AMRICA
1.0.0
AMRICA (Инспектор AMR по межъязыковому выравниванию) — это простой инструмент для выравнивания и визуального представления AMR (Banarescu, 2013) как для двуязычных контекстов, так и для одноязычного соглашения между аннотаторами. Он основан на системе Smatch (Cai, 2012) и расширяет ее для идентификации соглашения между аннотаторами по УПП.
Также можно использовать AMRICA для визуализации ручных выравниваний, которые вы отредактировали или скомпилировали самостоятельно (см. Общие флаги).
Загрузите исходный код Python с github.
Мы предполагаем, что у вас есть pip . Чтобы установить зависимости (при условии, что у вас уже есть зависимости Graphviz, упомянутые ниже), просто запустите:
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz требует, чтобы Graphviz работал. В Linux вам, возможно, придется установить graphviz libgraphviz-dev pkg-config . Кроме того, для подготовки данных двуязычного выравнивания вам понадобятся GIZA++ и, возможно, JAMR.
./disagree.py -i sample.amr -o sample_out_dir/
Эта команда прочитает AMR в sample.amr (разделенные пустыми строками) и поместит их графические визуализации в файлы .png, расположенные в sample_out_dir/ .
Для создания визуализации выравниваний Smatch нам нужен входной файл AMR, в котором каждое поле ::tok или ::snt содержит токенизированные предложения, поля ::id с идентификатором предложения и поля ::annotator или ::anno с идентификатором аннотатора. Аннотации к конкретному предложению перечисляются последовательно, и первая аннотация считается золотым стандартом для целей визуализации.
Если вы хотите визуализировать только одну аннотацию для каждого предложения без соглашения между аннотаторами, вы можете использовать файл AMR только с одним аннотатором. В этом случае поля аннотатора и идентификатора предложения являются необязательными. Полученный график будет полностью черным.
Для двуязычного выравнивания мы начинаем с двух файлов AMR: один содержит целевые аннотации, а другой — исходные аннотации в том же порядке, с полями ::tok и ::id для каждой аннотации. Если нам нужны выравнивания JAMR для любой стороны, мы включаем их в поле ::alignments .
Выравнивание предложений должно быть в форме двух файлов выравнивания GIZA++ .NBEST: одного исходного-целевого и одного целевого-источника. Чтобы сгенерировать их, используйте флаг --nbestalignments в файле конфигурации GIZA++, установив предпочитаемое вами количество nbest.
Флаги можно установить либо в командной строке, либо в файле конфигурации. Местоположение файла конфигурации можно установить с помощью -c CONF_FILE в командной строке.
Помимо --conf_file , существует несколько других флагов, которые применяются как к одноязычному, так и к двуязычному тексту. --outdir DIR — единственный обязательный параметр, указывающий каталог, в который мы будем записывать файлы изображений.
Необязательные общие флаги:
--verbose для распечатки предложений по мере их выравнивания.--no-verbose , чтобы переопределить подробную настройку по умолчанию.--json FILE.json для записи графиков выравнивания в файл .json.--num_restarts N , чтобы указать количество случайных перезапусков, которые должен выполнить Smatch.--align_out FILE.csv для записи выравниваний в файл.--align_in FILE.csv для чтения выравниваний с диска вместо запуска Smatch.--layout , чтобы изменить параметр макета на Graphviz.Файлы выравнивания .csv имеют формат, в котором каждый набор сопоставлений графиков разделен пустой строкой, а каждая строка в наборе содержит либо комментарий, либо строку, указывающую выравнивание. Например:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
Поля, разделенные табуляцией, — это индекс тестового узла (обработанный Smatch), метка тестового узла, индекс золотого узла и метка золотого узла.
Для одноязычного выравнивания требуется один дополнительный флаг --infile FILE.amr , где FILE.amr установлен в местоположение файла AMR.
Ниже приведен пример файла конфигурации:
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
При двуязычном выравнивании требуется больше флагов.
--src_amr FILE для исходного файла аннотации AMR.--tgt_amr FILE для целевого AMR-файла аннотаций.--align_tgt2src FILE.A3.NBEST для файла GIZA++ .NBEST, выравнивающего цель по источнику (с целью vcb1), созданного с помощью --nbestalignments N--align_src2tgt FILE.A3.NBEST для файла GIZA++ .NBEST, выравнивающего источник-цель (с источником как vcb1), созданного с помощью --nbestalignments N Теперь, если для --nbestalignments N установлено значение >1, мы должны указать его с помощью --num_aligned_in_file . Если мы хотим посчитать только верхние --num_align_read .
--nbestalignments — сложный в использовании флаг, поскольку он генерируется только при окончательном выравнивании. Я сам смог заставить его работать только с настройками GIZA++ по умолчанию.
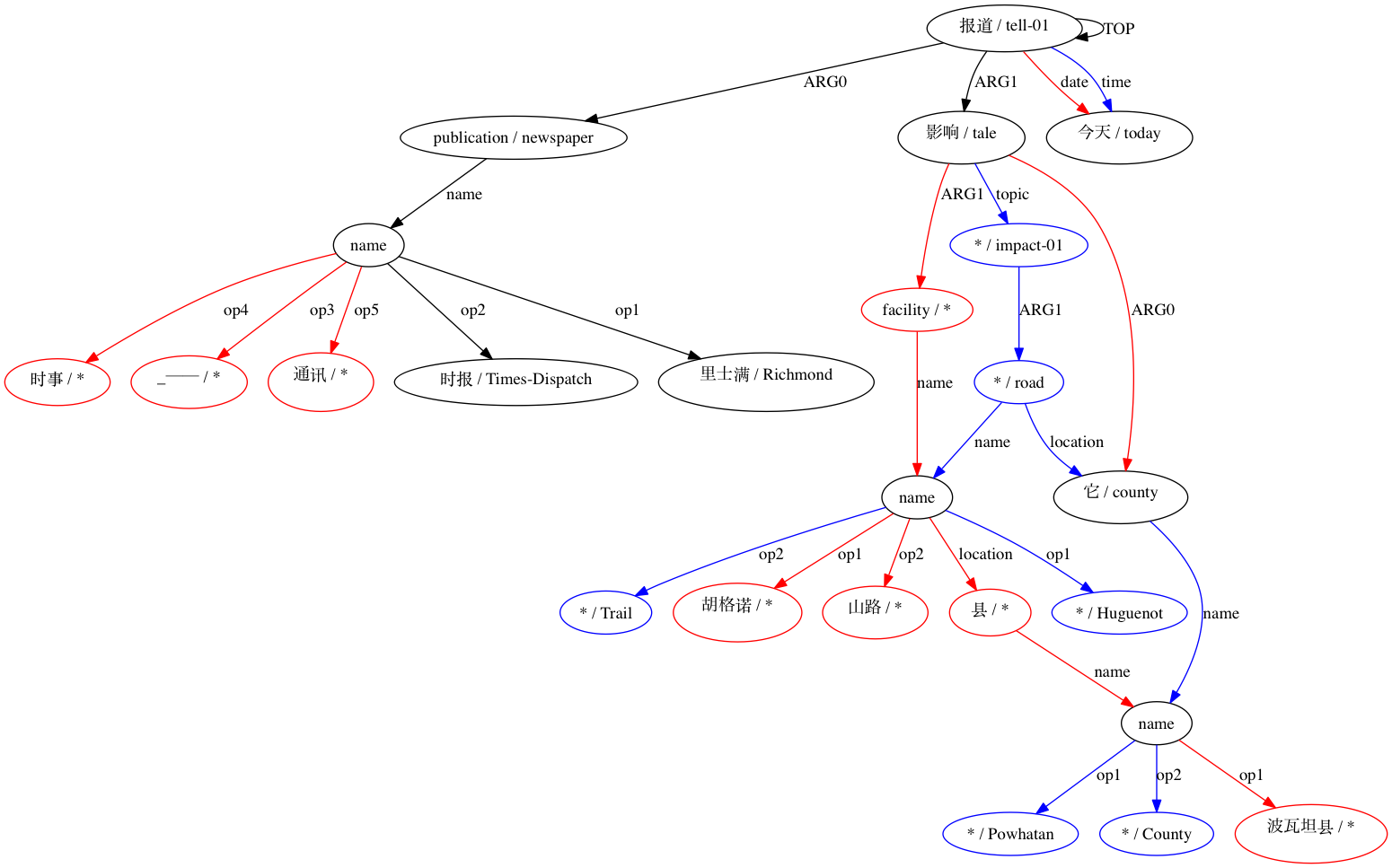
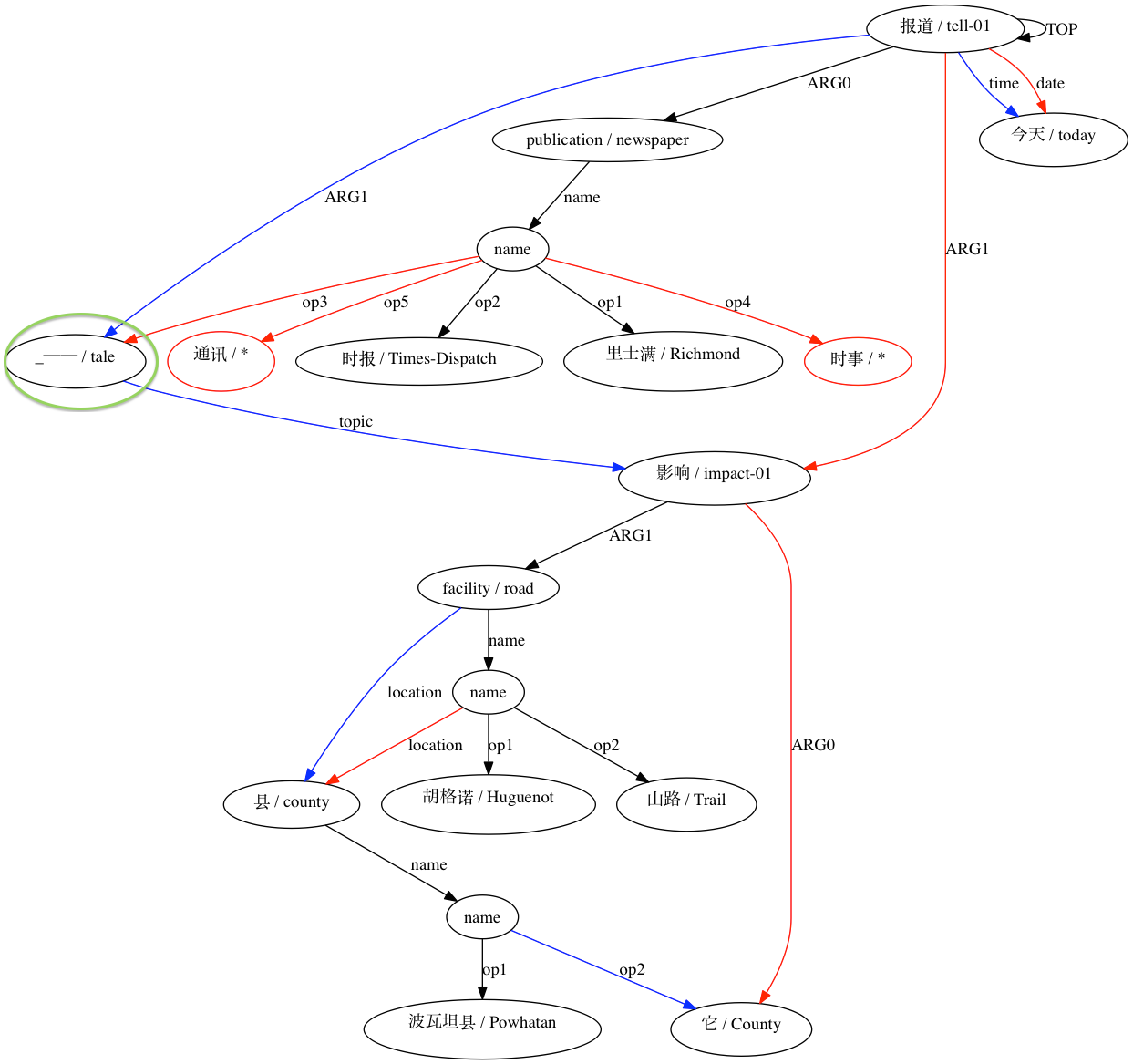
Поскольку AMRICA является разновидностью Smatch, следует начать с понимания Smatch. Smatch пытается определить соответствие между переменными узлами двух AMR-представлений одного и того же предложения, чтобы измерить согласие между аннотаторами. Соответствие должно быть выбрано так, чтобы максимизировать оценку Smatch, которая присваивает балл каждому ребру, появляющемуся на обоих графиках, и делится на три категории. Каждая категория проиллюстрирована следующей аннотацией «Это не заняло много времени».
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)(ARG0, t, i)(polarity, l2, -)Поскольку задача поиска соответствия, максимизирующего оценку Smatch, является NP-полной, Smatch использует алгоритм восхождения на холм для аппроксимации лучшего решения. Он затрачивает путем сопоставления каждого узла с узлом, имеющим общую метку, если это возможно, и случайным образом сопоставляя оставшиеся узлы в меньшем графе (далее цель). Затем Smatch выполняет шаг, находя действие, которое больше всего увеличит оценку, либо переключая совпадения двух целевых узлов, либо перемещая сопоставление с исходного узла на несовпадающий исходный узел. Он повторяет этот шаг до тех пор, пока ни один из шагов не сможет немедленно увеличить оценку Smatch.
Чтобы избежать локальных оптимумов, Smatch обычно перезагружается 5 раз.
Для получения технических подробностей о внутренней работе AMRICA, возможно, будет более полезно прочитать наш демонстрационный документ NAACL.
AMRICA начинается с замены всех постоянных узлов узлами переменных, которые являются экземплярами метки константы. Это необходимо, чтобы мы могли выровнять постоянные узлы, а также переменные. Таким образом, единственные баллы, добавленные к баллу AMRICA, будут получены за сопоставление ребер переменной-переменной и меток экземпляра.
В то время как Smatch пытается сопоставить каждый узел меньшего графа с некоторым узлом большего графа, AMRICA удаляет совпадения, которые не увеличивают модифицированную оценку Smatch или оценку AMRICA.
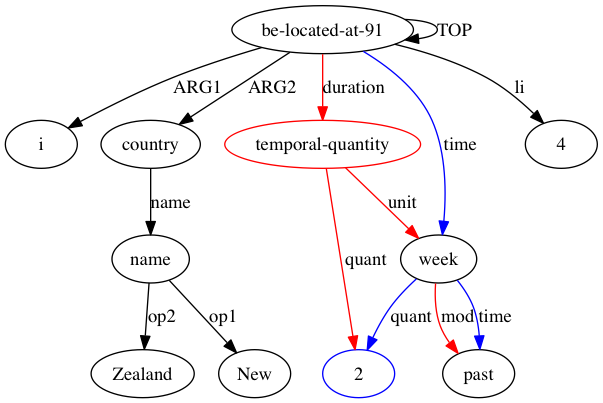
Затем AMRICA генерирует файлы изображений на основе графиков выравниваний. Если узел или ребро появляется только в данных золотого цвета, он имеет красный цвет. Если этот узел или ребро появляется только в тестовых данных, он отображается синим цветом. Если узел или ребро имеют совпадение в нашем окончательном выравнивании, они черные.
В AMRICA вместо добавления одной точки за каждую идеально совпадающую метку экземпляра мы добавляем точку на основе оценки вероятности совпадения этих меток. Оценка правдоподобия ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) с целевым набором меток Lt, исходным набором меток Ls, целевым предложением Wt, исходным предложением Ws и выравниванием aLt,Ls[i] с отображением Lt[ i] на некоторую метку Ls[aLt,Ls[i]] вычисляется на основе вероятности, которая определяется следующими правилами:
В целом, для хорошей работы двуязычной AMRICA требуется больше случайных перезапусков, чем одноязычной AMRICA. Это количество перезапусков можно изменить с помощью флага --num_restarts .
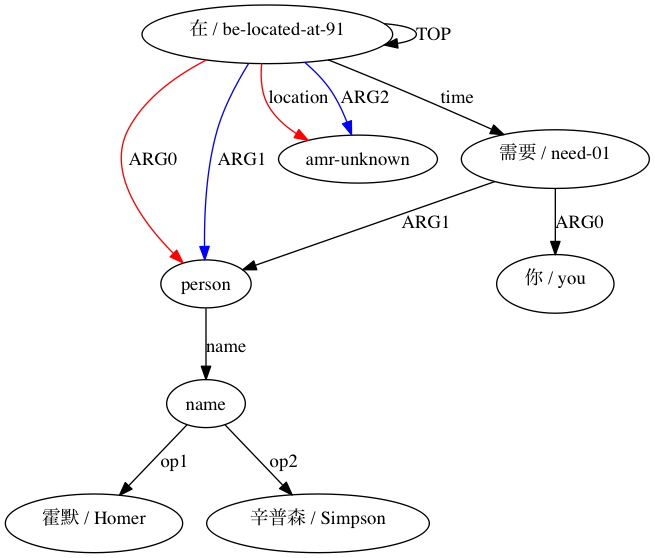
Мы можем наблюдать, в какой степени использование приближений типа Smatch (здесь с 20 случайными инициализациями) повышает точность по сравнению с выбором вероятных совпадений из необработанных данных выравнивания (умная инициализация). Для пары, объявленной структурно совместимой (Xue 2014).
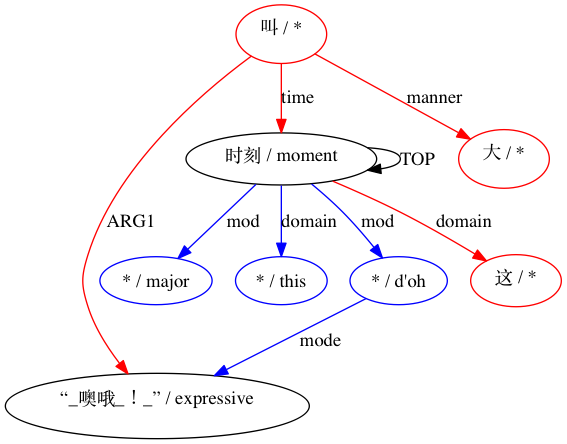
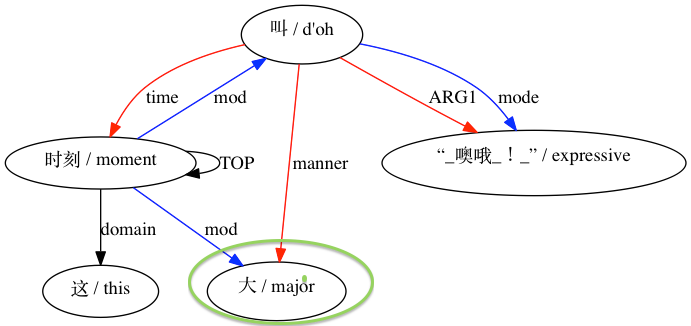
Для пары, считающейся несовместимой:
Данное программное обеспечение было разработано частично при поддержке Национального научного фонда (США) по наградам 1349902 и 0530118. Эдинбургский университет является благотворительной организацией, зарегистрированной в Шотландии под регистрационным номером SC005336.


