llmjudge
1.0.0
Оценивать LLM по открытому сценарию сложно, растет консенсус в отношении отсутствия существующих критериев, а опытные специалисты предпочитают сами модели проверки вибрации . Я прибегал к неофициальным оценкам разработчиков и исследователей, которым доверяю, и Chatbot Arena является отличным дополнением. Мотивацией этого репо является все более популярный метод использования сильных LLM в качестве судьи для моделей. Этот метод существует уже несколько месяцев в таких моделях, как JudgeLM, а в последнее время и MT-Bench.
Возможно, вы видели или не видели эту тему. По мнению авторов твита в Arize AI, использование LLM в качестве судьи требует осторожности со стороны сервера, особенно в отношении использования числовых оценок баллов. Кажется, что LLM очень плохо справляются с непрерывными диапазонами, что становится совершенно очевидным, когда им предлагается оценить X от 1 до 10. Этот репозиторий представляет собой живой документ экспериментов, пытающихся понять и уловить неровную границу этой проблемы. Недавняя работа установила сильную корреляцию между MT-Bench и человеческим суждением (Арена Эло) , а это означает, что выпускники LLM способны быть судьями, так что же здесь происходит?
Ниже приведены все подробности и результаты.
Из-за ограничений по стоимости я сначала сосредоточусь на задаче по написанию/ошибке, описанной в твитах. Я немного обеспокоен тем, что количественный X этой задачи испортит суть этого эксперимента, но посмотрим. Я приветствую более полный анализ этого явления, к моим результатам следует относиться с долей скептицизма, учитывая ограниченность эксперимента.
Я создал набор данных об орфографии или орфографических ошибках, но не уверен, какое имя больше подходит, на основе эссе Пола Грэма. Этот выбор был сделан в основном из соображений удобства, поскольку я уже использовал набор данных раньше при проверке контекстных окон под давлением. Я извлек контекст из 3000 слов из эссе и вставил орфографические ошибки в случайные слова в зависимости от желаемого соотношения орфографических ошибок. В псевдокоде:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
Полный код доступен в виде блокнота.
Учитывая сгенерированный набор данных, мы предлагаем LLM оценить количество слов с ошибками в контексте, используя различные шаблоны оценки. Мы используем следующие API
GPT-4: gpt-4-0125-preview
ГПТ-3.5: gpt-3.5-turbo-1106
при температуре = 0.
Тест 1. Давайте подтвердим, что LLM с трудом справляется с обработкой числовых диапазонов при нулевых настройках. Мы предлагаем GPT-3.5 и GPT-4 с числовым шаблоном оценки в диапазоне от 0 до 10.
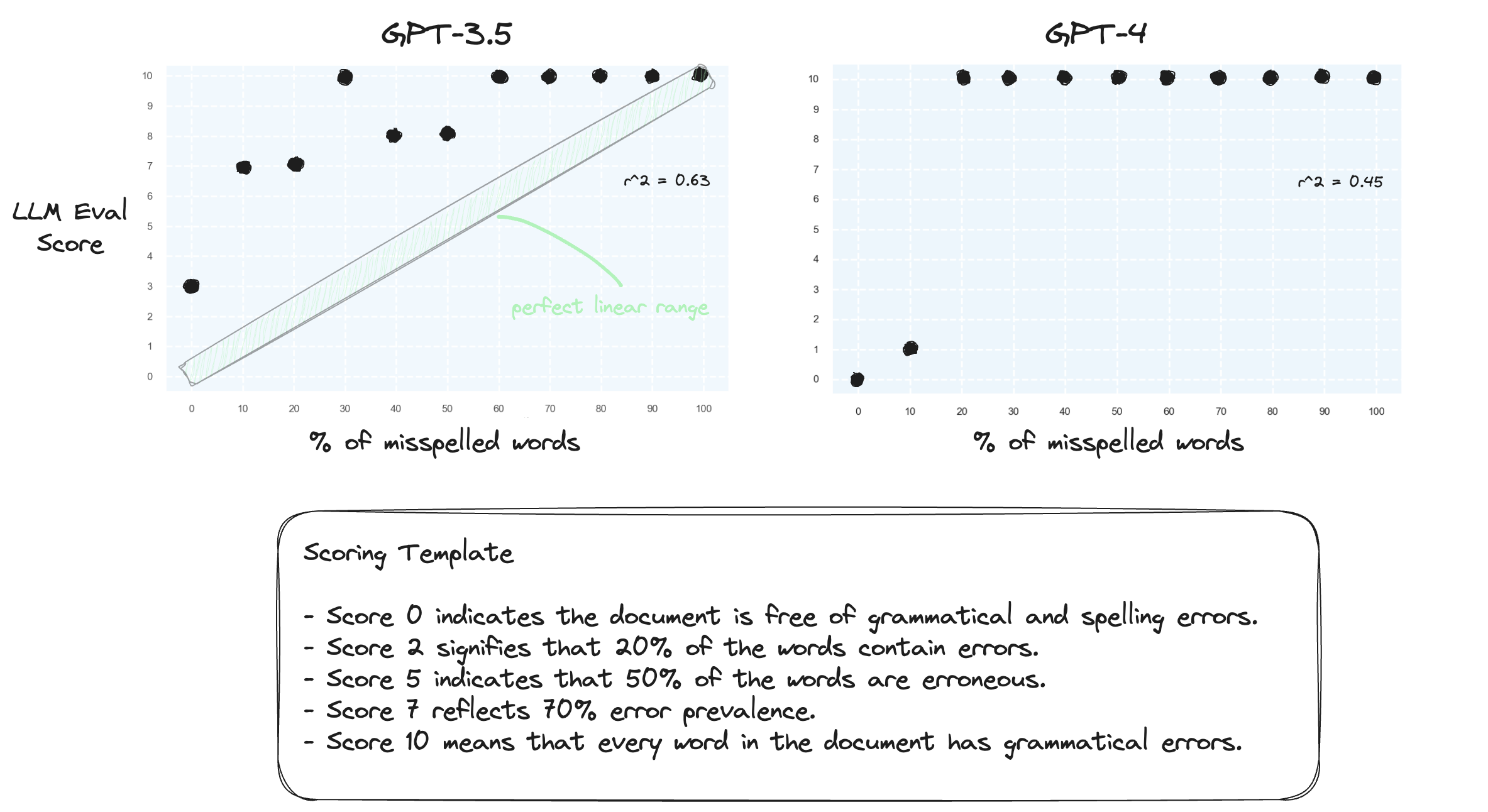
Как и ожидалось, оба сильно ошибаются.
Тест 2. Что произойдет, если мы поменяем местами диапазон оценок? Теперь оценка 10 соответствует идеально написанному документу.
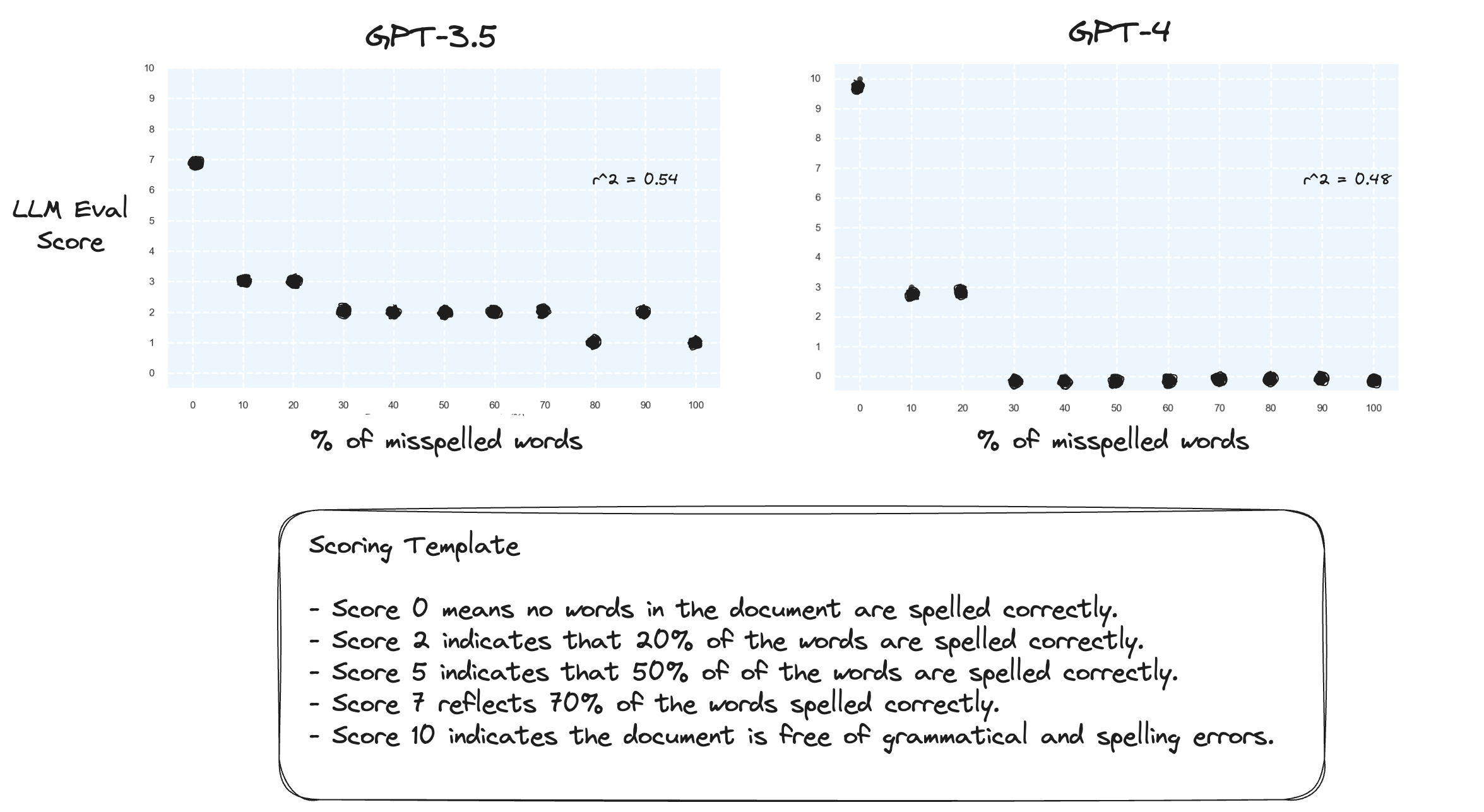
Кажется, это не имеет большого значения.
Тест 3. Если бы мы поверили гипотезе Аризе, мы могли бы увидеть улучшения, если бы избегали критерия оценки и вместо этого использовали «маркированные оценки». В данном случае я решил перейти к 5-балльной шкале оценок.
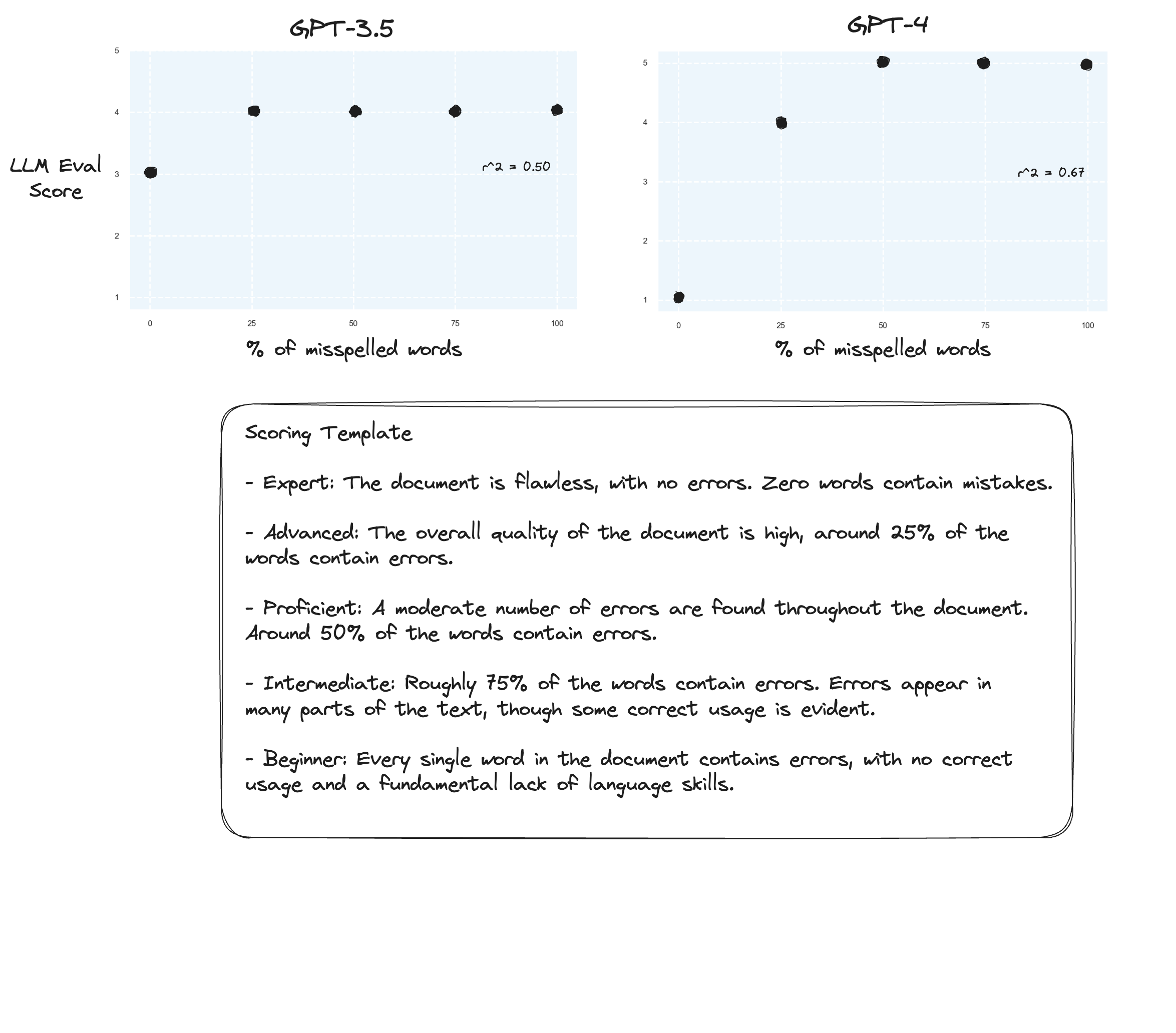
Возможно, небольшие улучшения? Трудно сказать честно. Я не впечатлен.
Тест 4. А как насчет цепочки мыслей с нулевым выстрелом?

gpt-3.5 превратился в тарабарщину для двух подсказок. Как и ожидалось, gpt-4 видит улучшение, когда ему предлагается мыслить вслух. Обратите внимание, что очень нерешительно присвоить оценку 10.
Тест 5. Как предложил автор Прометея; сопоставление каждого балла с собственным объяснением, вероятно, улучшит способность LLM выставлять оценки по всему числовому диапазону. В сочетании с CoT это приводит к:

Продолжение улучшений для gpt-4. По-прежнему очень неохотно присваивают граничные оценки 0 и 10.
Тест 6. Прочитав больше о MT Bench, я решил протестировать альтернативный подход, используя парные сравнения, а не изолированную оценку. Обычно для этого требуется сравнение O(n * log N), но поскольку мы уже знаем порядок, я решил, что мы просто проверим самые сложные случаи: сравнение 0% орфографических ошибок с 10% орфографических ошибок, 10% с 20% и так далее. всего 10 сравнений. Обратите внимание, что я также использовал CoT с нулевым выстрелом.
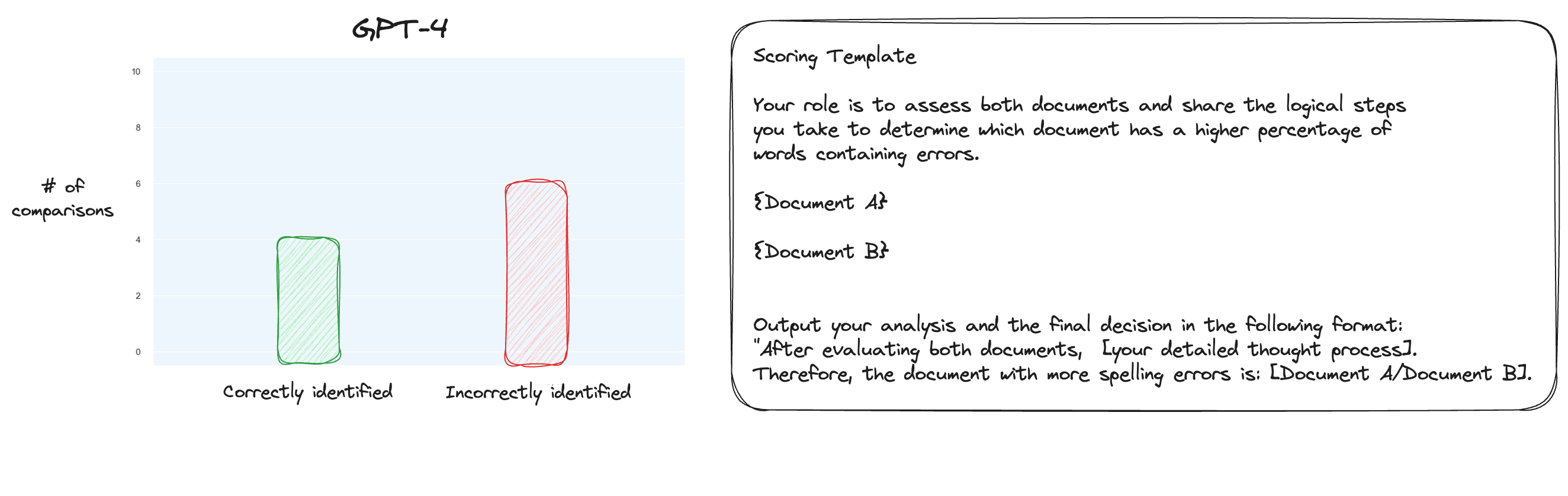
Моя гипотеза заключалась в том, что GPT-4 преуспел бы в сценарии, в котором ему приходилось сравнивать два текста внутри контекстного окна, но я ошибался. К моему удивлению, это совсем не улучшило ситуацию. Конечно, это самое сложное из всех возможных сравнений, но в целом это по-прежнему простая задача. Возможно, количественные аспекты этой задачи просто очень сложны для студентов магистратуры. Хм, возможно, мне нужно найти лучшую прокси-задачу...
(31/1) Я изучал внутренности MT-Bench и был очень удивлен, обнаружив, что они просто просят GPT-4 оценивать результаты по шкале от 1 до 10. Они предоставляют альтернативные варианты оценки, такие как парное сравнение с базовым уровнем, но рекомендуемый вариант — числовой. Подсказка для принятия решения также неожиданно проста:
Пожалуйста, выступите в роли беспристрастного судьи и оцените качество ответа ИИ-помощника на вопрос пользователя, показанный ниже. Ваша оценка должна учитывать такие факторы, как полезность, актуальность, точность, глубина, креативность и уровень детализации ответа. Начните оценку с краткого объяснения. Будьте максимально объективны. После предоставления объяснения вы должны оценить ответ по шкале от 1 до 10, строго следуя следующему формату: [рейтинг], например: «Рейтинг: 5». [Вопрос] {вопрос} [Начало ответа Ассистента] {ответ} [Конец ответа Ассистента]
Если верить, что это все, что нужно для оценки в MT-Bench, то я начинаю сомневаться в использовании задачи на орфографическую ошибку в качестве прокси-задачи...
(2/2) Я хочу, чтобы GPT-4 оценивал тексты с ошибками посредством парного сравнения, а не путем изолированного подсчета баллов. Это один из альтернативных методов оценки для MT Bench (хотя они рекомендуют изолированную оценку), и я подозреваю, что он больше подходит для этой задачи. Результаты полного сопоставления CoT + определенно являются улучшением, но я все еще думаю, что еще есть над чем поработать. Недостаток парного подсчета, конечно, заключается в том, что вам понадобится значительно больше вызовов API для установления полного рейтинга (на практике).


