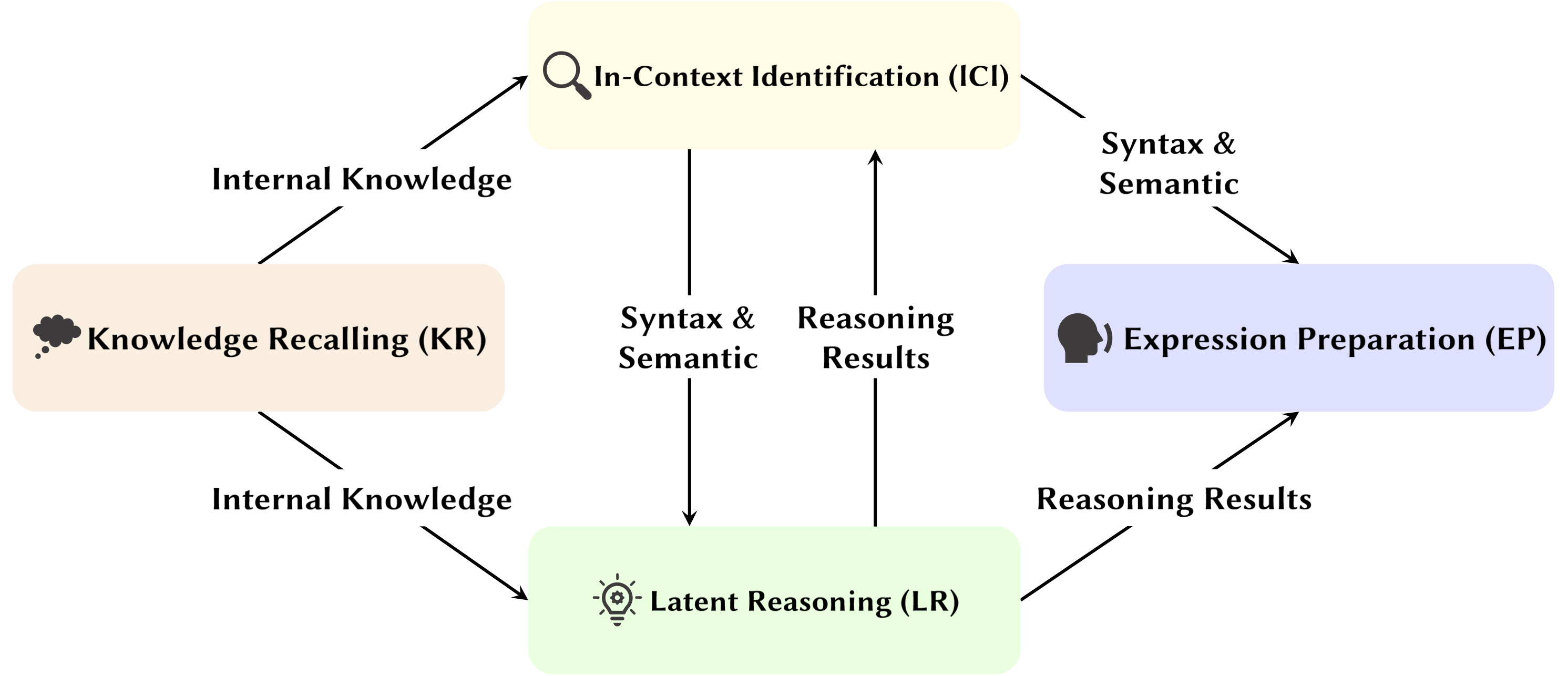
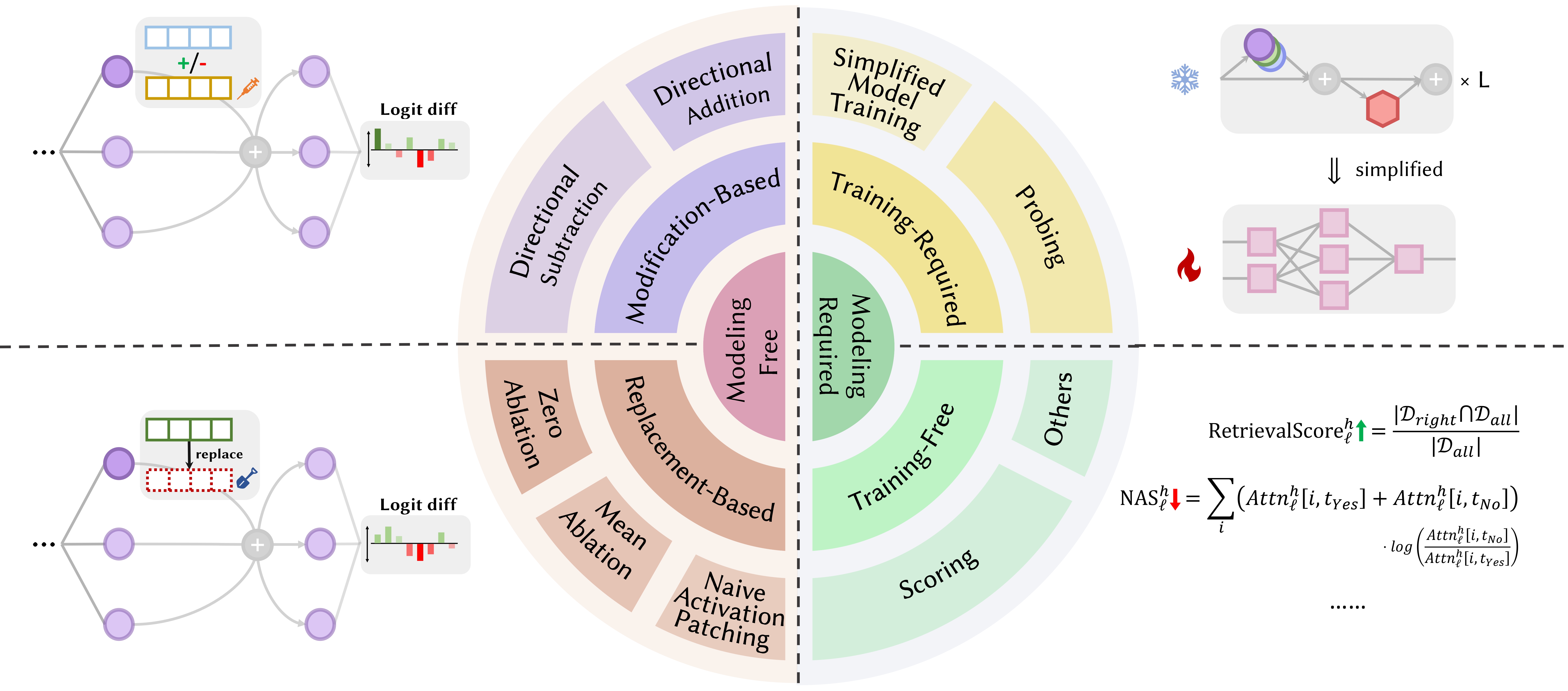
Статьи ниже отсортированы по дате публикации :
2024 год
| Дата | Бумага и резюме | Теги | Ссылки |
| 2024-11-15 | SEEKR: выборочное сохранение знаний, управляемое вниманием, для непрерывного изучения больших языковых моделей | ||
| • Предлагает SEEKR, метод избирательного сохранения знаний, управляемый вниманием, для непрерывного обучения в рамках LLM, фокусируясь на ключевых моментах внимания для эффективной дистилляции. • Оценено по критериям непрерывного обучения TRACE и SuperNI. • SEEKR достиг сопоставимой или лучшей производительности при использовании только 1% повторных данных по сравнению с другими методами. | |||
| 06.11.2024 | Как трансформаторы решают задачи пропозициональной логики: механистический анализ | ||
| • Определяет конкретные схемы внимания в преобразователях, которые решают задачи логики высказываний, уделяя особое внимание механизмам «планирования» и «рассуждения». • Проанализированы небольшие трансформаторы и Мистраль-7Б, используя патчи активации для выявления путей рассуждения. • Обнаружены отдельные главы внимания, специализирующиеся на расположении правил, обработке фактов и принятии решений посредством логических рассуждений. | |||
| 01.11.2024 | Трекер внимания: обнаружение атак с быстрым внедрением в LLM | ||
| • Предлагаемый трекер внимания — простая, но эффективная защита, не требующая обучения, которая обнаруживает атаки с быстрым внедрением на основе идентифицированных важных голов. • Определил важные головы, используя лишь небольшой набор случайных предложений, сгенерированных LLM, в сочетании с наивной атакой игнорирования. • Система отслеживания внимания эффективна как на малых, так и на больших LM, устраняя существенное ограничение предыдущих методов обнаружения, не требующих обучения. | |||
| 2024-10-28 | Арифметика без алгоритмов: языковые модели решают математические задачи с помощью набора эвристик | ||
| • Определил подмножество модели (схему), которая объясняет большую часть поведения модели для базовой арифметической логики, и исследовал ее функциональность. • Проанализированы модели внимания с использованием двухоперандных арифметических подсказок с арабскими цифрами и четырьмя основными операторами (+, −, ×, ÷). • Для сложения, вычитания и деления 6 головок внимания обеспечивают высокую точность (в среднем 97%), тогда как для умножения требуется 20 головок, чтобы точность превышала 90%. | |||
| 2024-10-21 | Психолингвистическая оценка чувствительности языковых моделей к ролям аргумента | ||
| • Наблюдаемая глава субъекта в более обобщенной обстановке. • Проанализированы модели внимания при условии замены аргументов и замены аргументов. • Несмотря на способность различать роли, модели могут с трудом правильно использовать информацию о роли аргумента, поскольку проблема заключается в том, как эта информация кодируется в представлениях глаголов, что приводит к снижению чувствительности к роли. | |||
| 17.10.2024 | Головы с активным и спящим вниманием: механистическое раскрытие феноменов экстремальных токенов в LLM | ||
| • Продемонстрировал, что феномены экстремальных токенов возникают из-за активно-спящего механизма в головах внимания в сочетании с механизмом взаимного подкрепления во время предварительной тренировки. • Использование простых преобразователей, обученных на задаче Biggram-Backcopy (BB), для анализа экстремальных явлений с токенами и распространения их на предварительно обученные LLM. • Многие из статических и динамических свойств экстремальных токенов, предсказанных задачей BB, совпадают с наблюдениями в предварительно обученных LLM. | |||
| 17.10.2024 | О роли заголовков внимания в безопасности модели большого языка | ||
| • Предложил новую метрику, специально разработанную для внимания нескольких руководителей, – Safety Head ImPortant Score (Ships), для оценки вклада отдельных руководителей в модель безопасности. • Проведен анализ функциональности этих головок по обеспечению безопасности, изучены их характеристики и механизмы. • Определенные головки внимания имеют решающее значение для безопасности, головки безопасности перекрываются в точно настроенных моделях, и удаление этих головок минимально влияет на полезность. | |||
| 2024-10-14 | DuoAttention: эффективный долгоконтекстный вывод LLM с поисковыми и потоковыми заголовками | ||
| • Представлен DuoAttention, инфраструктура, которая сокращает как декодирование LLM, так и предварительное заполнение памяти, а также задержку без ущерба для возможностей долгого контекста, на основе обнаружения головок поиска и головок потоковой передачи в LLM. • Проверьте влияние структуры на производительность LLM как в краткосрочных, так и в долгосрочных задачах, а также эффективность ее вывода. • Применяя полный кэш KV только к головкам извлечения, DuoAttention значительно снижает использование памяти и задержку как для декодирования, так и для предварительного заполнения в приложениях с длинным контекстом. | |||
| 2024-10-14 | Обеспечение безопасности точно настроенных программ LLM | ||
| • Представлен SafetyLock, новый и эффективный метод обеспечения безопасности точно настроенных больших языковых моделей при различных уровнях риска и сценариях атак, основанный на обнаружении Safety Heads в LLM. • Оценить эффективность SafetyLock в повышении безопасности модели и эффективности вывода. • Применяя векторы вмешательства к безопасным головкам, SafetyLock может изменить внутренние активации модели в сторону безвредности во время вывода, достигая точного безопасного выравнивания с минимальным влиянием на реакцию. | |||
| 2024-10-11 | Одинаковые, но разные: структурные сходства и различия в многоязычном языковом моделировании | ||
| • Проведено углубленное исследование конкретных компонентов, на которые опираются многоязычные модели при выполнении задач, требующих морфологических процессов, специфичных для языка. • Исследовать функциональные различия внутренних компонентов модели при выполнении задач на английском и китайском языках. • Копирующая голова имеет одинаково высокую частоту активации в обоих языках, тогда как голова прошедшего времени активируется только в английском языке. | |||
| 2024-10-08 | Мы идем по кругу! Чем полезно ротационное позиционное кодирование? | ||
| • Проведен углубленный анализ внутреннего устройства обученной модели Gemma 7B, чтобы понять, как RoPE используется на механическом уровне. • Понял использование различных частот в запросах и ключах. • Обнаружено, что самые высокие частоты в RoPE умело используются Gemma 7B для создания специальных «позиционных» голов внимания (диагональные головы, голова предыдущего токена), в то время как низкие частоты используются головой апострофа. | |||
| 2024-10-06 | Пересмотр схемы вывода контекстного обучения в больших языковых моделях | ||
| • Предложил комплексную трехэтапную схему вывода для характеристики процесса вывода ICL. • Разделите ICL на три этапа: суммирование, объединение семантики и извлечение и копирование функций, анализируя роль, которую каждый этап играет в ICL, и его рабочий механизм. • Обнаружено, что перед индукционными заголовками главы токенов-предшественников сначала объединяют демонстрационные текстовые представления из токена-предшественника в соответствующие им токены меток, выборочно на основе совместимости между семантикой демонстрации и метки. | |||
| 01.10.2024 | Разреженная декомпозиция внимания, применяемая к трассировке цепей | ||
| • Вводит разреженную декомпозицию внимания с использованием SVD на матрицах головы внимания для отслеживания путей связи в моделях GPT-2. • Применяется для трассировки цепей в GPT-2 small для задачи косвенной идентификации объектов (IOI). • Идентифицируются редкие, функционально значимые сигналы связи между головами внимания, что улучшает интерпретируемость. | |||
| 09.09.2024 | Представляем индукционные головки: доказуемая динамика обучения и обучение функциям трансформаторов | ||
| • В документе представлен обобщенный механизм индукционной головки, объясняющий, как компоненты трансформатора взаимодействуют для выполнения контекстного обучения (ICL) на n-граммных цепях Маркова. • Он анализирует преобразователь с двумя уровнями внимания и градиентным потоком для прогнозирования токенов в цепях Маркова. • Градиентный поток сходится, позволяя использовать ICL с помощью изученного механизма индукционной головки, основанного на функциях. | |||
| 2024-08-16 | Механистическая интерпретация силлогистических рассуждений в авторегрессионных языковых моделях | ||
| • Исследование представляет механистическую интерпретацию силлогистических рассуждений в LM, выявляя независимые от содержания схемы рассуждения. • Открытие цепей рассуждений и исследования искажений убеждений в головах внимания. • Идентифицирована необходимая схема рассуждения, которую можно переносить через силлогистические схемы, но которая подвержена загрязнению предварительно подготовленными знаниями о мире. | |||
| 2024-08-01 | Повышение семантической согласованности больших языковых моделей посредством редактирования моделей: подход, ориентированный на интерпретируемость | ||
| • Внедряет экономичный подход к редактированию модели, ориентированный на внимание, для повышения семантической согласованности в LLM без обширных изменений параметров. • Анализировали внимание, вводили предвзятости и тестировали на наборах данных NLU и NLG. • Достигнуто заметное улучшение семантической согласованности и производительности задач, с сильным обобщением для дополнительных задач. | |||
| 2024-07-31 | Исправление негативной предвзятости в больших языковых моделях посредством выравнивания показателей отрицательного внимания | ||
| • Введен показатель отрицательного внимания (NAS) для количественной оценки и исправления негативных ошибок в языковых моделях. • Выявлены головы с негативным предубеждением и предложена система выравнивания показателей негативного внимания (НАСА) для более точной настройки. • НАСА эффективно сократило разрыв в точности воспроизведения, сохранив при этом обобщение в задачах принятия двоичных решений. | |||
| 2024-07-29 | Обнаружение и понимание уязвимостей в языковых моделях посредством механистической интерпретируемости | ||
| • Представляет метод, использующий механистическую интерпретацию (MI) для обнаружения и понимания уязвимостей в LLM, особенно состязательных атак. • Анализирует GPT-2 Small на наличие уязвимостей при прогнозировании трехбуквенных сокращений. • Успешно идентифицирует и объясняет конкретные уязвимости в модели, связанные с задачей. | |||
| 2024-07-22 | RazorAttention: эффективное сжатие KV-кэша с помощью головок извлечения | ||
| • Представлен RazorAttention, метод сжатия KV-кеша, не требующий обучения, с использованием головок поиска и компенсационных токенов для сохранения важной информации о токенах. • Оценена эффективность RazorAttention на больших языковых моделях (LLM). • Достигнуто уменьшение размера кэша KV более чем на 70 % без заметного влияния на производительность. | |||
| 2024-07-21 | Ответ, Собери, Туз: понимание того, как трансформеры отвечают на вопросы с несколькими вариантами ответов | ||
| • В документе представлены проекция словаря и исправление активации для локализации скрытых состояний, которые предсказывают правильные ответы MCQA. • Определены ключевые центры внимания и уровни, отвечающие за выбор ответа в преобразователях. • Головы внимания среднего уровня имеют решающее значение для точного предсказания ответа, поскольку редкий набор голов играет уникальные роли. | |||
| 09.07.2024 | Индукционные головки как важный механизм сопоставления шаблонов в контекстном обучении | ||
| • В статье определены индукционные головки, имеющие решающее значение для сопоставления шаблонов в контекстном обучении (ICL). • Оценил Llama-3-8B и InternLM2-20B по распознаванию абстрактных образов и задачам НЛП. • Абляция индукционных головок снижает производительность ICL примерно на 32%, приближая ее к случайной для распознавания образов. | |||
| 2024-07-02 | Интерпретация арифметического механизма в моделях большого языка посредством сравнительного нейронного анализа | ||
| • Внедряет сравнительный нейронный анализ (CNA) для отображения арифметических механизмов в головках внимания больших языковых моделей. • Анализ арифметических способностей, сокращение моделей для арифметических задач и редактирование моделей для уменьшения гендерной предвзятости. • Идентифицированы конкретные нейроны, отвечающие за арифметику, что позволяет повысить производительность и уменьшить предвзятость за счет целенаправленных манипуляций с нейронами. | |||
| 2024-07-01 | Управление большими языковыми моделями для межъязыкового поиска информации | ||
| • Внедряет многоязычный поиск, управляемый активацией (ASMR), используя активацию управления для управления LLM для улучшения поиска информации на разных языках. • Выявлены центры внимания в LLM, влияющие на точность и связность речи, и применены рулевые активации. • ASMR достигла высочайшего уровня производительности в тестах CLIR, таких как XOR-TyDi QA и MKQA. | |||
| 2024-06-25 | Как трансформеры изучают причинную структуру с помощью градиентного спуска | ||
| • Предоставлено объяснение того, как преобразователи изучают причинные структуры с помощью алгоритмов обучения на основе градиента. • Проанализирована производительность двухслойных преобразователей в задаче, называемой случайными последовательностями с причинной структурой. • Градиентный спуск на упрощенном двухслойном преобразователе учится решать эту задачу путем кодирования скрытого причинного графа в первом слое внимания. В частном случае, когда последовательности генерируются из контекстных цепей Маркова, трансформаторы учатся развивать индукционную головку. | |||
| 2024-06-21 | MoA: смесь разреженного внимания для автоматического сжатия модели большого языка | ||
| • В документе представлена смесь внимания (MoA), которая адаптирует различные конфигурации разреженного внимания для разных голов и слоев, оптимизируя память, пропускную способность и компромисс между точностью и задержкой. • MoA профилирует модели, исследует конфигурации внимания и улучшает сжатие LLM. • MoA увеличивает эффективную длину контекста в 3,9 раза, одновременно сокращая использование памяти графического процессора в 1,2–1,4 раза. | |||
| 2024-06-19 | О сложности верных логических рассуждений в больших языковых моделях | ||
| • Внедрены новые стратегии контекстного обучения, тонкой настройки и редактирования активации для повышения достоверности рассуждений цепочки мыслей (CoT) в LLM. • Протестировали эти стратегии по нескольким критериям, чтобы оценить их эффективность. • Обнаружен лишь ограниченный успех в повышении достоверности CoT, что подчеркивает проблему достижения действительно достоверного рассуждения в LLM. | |||
| 2024-06-04 | Глава итерации: механистическое исследование цепочки мыслей | ||
| • Вводятся «итерационные головки», специализированные головки внимания, которые позволяют преобразователям выполнять итеративные рассуждения для задач цепочки мыслей (CoT). • Анализ механизмов внимания, отслеживание появления ЦТ и тестирование переносимости навыков ЦТ между задачами. • Руководители итераций эффективно поддерживают рассуждения CoT, улучшая интерпретируемость модели и производительность задач. | |||
| 03.06.2024 | LoFiT: локализованная точная настройка представлений LLM | ||
| • Внедряет локализованную точную настройку представлений LLM (LoFiT), двухэтапную структуру для определения важных головок внимания для данной задачи и изучения векторов смещения для конкретной задачи для воздействия на представления идентифицированных головок. • Выявлены редкие наборы важных направлений внимания для повышения точности последующих действий в отношении правдивости и рассуждений. • LoFiT превзошел другие методы вмешательства в представление и достиг производительности, сравнимой с методами PEFT на TruthfulQA, CLUTRR и MQuAKE, несмотря на то, что он вмешался только в 10% общего количества голов внимания в LLM. | |||
| 2024-05-28 | Схемы знаний в предварительно обученных трансформаторах | ||
| • Введены «схемы знаний» в преобразователях, показывающие, как конкретные знания кодируются посредством взаимодействия между головами внимания, головами отношений и MLP. • Проанализированы GPT-2 и TinyLLAMA для выявления цепей знаний; оценены методы редактирования знаний. • Продемонстрировал, как схемы знаний способствуют моделированию такого поведения, как галлюцинации и контекстное обучение. | |||
| 2024-05-23 | Связь контекстного обучения у трансформеров с эпизодической памятью человека | ||
| • Связывает контекстное обучение в моделях Transformer с эпизодической памятью человека, подчеркивая сходство между индукционными головками и моделью контекстного обслуживания и поиска (CMR). • Анализ LLM на основе трансформатора для демонстрации CMR-подобного поведения в головах внимания. • Головы, подобные CMR, появляются в промежуточных слоях, отражая искажения человеческой памяти. | |||
| 07.05.2024 | Как GPT-2 прогнозирует аббревиатуры? Извлечение и понимание схемы посредством механистической интерпретируемости | ||
| • Первое исследование механистической интерпретации GPT-2 для прогнозирования многозначных акронимов с использованием внимания. • Идентифицирован и интерпретирован контур из 8 голов внимания, отвечающих за предсказание акронимов. • Продемонстрировано, что эти 8 голов (~5% от общего числа) концентрируют функции прогнозирования акронимов. | |||
| 2024-05-02 | Интерпретация и улучшение больших языковых моделей в арифметических вычислениях | ||
| • Вводит детальное исследование внутренних механизмов LLM с помощью математических задач, следуя конвейеру «идентификация-анализ-точная настройка». • Проанализирована способность модели выполнять арифметические задачи с двумя операндами, такие как сложение, вычитание, умножение и деление. • Обнаружено, что LLM часто задействует небольшую часть (< 5%) внимания, которое играет ключевую роль в сосредоточении внимания на операндах и операторах во время процессов вычислений. | |||
| 2024-05-02 | Что должно быть правильно для индукционной головки? Механистическое исследование схем контекстного обучения и их формирования | ||
| • Введена основанная на оптогенетике причинно-следственная основа для изучения формирования индукционной головки (IH) в трансформаторах. • Проанализировано возникновение ИГ в трансформаторах с использованием синтетических данных и выявлены три основные подсхемы, ответственные за формирование ИГ. • Обнаружено, что эти подсхемы взаимодействуют, управляя формированием IH, что совпадает с изменением фазы потерь модели. | |||
| 2024-04-24 | Поисковая головка механически объясняет факты в длительном контексте | ||
| • Идентифицированы «головки поиска» в моделях преобразователей, отвечающие за поиск информации в длинных контекстах. • Систематическое исследование поисковых головок в различных моделях, включая анализ их роли в цепочке мыслей. • Обрезка извлекающих головок приводит к галлюцинациям, в то время как обрезка неизвлекательных головок не влияет на способность извлечения информации. | |||
| 2024-03-27 | Вмешательство во время нелинейного вывода: повышение достоверности LLM | ||
| • Введено нелинейное вмешательство по времени вывода (NL-ITI), повышающее достоверность LLM за счет многоточечного зондирования и вмешательства без тонкой настройки. • Оценка NL-ITI на наборах данных с множественным выбором, включая TruthfulQA. • Достигнуто относительное улучшение точности MC1 на TruthfulQA на 16% по сравнению с базовым ITI. | |||
| 2024-02-28 | Как думать шаг за шагом: механистическое понимание цепочки мыслей | ||
| • Предоставил углубленный анализ рассуждений, опосредованных CoT, в LLM с точки зрения нейронных функциональных компонентов. • Рассеченные рассуждения на основе ЦТ о вымышленных рассуждениях как композиции фиксированного числа подзадач, требующих принятия решений, копирования и индуктивного рассуждения, с анализом их механизма по отдельности. • Обнаружено, что головы внимания осуществляют перемещение информации между онтологически связанными (или отрицательно связанными) токенами, что приводит к четко идентифицируемым представлениям для этих пар токенов. | |||
| 2024-02-28 | Отрезание головы прекращает конфликт: механизм интерпретации и смягчения конфликтов знаний в языковых моделях | ||
| • Внедряет метод PH3 для устранения конфликтующих голов внимания, смягчая конфликты знаний в языковых моделях без обновления параметров. • Применил PH3 для контроля зависимости LM от внутренней памяти по сравнению с внешним контекстом и проверил его эффективность на задачах контроля качества в открытой области. • PH3 улучшил использование внутренней памяти на 44,0% и использование внешнего контекста на 38,5%. | |||
| 2024-02-27 | Маршруты информационных потоков: автоматическая интерпретация языковых моделей в любом масштабе | ||
| • Внедряются «маршруты информационных потоков» с использованием атрибуции для интерпретации языковых моделей на основе графов без внесения исправлений активации. • Эксперименты с Ламой 2, определение ключевых направлений внимания и моделей поведения в различных областях и задачах. • Раскрытые специализированные компоненты модели; определили последовательные роли для голов внимания, такие как обращение с токенами одной и той же части речи. | |||
| 20 февраля 2024 г. | Определение голов семантической индукции для понимания контекстного обучения | ||
| • Идентифицирует и изучает «головки семантической индукции» в больших языковых моделях (LLM), которые коррелируют со способностями к контекстному обучению. • Проанализированы головки внимания для кодирования синтаксических зависимостей и связей графа знаний. • Определенные главы внимания улучшают логику вывода, вспоминая соответствующие токены, что имеет решающее значение для понимания контекстного обучения в LLM. | |||
| 2024-02-16 | Эволюция статистических индукционных головок: контекстное обучение цепей Маркова | ||
| • Представляет задачу моделирования последовательностей цепей Маркова для анализа того, как возможности контекстного обучения (ICL) возникают в трансформаторах, образуя «статистические индукционные головки». • Эмпирическое и теоретическое исследование многофазного обучения трансформаторов на задачах цепи Маркова. • Демонстрирует фазовые переходы от предсказаний униграмм к биграммам под влиянием взаимодействия слоев трансформатора. | |||
| 2024-02-11 | Подводя итог фактам: аддитивные механизмы, лежащие в основе воспоминания фактов в LLM | ||
| • Идентифицирует и объясняет «аддитивный мотив» в фактическом вспоминании, когда LLM использует несколько независимых механизмов, которые конструктивно мешают вспомнить факты. • Расширена прямая логит-атрибуция для анализа внимания голов и раскрыто поведение смешанных голов. • Продемонстрировал, что фактический отзыв в LLM является результатом суммы нескольких, независимо друг от друга недостаточных вкладов. | |||
| 05.02.2024 | Как большие языковые модели изучаются в контексте? Матрицы запросов и ключевые матрицы контекстных заголовков — две башни для обучения метрике | ||
| • Представляет концепцию, согласно которой матрицы запросов и ключей в контекстных заголовках работают как «две башни» для обучения метрики, облегчая вычисление сходства между функциями меток. • Проанализированы механизмы контекстного обучения; определили особое внимание, имеющее решающее значение для ICL. • Снижена точность ICL с 87,6% до 24,4% за счет вмешательства только в 1% этих головок. | |||
| 2024-01-23 | Контекстное изучение языка: архитектура и алгоритмы | ||
| • Внедрение «n-граммных головок», специализированных головок преобразователя внимания, улучшающих контекстное изучение языка (ICLL) посредством прогнозирования токенов по условию ввода. • Оцененные нейронные модели на регулярных языках из случайных конечных автоматов. • Головки n-грамм с жестким соединением уменьшили недоумение на 6,7% в наборе данных SlimPajama. | |||
| 16 января 2024 г. | Механистическая основа зависимости данных и резкого обучения в задаче контекстной классификации | ||
| • В статье моделируется механистическая основа контекстного обучения (ICL) посредством резкого формирования индукционных головок в сетях, ориентированных только на внимание. • Моделирование задач ICL с использованием упрощенных входных данных и двухуровневой сети, основанной на внимании. • Формирование индукционной головки приводит к резкому переходу к ICL, прослеживаемому через вложенные нелинейности. | |||
| 16 января 2024 г. | Повторное использование компонентов схемы в разных задачах в языковых моделях Transformer | ||
| • В статье показано, что отдельные схемы в GPT-2 могут применяться к различным задачам, что ставит под сомнение представление о том, что такие схемы ориентированы на конкретные задачи. • В нем рассматривается повторное использование схем из задачи косвенной идентификации объектов (IOI) в задаче «Цветные объекты». • Настройка четырех головок внимания повышает точность задания «Цветные объекты» с 49,6% до 93,7%. | |||
| 16 января 2024 г. | Головы-преемники: повторяющиеся, интерпретируемые головы внимания в дикой природе | ||
| • В документе представлены «заголовки-преемники», заголовки внимания в LLM, которые увеличивают токены в естественном порядке, например днях или числах. • Он анализирует формирование последующих головок в моделях различных размеров и архитектур, таких как GPT-2 и Llama-2. • Головки-преемники встречаются в моделях с числом параметров от 31M до 12B, что демонстрирует абстрактные, повторяющиеся числовые представления. | |||
| 16 января 2024 г. | Векторы функций в больших языковых моделях | ||
| • В статье представлены «векторы функций» (FV) — компактные причинно-следственные представления задач в моделях авторегрессионного преобразователя. • FV были протестированы на различных задачах, моделях и уровнях контекстного обучения (ICL). • FV можно суммировать для создания векторов, запускающих новые, сложные задачи, демонстрируя внутреннюю векторную композицию. | |||
| Дата | Бумага и резюме | Теги | Ссылки |
| 2023-12-23 | Установление фактов: попытка реверс-инжиниринга воспоминания фактов на уровне нейронов | ||
| • Исследовано, как ранние уровни MLP в Pythia 2.8B кодируют фактический отзыв с использованием распределенных схем, уделяя особое внимание суперпозиции и встраиванию нескольких токенов. • Изучил фактический поиск в слоях MLP, проверил гипотезы о механизмах детокенизации и хеширования. • Функция фактического отзыва аналогична распределенной справочной таблице без легко интерпретируемых внутренних механизмов. | |||
| 07.11.2023 | На пути к интерпретируемому продолжению последовательности: анализ общих цепей в моделях большого языка | ||
| • Продемонстрировано существование общих схем для аналогичных задач продолжения последовательности. • Проанализированы и сравнены схемы для аналогичных задач продолжения последовательности, которые включают возрастающие последовательности арабских цифр, числовых слов и месяцев. • Семантически связанные последовательности основаны на подграфах общих схем с аналогичными ролями и нахождении подобных подсхем в моделях с аналогичной функциональностью. | |||
| 2023-10-23 | Линейное представление настроений в больших языковых моделях | ||
| • В документе определяется линейное направление в пространстве активации, которое фиксирует представление настроений в моделях большого языка (LLM). • Они выделили это направление настроений и протестировали его на задачах, включая Stanford Sentiment Treebank. • Устранение этого направления настроений приводит к снижению точности классификации на 76%, что подчеркивает его важность. | |||
| 06.10.2023 | Подавление копирования: всестороннее понимание «головы внимания» | ||
| • В документе представлена концепция подавления копирования в малой головке внимания GPT-2 (L10H7), которая уменьшает количество простого копирования токенов и улучшает калибровку модели. • В статье исследуется и объясняется механизм подавления копирования и его роль в самовосстановлении . • 76,9% воздействия L10H7 в GPT-2 Small объяснено, что делает его наиболее полным описанием роли головы внимания. | |||
| 2023-09-22 | Вмешательство во время вывода: получение правдивых ответов из языковой модели | ||
| • Введено вмешательство во время вывода (ITI) для повышения правдивости LLM за счет корректировки активации модели в выбранных головках внимания. • Улучшена производительность модели LLaMA в тесте TruthfulQA. • ITI увеличила достоверность модели Альпака с 32,5% до 65,1%. | |||
| 2023-09-22 | Рождение трансформера: точка зрения памяти | ||
| • В статье представлен взгляд на преобразователи, основанный на памяти, подчеркивающий ассоциативные воспоминания в весовых матрицах и их градиентное обучение. • Эмпирический анализ динамики обучения на упрощенной модели трансформатора с синтетическими данными. • Открытие быстрого глобального обучения биграмм и более медленное появление «индукционной головки» для контекстных биграмм. | |||
| 2023-09-13 | Внезапное снижение потерь: усвоение синтаксиса, фазовые переходы и смещение простоты в MLM | ||
| • Идентифицирует синтаксическую структуру внимания (SAS) как естественно возникающее свойство в моделях замаскированного языка (MLM) и ее роль в усвоении синтаксиса. • Анализирует SAS во время обучения и манипулирует им, чтобы изучить его причинное влияние на грамматические возможности. • SAS необходим для разработки грамматики, но его кратковременное отключение повышает производительность модели. | |||
| 2023-07-18 | Масштабируется ли интерпретируемость анализа цепей? Данные о возможностях множественного выбора у шиншиллы | ||
| • Масштабируемый анализ цепей, примененный к модели языка шиншиллы 70B для понимания ответов на вопросы с несколькими вариантами ответов. • Логит-атрибуция, визуализация шаблонов внимания и внесение изменений в активацию для выявления и классификации ключевых точек внимания. • В заголовках внимания обнаружена функция «N-й элемент перечисления», хотя это лишь частичное объяснение. | |||
| 2023-02-02 | Интерпретируемость в дикой природе: схема косвенной идентификации объектов в GPT-2 small | ||
| • В статье представлено подробное объяснение того, как GPT-2 small выполняет косвенную идентификацию объекта (IOI) с использованием большой схемы, включающей 28 голов внимания, сгруппированных в 7 классов. • Они провели реверс-инжиниринг задачи IOI в GPT-2 small, используя причинные вмешательства и прогнозы. • Исследование показывает, что механистическая интерпретируемость больших языковых моделей возможна. | |||
| Дата | Бумага и резюме | Теги | Ссылки |
| 08.03.2022 | Руководители контекстного обучения и вводного курса | ||
| • В документе определены «индукционные головки» в моделях Transformer, которые позволяют контекстное обучение путем распознавания и копирования шаблонов в последовательностях. • Анализирует модели внимания и индукционные головы на разных уровнях в разных моделях Трансформеров. • Обнаружено, что индукционные головки имеют решающее значение для того, чтобы трансформаторы могли эффективно обобщать и выполнять задачи контекстного обучения. | |||
| 22 декабря 2021 г. | Математическая основа трансформаторных схем | ||
| • Представляет математическую основу для обратного проектирования небольших преобразователей внимания, уделяя особое внимание пониманию голов внимания как независимых, аддитивных компонентов. • Проанализированы нулевые, одно- и двухслойные преобразователи для выявления роли голов внимания в движении и композиции информации. • Обнаружены «индукционные головки», имеющие решающее значение для контекстного обучения в двухслойных трансформаторах. | |||
| 2021-05-18 | Гипотеза голов: унифицированный статистический подход к пониманию многоголового внимания в BERT | ||
| • В документе предлагается новый метод под названием «Разреженное внимание», который снижает вычислительную сложность механизмов внимания за счет выборочной фокусировки на важных токенах. • Метод оценивался на задачах машинного перевода и классификации текста. • Модель разреженного внимания обеспечивает точность, сравнимую с моделью плотного внимания, при этом значительно снижая вычислительные затраты. | |||
| 01.04.2021 | Изучили ли руководители внимания в BERT грамматику избирательного округа? | ||
| • В исследовании представлен метод синтаксического расстояния для анализа грамматики избирательного округа в головах внимания BERT и RoBERTa. • Грамматика округа была извлечена и проанализирована до и после тонкой настройки задач SMS и NLI. • Задачи NLI повышают способность избирательного округа стимулировать грамматику, тогда как задачи SMS уменьшают ее на верхних уровнях. | |||
| 2019-11-27 | Отслеживают ли заголовки внимания в BERT синтаксические зависимости? | ||
| • В статье исследуется, фиксируют ли отдельные главы внимания в BERT синтаксические зависимости, используя веса внимания для извлечения отношений зависимости. • Проанализированы головы внимания BERT, используя максимальные веса внимания и максимальные остовные деревья, сравнив их с деревьями универсальных зависимостей. • Некоторые головы внимания отслеживают конкретные синтаксические зависимости лучше, чем базовые линии, но ни одна голова не выполняет целостный анализ значительно лучше. | |||
| 2019-11-01 | Адаптивно разреженные трансформаторы | ||
| • представил адаптивно редкий трансформатор с использованием альфа-энмакса, чтобы обеспечить гибкую контексту-зависимую редкость в головках внимания. • Применяется к наборам данных по машинному переводу для оценки интерпретации и разнообразия головок. • Достигнутые разнообразные распределения внимания и улучшенная интерпретация без ущерба для точности. | |||
| 2019-08-01 | На что смотрит Берт? Анализ внимания Берта | ||
| • В статье вводятся методы для анализа механизмов внимания Берта, выявляя закономерности, которые соответствуют лингвистическим структурам, таким как синтаксис и основной способности. • Анализ головок внимания, идентификация синтаксических и основных закономерностей, а также разработка зондирующего классификатора, основанного на внимании. • Головы внимания Берта отражают существенную синтаксическую информацию, особенно в таких задачах, как выявление прямых объектов и основных. | |||
| 2019-07-01 | Анализ мульти-головного самоуправления: специализированные головы делают тяжелую работу, остальные можно обрезать | ||
| • В документе вводит новый метод обрезки для мульти-головного самоуправления, который избирательно удаляет менее важные головы без значительной потери производительности. • Анализ индивидуальных глаз внимания, выявление их специализированных ролей и применение метода обрезки на модели трансформатора. • Обрезка 38 из 48 голов в кодере привела к падению бал -балла на 0,15. | |||
| 2018-11-01 | Анализ представлений энкодера в машинном переводе на основе трансформатора | ||
| • В этой статье анализируются внутренние представления слоев энкодера трансформатора, сосредоточенная на синтаксической и семантической информации, изученной самого преследования головами. • Испытающие задачи, извлечение отношений зависимостей и сценарий обучения передачи. • Более низкие слои захватывают синтаксис, в то время как более высокие слои кодируют более семантическую информацию. | |||
| 2016-03-21 | Включение механизма копирования в обучение последовательности к последовательности | ||
| • Вводит механизм копирования в модели последовательности к последовательности, чтобы обеспечить прямое копирование входных токенов, улучшая обработку редких слов. • Применяется к задачам машинного перевода и суммирования. • достигли существенных улучшений в точности перевода, особенно при редком переводе слов, по сравнению со стандартными моделями последовательности к последовательности. | |||
Шаблон выпуска:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


