DreamerGPT
1.0.0
 DreamerGPT: точная настройка инструкций модели на китайском языке
DreamerGPT: точная настройка инструкций модели на китайском языке? DreamerGPT — это проект тонкой настройки инструкций для модели большого языка на китайском языке, инициированный Сюй Хао, Чи Хусюань, Бэй Юаньчэнем и Лю Даньяном.
Читайте в английской версии .

 1. Представление проекта
1. Представление проектаЦелью этого проекта является содействие применению моделей китайского большого языка в более вертикальных сценариях.
Наша цель — уменьшить большие модели и помочь каждому тренироваться и иметь индивидуального эксперта-помощника в своей вертикальной области. Он может быть психологом-консультантом, помощником по коду, личным помощником или вашим собственным репетитором по языку, а это означает, что. DreamerGPT — это языковая модель, которая дает наилучшие результаты, самую низкую стоимость обучения и более оптимизирована для китайского языка. Проект DreamerGPT продолжит открывать возможности для горячего старта итеративной языковой модели (включая LLaMa, BLOOM), обучения инструкциям, обучения с подкреплением, точной настройки вертикального поля, а также продолжит итерацию надежных данных обучения и целей оценки. Из-за ограниченности персонала и ресурсов проекта текущая версия V0.1 оптимизирована для LLaMa на китайском языке для LLaMa-7B и LLaMa-13B, добавляя китайские функции, выравнивание языка и другие возможности. В настоящее время все еще существуют недостатки в возможностях длинных диалогов и логических рассуждений. Дополнительные планы итераций см. в следующей версии обновления.
Ниже приведена демонстрация квантования на основе 8b (видео не ускоряется). В настоящее время также выполняются итерации ускорения вывода и оптимизации производительности:
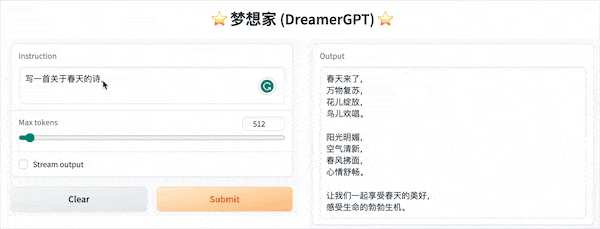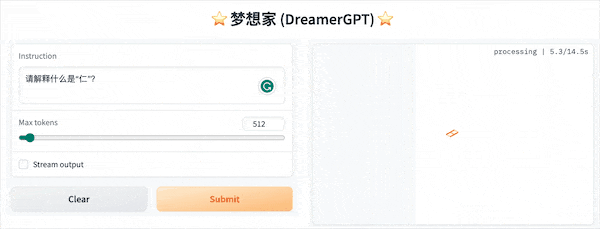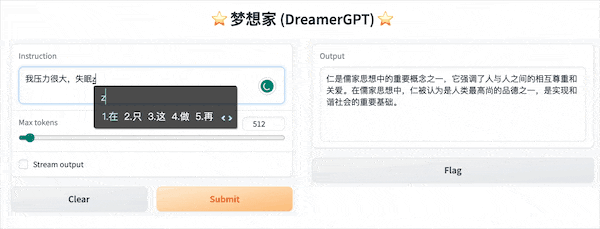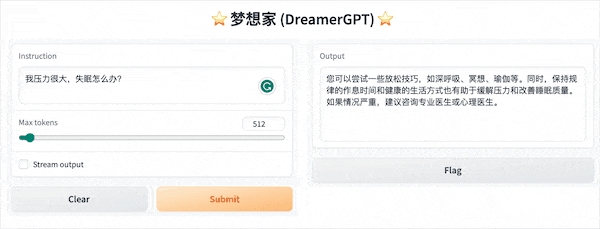
Еще демонстрационные дисплеи:
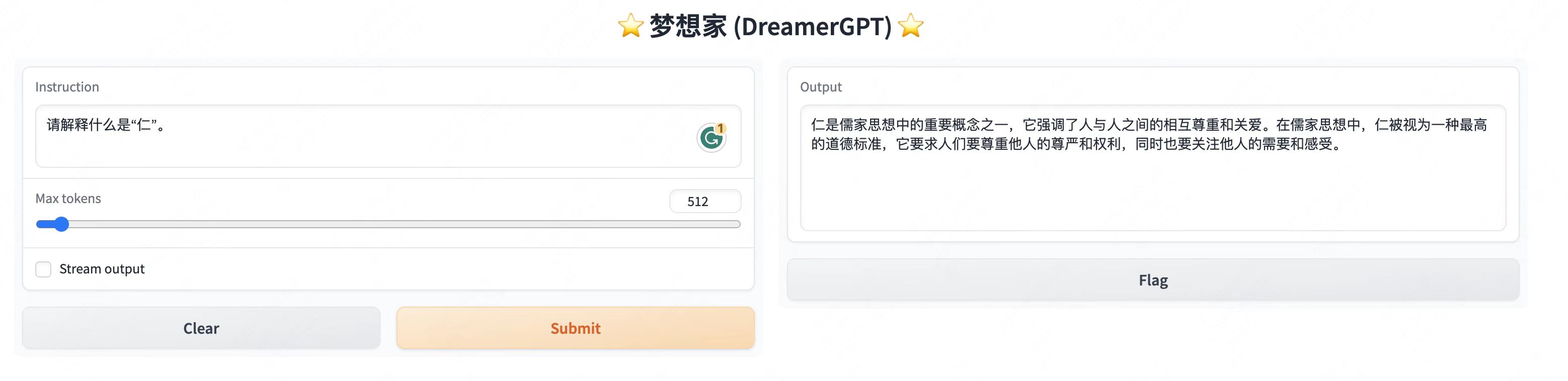

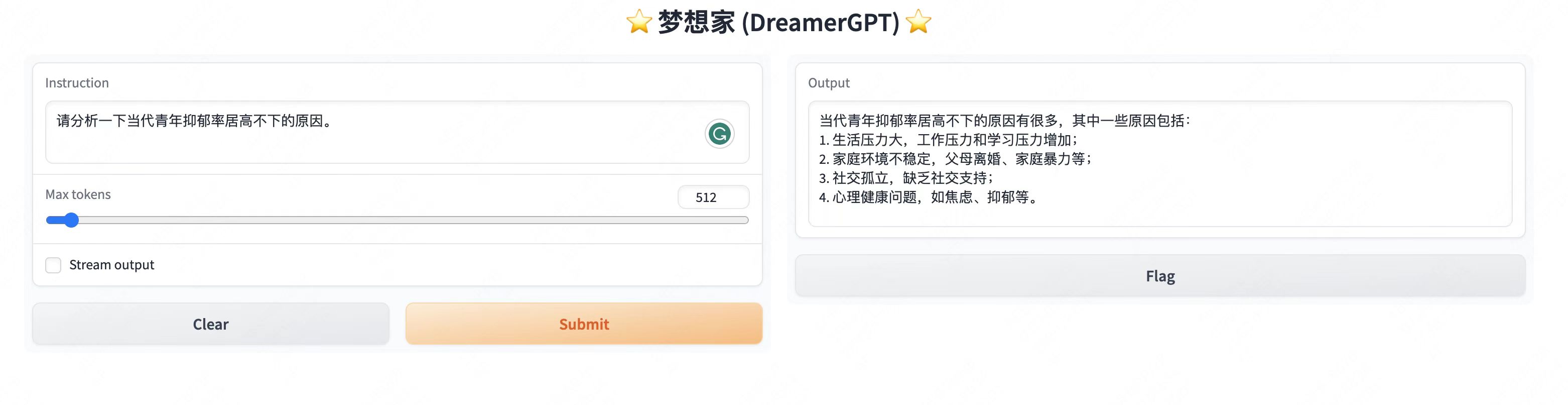
 2. Последнее обновление
2. Последнее обновление  [2023/06/17] Обновление версии V0.2: версия для дополнительного обучения LLaMa Firefly, версия BLOOM-LoRA (
[2023/06/17] Обновление версии V0.2: версия для дополнительного обучения LLaMa Firefly, версия BLOOM-LoRA ( finetune_bloom.py , generate_bloom.py ).
[2023/04/23] Китайская команда официально с открытым исходным кодом дорабатывает большую модель Dreamer (DreamerGPT) , в настоящее время предоставляет возможность загрузки версии V0.1.
Существующие модели (непрерывное дополнительное обучение, необходимо обновить больше моделей):
| Название модели | данные обучения = | Вес скачать |
|---|---|---|
| Версия 0.2 | --- | --- |
| Д13б-3-3 | Д13б-2-3 + светлячок-поезд-1 | [Обнимающее лицо] |
| D7b-5-1 | Д7б-4-1 + светлячок-поезд-1 | [Обнимающее лицо] |
| Версия 0.1 | --- | --- |
| D13b-1-3-1 | Китайская-альпака-лора-13b-горячий старт + COIG-часть1, COIG-перевод + PsyQA-5 | [Google Диск] [HuggingFace] |
| D13b-2-2-2 | Китайская-альпака-лора-13b-горячий старт + светлячок-поезд-0 + COIG-часть1, COIG-перевод | [Google Диск] [HuggingFace] |
| Д13б-2-3 | Китайская-альпака-лора-13b-горячий старт + светлячок-поезд-0 + COIG-часть1, COIG-перевод + PsyQA-5 | [Google Диск] [HuggingFace] |
| D7b-4-1 | Китайская-альпака-лора-7b-горячий старт+светлячок-поезд-0 | [Google Диск] [HuggingFace] |
Предварительный просмотр оценки модели
 3. Модель и подготовка данных
3. Модель и подготовка данныхЗагрузка веса модели:
Данные единообразно обрабатываются в следующий формат json:
{
" instruction " : " ... " ,
" input " : " ... " ,
" output " : " ... "
}Скрипт загрузки и предварительной обработки данных:
| данные | тип |
|---|---|
| Альпака-GPT4 | Английский |
| Firefly (предварительная обработка в несколько копий, выравнивание формата) | китайский |
| ЦИГ | Китайский, код, китайский и английский |
| PsyQA (предварительно обработано в несколько копий, выровнено по формату) | Китайская психологическая консультация |
| БЕЛЬ | китайский |
| сукно | китайский разговор |
| Куплеты (предварительно обработанные в несколько копий, выровненные по формату) | китайский |
Примечание. Данные получены из сообщества открытого исходного кода, и доступ к ним можно получить по ссылкам.
 4. Обучающий код и скрипты
4. Обучающий код и скриптыВведение в код и скрипт:
finetune.py : инструкции по точной настройке кода горячего запуска/инкрементального обучения.generate.py : код вывода/тестированияscripts/ : запускать скриптыscripts/rerun-2-alpaca-13b-2.sh , см. scripts/README.md для объяснения каждого параметра.  5. Как использовать
5. Как использоватьПожалуйста, обратитесь к Alpaca-LoRA за подробностями и ответами на соответствующие вопросы.
pip install -r requirements.txtСлияние весов (на примере альпака-лора-13b):
cd scripts/
bash merge-13b-alpaca.shЗначение параметра (пожалуйста, измените соответствующий путь самостоятельно):
--base_model , исходный вес ламы--lora_model , вес китайской ламы/альпаки-лоры--output_dir , путь к выходным весам объединенияВозьмите следующий процесс обучения в качестве примера, чтобы показать работающий сценарий.
| начинать | ф1 | f2 | f3 |
|---|---|---|---|
| Китайская-альпака-лора-13б-горячий старт, номер эксперимента: 2 | Данные: светлячок-поезд-0 | Данные: COIG-part1, COIG-translate. | Данные: PsyQA-5 |
cd scripts/
# 热启动f1
bash run-2-alpaca-13b-1.sh
# 增量训练f2
bash rerun-2-alpaca-13b-2.sh
bash rerun-2-alpaca-13b-2-2.sh
# 增量训练f3
bash rerun-2-alpaca-13b-3.shОбъяснение важных параметров (пожалуйста, измените соответствующие пути самостоятельно):
--resume_from_checkpoint '前一次执行的LoRA权重路径'--train_on_inputs False--val_set_size 2000 Если сам набор данных относительно небольшой, его можно соответствующим образом уменьшить, например 500, 200.Обратите внимание: если вы хотите напрямую загрузить точно настроенные веса для вывода, вы можете игнорировать 5.3 и перейти непосредственно к 5.4.
Например, я хочу оценить доработанные результаты rerun-2-alpaca-13b-2.sh :
1. Взаимодействие с веб-версией:
cd scripts/
bash generate-2-alpaca-13b-2.sh2. Пакетный вывод и сохранение результатов:
cd scripts/
bash save-generate-2-alpaca-13b-2.shОбъяснение важных параметров (пожалуйста, измените соответствующие пути самостоятельно):
--is_ui False : независимо от того, является ли это веб-версией, значение по умолчанию — True.--test_input_path 'xxx.json' : путь к входной инструкцииtest.json в соответствующем каталоге весов LoRA.  6. Отчет об оценке
6. Отчет об оценке В настоящее время в оценочных выборках имеется 8 типов тестовых задач (оцениваемая численная этика и диалог Дуолун), каждая категория имеет 10 образцов, а 8-битная количественная версия оценивается в соответствии с интерфейсом, вызывающим GPT-4/GPT 3.5 ( неколичественная версия имеет более высокий балл), каждый образец оценивается в диапазоне от 0 до 10. См test_data/ для ознакомительных образцов.
以下是五个类似 ChatGPT 的系统的输出。请以 10 分制为每一项打分,并给出解释以证明您的分数。输出结果格式为:System 分数;System 解释。
Prompt:xxxx。
答案:
System1:xxxx。
System2:xxxx。
System3:xxxx。
System4:xxxx。
System5:xxxx。Примечание. Оценка предназначена только для справки (по сравнению с GPT 3.5). Оценка GPT 4 является более точной и более справочной.
| Тестовые задания | Подробный пример | Количество образцов | D13b-1-3-1 | D13b-2-2-2 | Д13б-2-3 | D7b-4-1 | ЧатGPT |
|---|---|---|---|---|---|---|---|
| Общий балл по каждому пункту | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Пустяки | 01qa.json | 10 | 80* | 78 | 78 | 68 | 95 |
| переводить | 02translate.json | 10 | 77* | 77* | 77* | 64 | 86 |
| генерация текста | 03generate.json | 10 | 56 | 65* | 55 | 61 | 91 |
| анализ настроений | 04analyse.json | 10 | 91 | 91 | 91 | 88* | 88* |
| понимание прочитанного | 05understanding.json | 10 | 74* | 74* | 74* | 76,5 | 96,5 |
| Китайские особенности | 06chinese.json | 10 | 69* | 69* | 69* | 43 | 86 |
| генерация кода | 07code.json | 10 | 62* | 62* | 62* | 57 | 96 |
| Этика, отказ от ответа | 08alignment.json | 10 | 87* | 87* | 87* | 71 | 95,5 |
| математическое рассуждение | (подлежит оценке) | -- | -- | -- | -- | -- | -- |
| Несколько раундов диалога | (подлежит оценке) | -- | -- | -- | -- | -- | -- |
| Тестовые задания | Подробный пример | Количество образцов | D13b-1-3-1 | D13b-2-2-2 | Д13б-2-3 | D7b-4-1 | ЧатGPT |
|---|---|---|---|---|---|---|---|
| Общий балл по каждому пункту | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Пустяки | 01qa.json | 10 | 65 | 64 | 63 | 67* | 89 |
| переводить | 02translate.json | 10 | 79 | 81 | 82 | 89* | 91 |
| генерация текста | 03generate.json | 10 | 65 | 73* | 63 | 71 | 92 |
| анализ настроений | 04analyse.json | 10 | 88* | 91 | 88* | 85 | 71 |
| понимание прочитанного | 05understanding.json | 10 | 75 | 77 | 76 | 85* | 91 |
| Китайские особенности | 06chinese.json | 10 | 82* | 83 | 82* | 40 | 68 |
| генерация кода | 07code.json | 10 | 72 | 74 | 75* | 73 | 96 |
| Этика, отказ от ответа | 08alignment.json | 10 | 71* | 70 | 67 | 71* | 94 |
| математическое рассуждение | (подлежит оценке) | -- | -- | -- | -- | -- | -- |
| Несколько раундов диалога | (подлежит оценке) | -- | -- | -- | -- | -- | -- |
В целом модель имеет хорошие показатели при переводе , анализе настроений , понимании прочитанного и т. д.
Два человека забили вручную, а затем взяли среднее значение.
| Тестовые задания | Подробный пример | Количество образцов | D13b-1-3-1 | D13b-2-2-2 | Д13б-2-3 | D7b-4-1 | ЧатGPT |
|---|---|---|---|---|---|---|---|
| Общий балл по каждому пункту | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Пустяки | 01qa.json | 10 | 83* | 82 | 82 | 69,75 | 96,25 |
| переводить | 02translate.json | 10 | 76,5* | 76,5* | 76,5* | 62,5 | 84 |
| генерация текста | 03generate.json | 10 | 44 | 51,5* | 43 | 47 | 81,5 |
| анализ настроений | 04analyse.json | 10 | 89* | 89* | 89* | 85,5 | 91 |
| понимание прочитанного | 05understanding.json | 10 | 69* | 69* | 69* | 75,75 | 96 |
| Китайские особенности | 06chinese.json | 10 | 55* | 55* | 55* | 37,5 | 87,5 |
| генерация кода | 07code.json | 10 | 61,5* | 61,5* | 61,5* | 57 | 88,5 |
| Этика, отказ от ответа | 08alignment.json | 10 | 84* | 84* | 84* | 70 | 95,5 |
| численная этика | (подлежит оценке) | -- | -- | -- | -- | -- | -- |
| Несколько раундов диалога | (подлежит оценке) | -- | -- | -- | -- | -- | -- |
 7. Содержание обновления следующей версии.
7. Содержание обновления следующей версии.Список дел:
 Ограничения, ограничения на использование и отказ от ответственности
Ограничения, ограничения на использование и отказ от ответственностиМодель SFT, обученная на основе текущих данных и базовых моделей, по-прежнему имеет следующие проблемы с точки зрения эффективности:
Фактические инструкции могут привести к неправильным ответам, противоречащим фактам.
Вредные инструкции невозможно правильно идентифицировать, что может привести к дискриминационным, вредным и неэтичным замечаниям.
Возможности модели все еще нуждаются в улучшении в некоторых сценариях, включающих рассуждения, кодирование, несколько раундов диалога и т. д.
Учитывая ограничения вышеуказанной модели, мы требуем, чтобы содержимое этого проекта и последующих производных, созданных этим проектом, можно было использовать только в академических исследовательских целях и не использовать в коммерческих целях или в целях, наносящих вред обществу. Разработчик проекта не несет никакой ответственности, ущерба или юридической ответственности, вызванной использованием данного проекта (включая, помимо прочего, данные, модели, коды и т. д.).
 Цитировать
ЦитироватьЕсли вы используете код, данные или модели этого проекта, укажите этот проект.
@misc{DreamerGPT,
author = {Hao Xu, Huixuan Chi, Yuanchen Bei and Danyang Liu},
title = {DreamerGPT: Chinese Instruction-tuning for Large Language Model.},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/DreamerGPT/DreamerGPT}},
}
 Связаться с нами
Связаться с намиВ этом проекте еще много недостатков. Пожалуйста, оставляйте нам свои предложения и вопросы, и мы постараемся сделать все возможное, чтобы улучшить этот проект.
Электронная почта: [email protected]


