datalens
1.0.0
Это личный эксперимент, в котором LLM используется для ранжирования неструктурированных данных о вакансиях на основе критериев, определяемых пользователем. Традиционные платформы поиска работы полагаются на жесткие системы фильтрации, но многим пользователям не хватает таких конкретных критериев. Datalens позволяет вам определить свои предпочтения более естественным способом, а затем оценить каждое объявление о вакансии на основе его релевантности.
Некоторые критерии могут быть более важными, чем другие, поэтому «обязательные критерии» имеют вес в два раза больше, чем обычные.
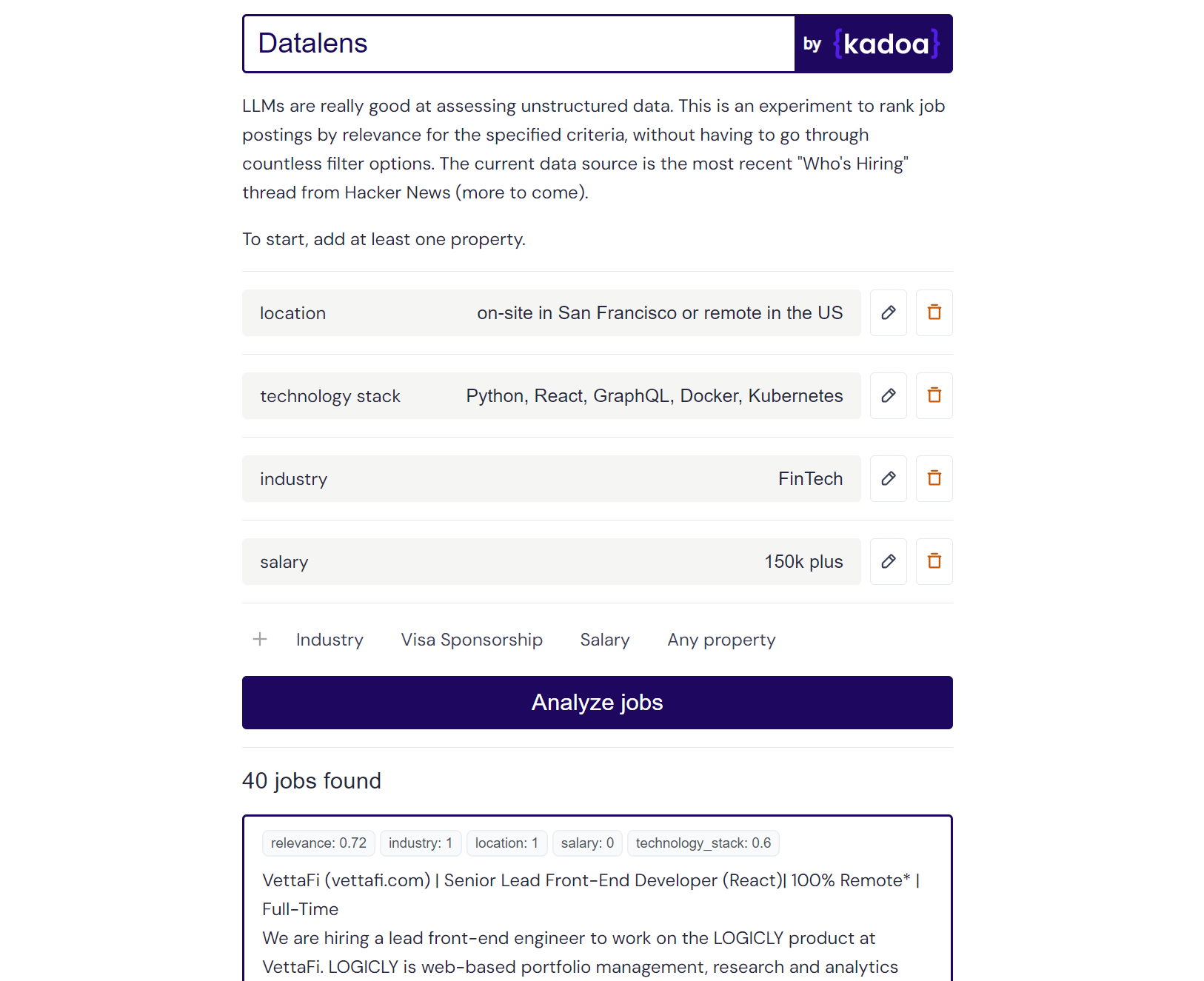
Результат примера Клода-2:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
Вы можете добавить любой источник данных о задании, который вам нравится. Я предварительно настроил его с использованием самой последней темы «Кто нанимает» от Hacker News, но вы можете добавить свои собственные источники.
Добавьте новые источники заданий, обновив source_config.json. Пример:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
Я использовал свой собственный инструмент Kadoa для получения данных о вакансиях со страниц компании, но вы можете использовать любой другой традиционный метод очистки.
Вот несколько готовых общедоступных конечных точек для получения всех объявлений о вакансиях от этих компаний (обновляются ежедневно):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
Дайте мне знать, если следует добавить какие-либо другие компании. Также мы рады предоставить вам пробный доступ к Кадоа.
Оценка релевантности лучше всего работает с gpt-4-0613 , который возвращает детальные оценки от 0 до 1. claude-2 тоже работает неплохо, если у вас есть к нему доступ. Можно использовать gpt-3.5-turbo-0613 , но он часто возвращает двоичные оценки 0 или 1 для критериев, не имея нюансов, позволяющих различать частичные и полные совпадения.
Модель по умолчанию — gpt-3.5-turbo-0613 из соображений экономии. Вы можете переключиться с GPT на Claude, заменив use_claude на use_openai .
Постоянное выполнение этого сценария может привести к интенсивному использованию API, поэтому используйте его ответственно. Я записываю стоимость каждого вызова GPT.
Чтобы запустить приложение, вам необходимо:
Скопируйте файл .env.example и заполните его.
Запустите сервер Flask:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
Перейдите в каталог клиента и установите зависимости Node:
cd client
npm install
Запустите клиент Next.js:
cd client
npm run dev


