multimedia gpt
1.0.0
Multimedia GPT соединяет ваш OpenAI GPT с изображением и звуком. Теперь вы можете отправлять изображения, аудиозаписи и документы в формате PDF, используя ключ API OpenAI, и получать ответ как в текстовом, так и в графическом формате. В настоящее время мы добавляем поддержку видео. Все это стало возможным благодаря менеджеру подсказок, созданному на основе Microsoft Visual ChatGPT.
В дополнение ко всем моделям Vision Foundation, упомянутым в Microsoft Visual ChatGPT, Multimedia GPT поддерживает OpenAI Whisper и OpenAI DALLE! Это означает, что вам больше не нужны собственные графические процессоры для распознавания голоса и генерации изображений (хотя вы все еще можете это сделать!)
Базовую модель чата можно настроить как любую OpenAI LLM , включая ChatGPT и GPT-4. По умолчанию мы используем text-davinci-003 .
Вы можете разветвить этот проект и добавить модели, подходящие для вашего случая использования. Простой способ сделать это — через llama_index. Вам нужно будет создать новый класс для вашей модели в model.py и добавить метод запуска run_<model_name> в multimedia_gpt.py . См. пример run_pdf .
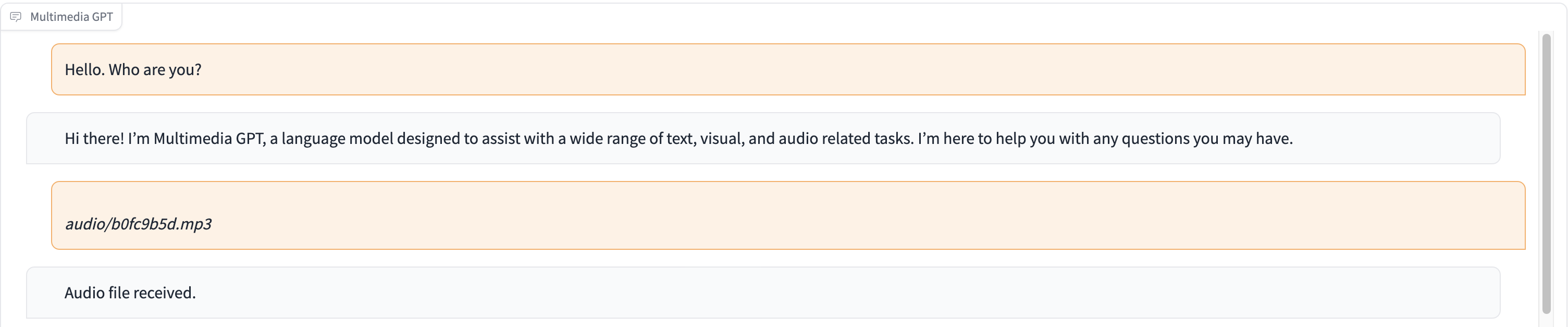
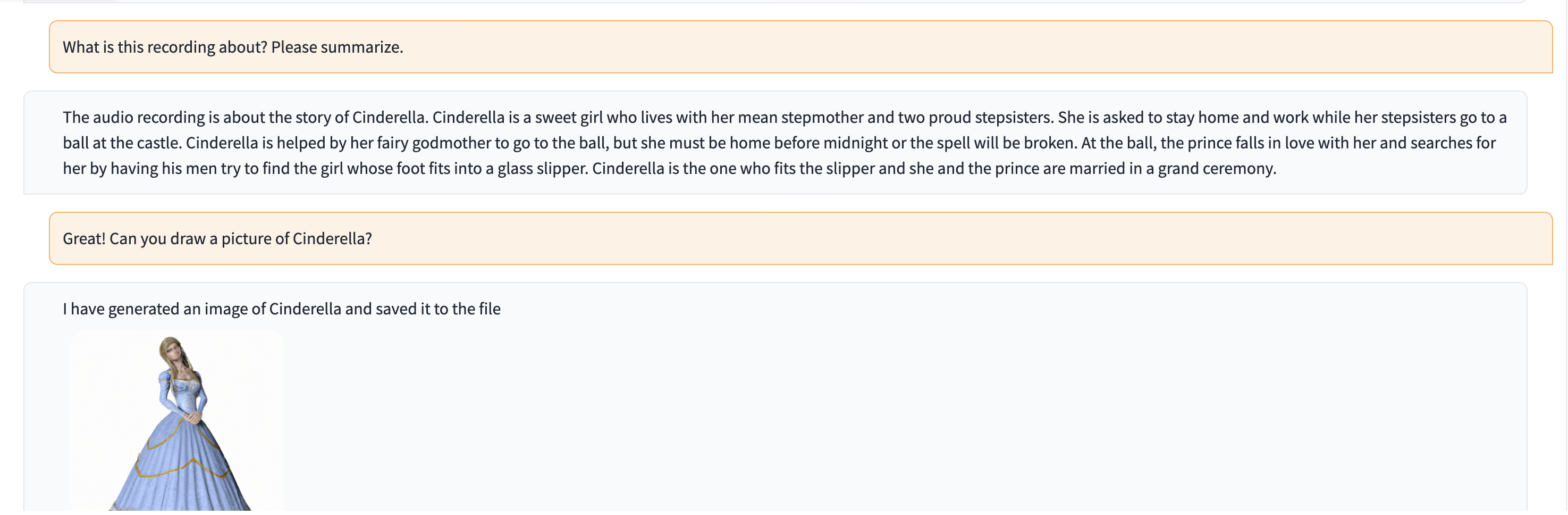
В этой демонстрации в ChatGPT передается запись человека, рассказывающего историю Золушки.
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). Этот проект является экспериментальной работой и не будет развернут в производственной среде. Наша цель — изучить силу подсказок.


