ShapeGPT
1.0.0

Страница проекта • Arxiv Paper • Демо • Часто задаваемые вопросы • Цитирование
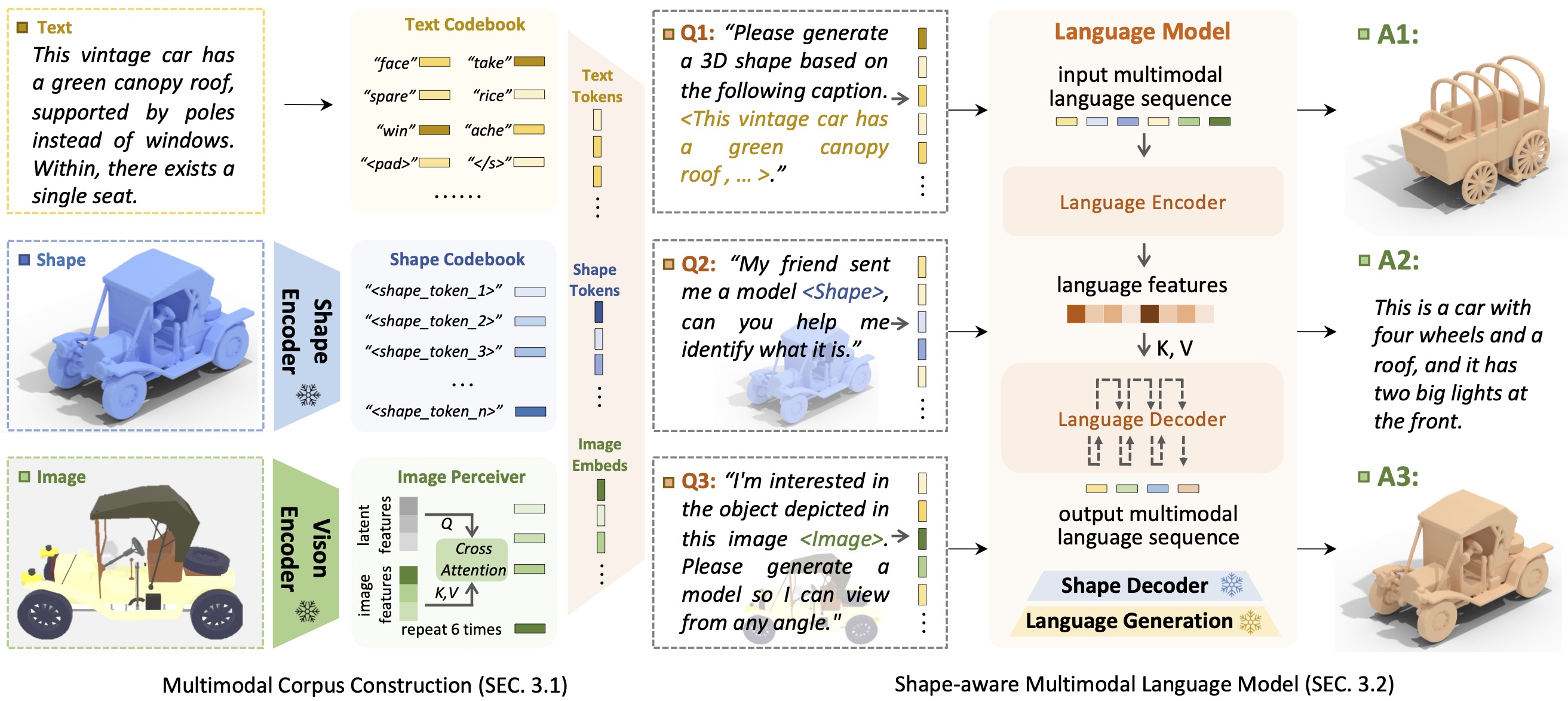
ВведениеShapeGPT — это унифицированная и удобная для пользователя мультимодальная языковая модель, ориентированная на формы, позволяющая создавать мультимодальный корпус и разрабатывать языковые модели с учетом форм для решения множества задач, связанных с фигурами .
Появление больших языковых моделей, обеспечивающих гибкость за счет подходов, основанных на инструкциях, произвело революцию во многих традиционных генеративных задачах, но большие модели для 3D-данных, особенно для комплексной обработки 3D-форм с другими модальностями, все еще недостаточно изучены. Благодаря генерированию форм на основе инструкций универсальные мультимодальные генеративные модели форм могут принести значительную пользу в различных областях, таких как виртуальное 3D-конструирование и сетевое проектирование. В этой работе мы представляем ShapeGPT, мультимодальную структуру с поддержкой фигур, позволяющую использовать сильные предварительно обученные языковые модели для решения множества задач, связанных с фигурами. В частности, ShapeGPT использует структуру «слово-предложение-абзац» для разделения непрерывных фигур на слова-формы, дополнительно собирает эти слова в предложения-формы, а также интегрирует форму с обучающим текстом для мультимодальных абзацев. Чтобы изучить эту модель языка форм, мы используем трехэтапную схему обучения, включая представление формы, мультимодальное выравнивание и генерацию на основе инструкций, чтобы согласовать кодовые книги языка форм и изучить сложные корреляции между этими модальностями. Обширные эксперименты показывают, что ShapeGPT достигает сопоставимой производительности при выполнении задач, связанных с фигурами, включая преобразование текста в форму, преобразование формы в текст, завершение формы и редактирование формы.
Если вы обнаружите, что наш код или статья помогают, пожалуйста, процитируйте:
@misc { yin2023shapegpt ,
title = { ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model } ,
author = { Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen } ,
year = { 2023 } ,
eprint = { 2311.17618 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}
Благодаря модели T5, Motion-GPT, Perceiver-IO и SDFusion наш код частично заимствован у них. Наш подход вдохновлен Unified-IO, Michelangelo, ShapeCrafter, Pix2Vox и 3DShape2VecSet.
Этот код распространяется по лицензии MIT.
Обратите внимание, что наш код зависит от других библиотек, включая PyTorch3D и PyTorch Lightning, и использует наборы данных, каждый из которых имеет свои собственные соответствующие лицензии, которым также необходимо следовать.


