SwiftInfer
1.0.0
Streaming-LLM — это метод поддержки бесконечной длины входных данных для вывода LLM. Он использует Attention Sink , чтобы предотвратить схлопывание модели при смещении окна внимания. Исходная работа реализована в PyTorch, мы предлагаем SwiftInfer , реализацию TensorRT, чтобы сделать StreamingLLM более производственным. Наша реализация была основана на недавно выпущенном проекте TensorRT-LLM .
Мы используем API в TensorRT-LLM для построения модели и выполнения вывода. Поскольку API TensorRT-LLM нестабилен и быстро меняется, мы связываем нашу реализацию с коммитом 42af740db51d6f11442fd5509ef745a4c043ce51 версии v0.6.0 . Мы можем обновить этот репозиторий, поскольку API TensorRT-LLM станут более стабильными.
Если у вас есть сборка TensorRT-LLM V0.6.0 , просто запустите:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .В противном случае вам следует сначала установить TensorRT-LLM.
Если вы используете докер, вы можете выполнить установку TensorRT-LLM, чтобы установить TensorRT-LLM V0.6.0 .
Используя Docker, вы можете установить SwiftInfer, просто запустив:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . Если вы не используете Docker, мы предоставляем сценарий для автоматической установки TensorRT-LLM.
Предварительные условия
Пожалуйста, убедитесь, что у вас установлены следующие пакеты:
Убедитесь, что версия TensorRT >= 9.1.0 и набора инструментов CUDA >= 12.2.
Чтобы установить тензоррт:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )Чтобы загрузить nccl, перейдите на страницу загрузки NCCL.
Чтобы загрузить cudnn, перейдите на страницу загрузки cuDNN.
Команды
Прежде чем запускать следующие команды, убедитесь, что вы правильно установили nvcc . Чтобы проверить это, запустите:
nvcc --versionЧтобы установить TensorRT-LLM и SwiftInfer, запустите:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . Чтобы запустить пример Llama, вам необходимо сначала клонировать репозиторий Hugging Face для модели Meta-llama/Llama-2-7b-chat-hf или других вариантов на основе Llama, таких как lmsys/vicuna-7b-v1.3. Затем вы можете запустить следующую команду для создания движка TensorRT. Вам необходимо заменить <model-dir> фактическим путем к модели Llama.
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1Далее вам необходимо загрузить данные MT-Bench, предоставленные LMSYS-FastChat.
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonlНаконец, вы готовы запустить пример Llama с помощью следующей команды.
❗️❗️❗️Перед этим обратите внимание, что:
only_n_first используется для управления количеством оцениваемых выборок. Если вы хотите оценить все образцы, удалите этот аргумент. python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5Вы должны ожидать увидеть следующее поколение:
Мы сравнили наши реализации Streaming-LLM с исходной версией PyTorch. Команда тестирования для нашей реализации приведена в разделе «Пример запуска Llama», а команда для исходной реализации PyTorch — в папке torch_streamingllm. Используемое оборудование указано ниже:
Результаты (20 раундов бесед):
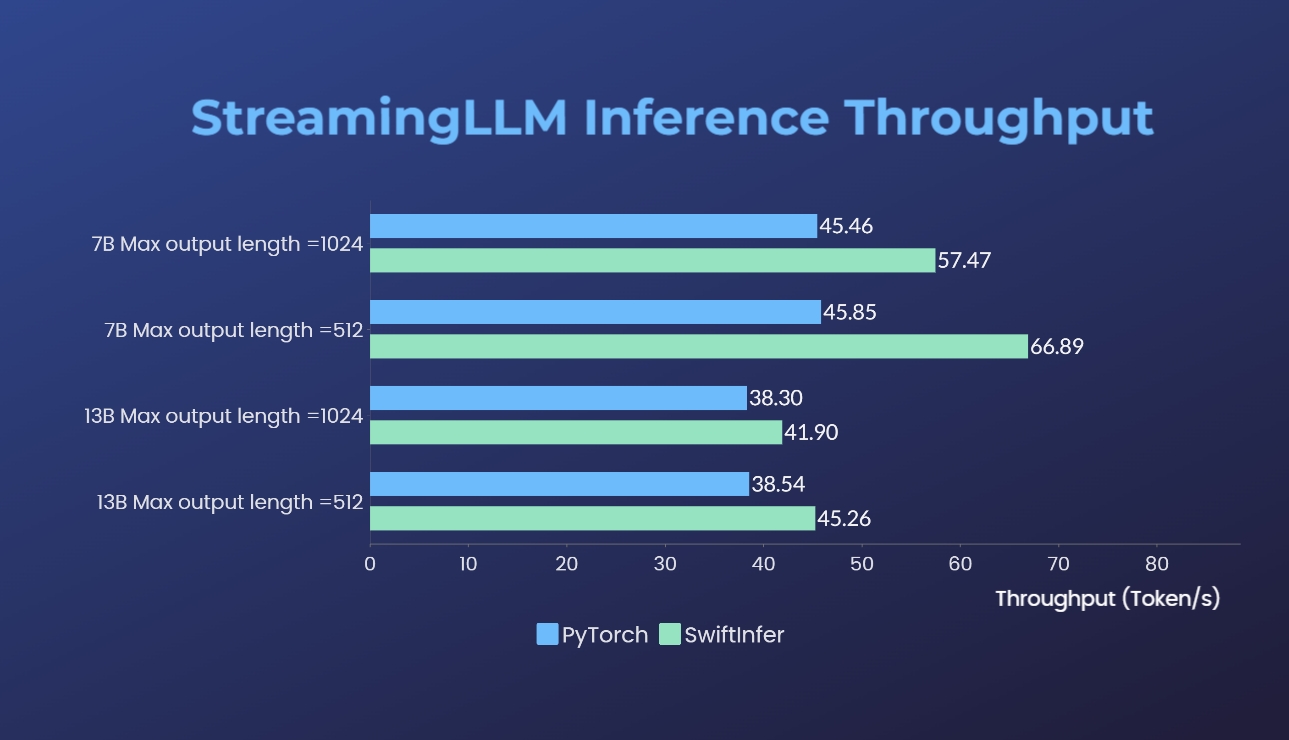
Мы все еще работаем над дальнейшим улучшением производительности и адаптацией к API TensorRT V0.7.1. Мы также заметили, что TensorRT-LLM в своем примере интегрировал StreamingLLM, но кажется, что он больше подходит для генерации одного текста, а не для многораундовых разговоров.
Эта работа вдохновлена Streaming-LLM, чтобы сделать ее пригодной для использования в производстве. На протяжении всего процесса разработки мы ссылались на следующие материалы и хотим отметить их усилия и вклад в сообщество разработчиков ПО с открытым исходным кодом и научные круги.
Если вы найдете StreamingLLM и нашу реализацию TensorRT полезными, пожалуйста, укажите наш репозиторий и оригинальную работу, предложенную Сяо и др. из лаборатории Хана Массачусетского технологического института.
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

