paxml
paxml release 1.4.0
Pax — это платформа для настройки и проведения экспериментов по машинному обучению поверх Jax.
Мы обращаемся к этой странице для получения более подробной документации о запуске проекта Cloud TPU. Следующей команды достаточно для создания виртуальной машины Cloud TPU с 8 ядрами на корпоративной машине.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR Если вы используете фрагменты TPU Pod, обратитесь к этому руководству. Запускайте все команды с локального компьютера с помощью gcloud с опцией --worker=all :
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "В следующих разделах краткого руководства предполагается, что вы работаете на TPU с одним хостом, поэтому вы можете подключиться к виртуальной машине по протоколу SSH и запускать там команды.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONEПосле подключения виртуальной машины по ssh вы можете установить стабильную версию paxml из PyPI или версию для разработчиков с github.
Для установки стабильной версии PyPI (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html Если у вас возникли проблемы с транзитивными зависимостями и вы используете собственную среду виртуальной машины Cloud TPU, перейдите в соответствующую ветку выпуска rX.YZ и загрузите paxml/pip_package/requirements.txt . Этот файл содержит точные версии всех транзитивных зависимостей, необходимых в собственной среде виртуальной машины Cloud TPU, в которой мы создаем/тестируем соответствующий выпуск.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtДля установки версии для разработчиков с github и для удобства редактирования кода:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=TrueПосетите нашу папку документации для получения документации и руководств по Jupyter Notebook. В следующем разделе приведены инструкции по запуску Jupyter Notebooks на виртуальной машине Cloud TPU.
Вы можете запустить примеры записных книжек на виртуальной машине TPU, в которой вы только что установили paxml. ####Шаги по включению блокнота в v4-8
ssh в виртуальной машине TPU с переадресацией портов gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
установите блокнот Jupyter на виртуальную машину TPU и понизьте версию markupsafe
pip install notebook
pip install markupsafe==2.0.1
экспортировать путь jupyter export PATH=/home/$USER/.local/bin:$PATH
scp примеры блокнотов на вашу виртуальную машину TPU gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
запустите Jupyter Notebook из виртуальной машины TPU и запишите токен, сгенерированный Jupyter Notebook jupyter notebook --no-browser --port=8080
затем в локальном браузере перейдите по адресу: http://localhost:8080/ и введите предоставленный токен.
Примечание. Если вам нужно начать использовать второй ноутбук, в то время как первый ноутбук все еще занимает TPU, вы можете запустить pkill -9 python3 чтобы освободить TPU.
Примечание. NVIDIA выпустила обновленную версию Pax с поддержкой H100 FP8 и значительными улучшениями производительности графического процессора. Посетите репозиторий NVIDIA Rosetta для получения более подробной информации и инструкций по использованию.
Рабочий процесс Profile Guided Latency Estimator (PGLE) измеряет фактическое время выполнения вычислений и коллективов, после чего информация профиля передается обратно в компилятор XLA для лучшего планирования.
Оценщик задержки по профилю можно использовать вручную или автоматически. В автоматическом режиме JAX соберет информацию о профиле и перекомпилирует модуль за один запуск. При этом в ручном режиме вам нужно запустить задачу дважды: первый раз для сбора и сохранения профилей и второй для компиляции и запуска с предоставленными данными.
Автоматический PGLE можно включить, установив следующие переменные среды:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
Или в JAX это можно установить следующим образом:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
Вы можете контролировать количество повторов, используемых для сбора данных профиля, изменяя JAX_PGLE_PROFILING_RUNS . Увеличение этого параметра приведет к улучшению информации профиля, но также увеличит количество неоптимизированных этапов обучения.
Параметры JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY позволяют использовать обратные вызовы хоста с автоматическим PGLE.
Уменьшение параметра JAX_PGLE_AGGREGATION_PERCENTILE может помочь в случае, когда производительность между шагами слишком зашумлена, чтобы отфильтровать нерелевантные показатели.
Внимание: Auto PGLE не работает для предварительно скомпилированных модулей. Поскольку JAX необходимо перекомпилировать модуль во время выполнения, автоматический PGLE не будет работать ни для AoT, ни в следующем случае:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
Если вы все еще хотите использовать оценщик задержки на основе профиля вручную, рабочий процесс в XLA/GPU выглядит следующим образом:
Вы можете сделать это, установив:
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) После этого шага вы получите файл profile.pb под rundir напечатанным в коде.
Вам необходимо передать файл profile.pb в флаг --xla_gpu_pgle_profile_file_or_directory_path .
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " Чтобы включить ведение журнала в XLA и проверить, хорош ли профиль, установите уровень ведения журнала, включив INFO :
export TF_CPP_MIN_LOG_LEVEL=0Запустите реальный рабочий процесс, если вы нашли эти журналы в работающем журнале, это означает, что профилировщик используется в планировщике скрытия задержки:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax работает на Jax, подробности о запуске заданий Jax в Cloud TPU можно найти здесь, а также подробности о запуске заданий Jax в модуле Cloud TPU здесь.
Если вы столкнулись с ошибками зависимостей, обратитесь к файлу requirements.txt в ветке, соответствующей стабильной версии, которую вы устанавливаете. Например, для стабильной версии 0.4.0 используйте ветку r0.4.0 и обратитесь к файлу require.txt для получения точных версий зависимостей, используемых для стабильной версии.
Вот несколько примеров сходимости набора данных c4.
Вы можете запустить модель параметров 1B в наборе данных c4 на TPU v4-8 используя конфигурацию C4Spmd1BAdam4Replicas из c4.py следующим образом:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket > Вы можете наблюдать кривую потерь и график log perplexity следующим образом:
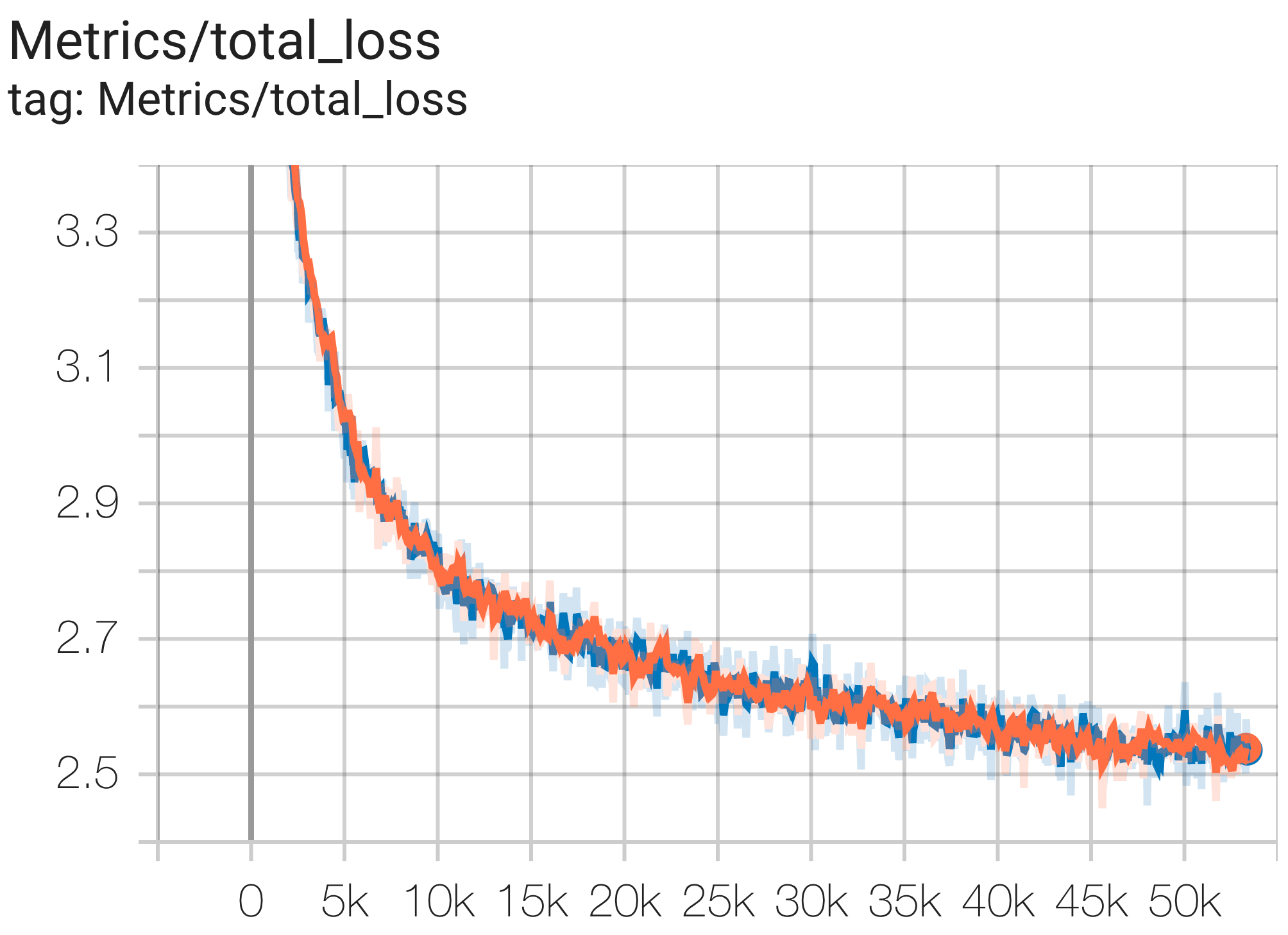
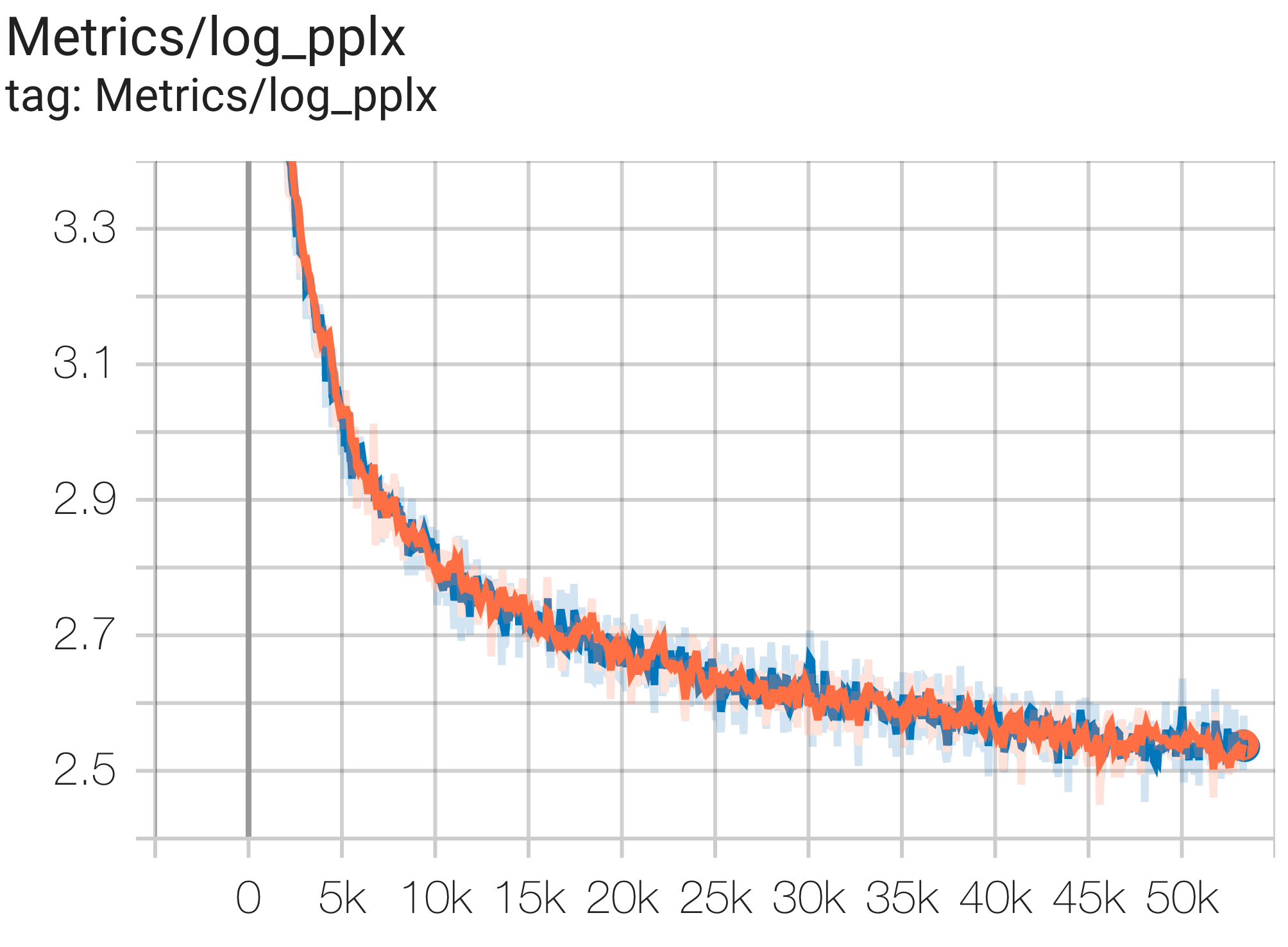
Вы можете запустить модель параметров 16B в наборе данных c4 на TPU v4-64 используя конфигурацию C4Spmd16BAdam32Replicas из c4.py следующим образом:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket > Вы можете наблюдать кривую потерь и график log perplexity следующим образом:
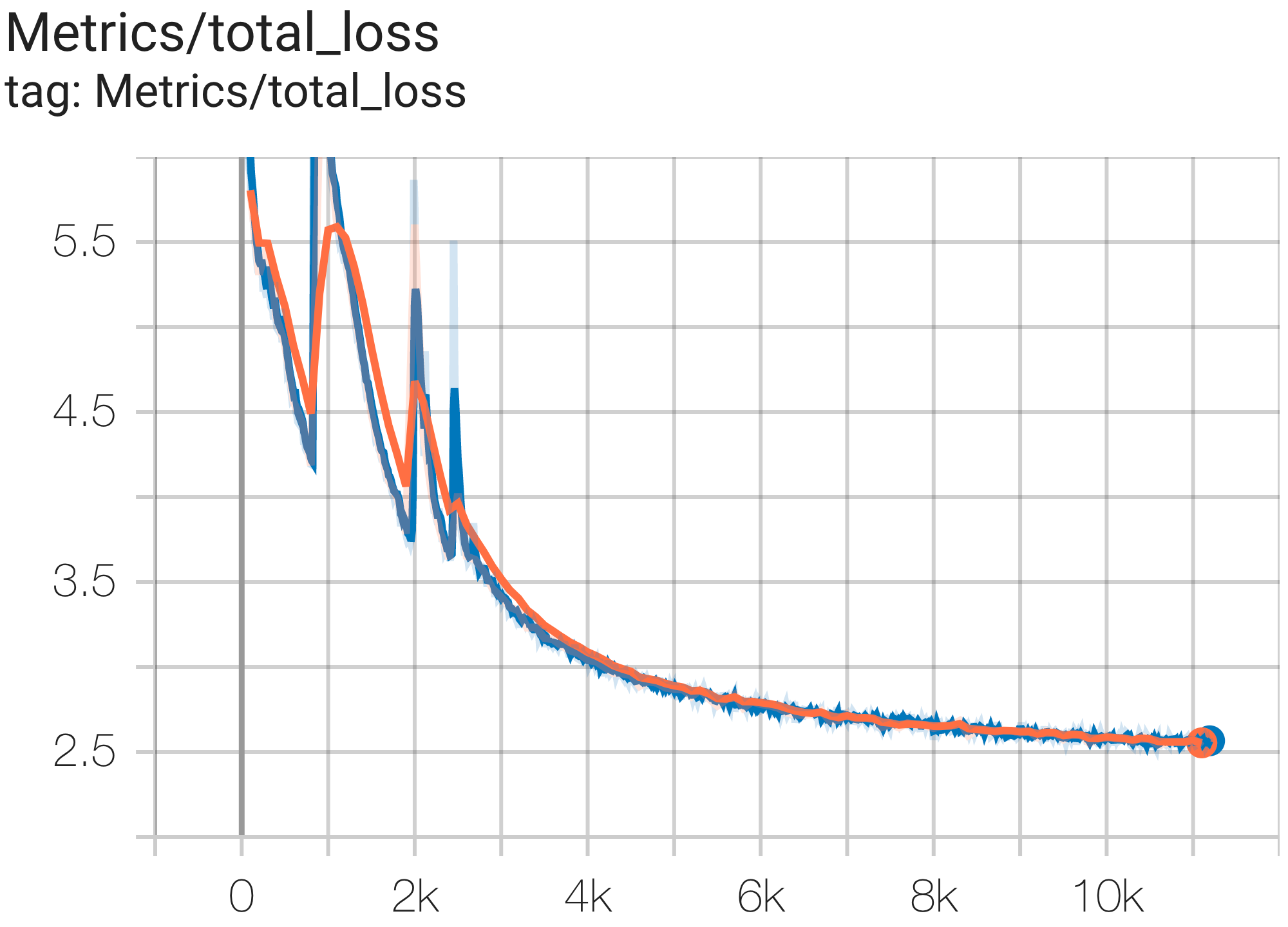
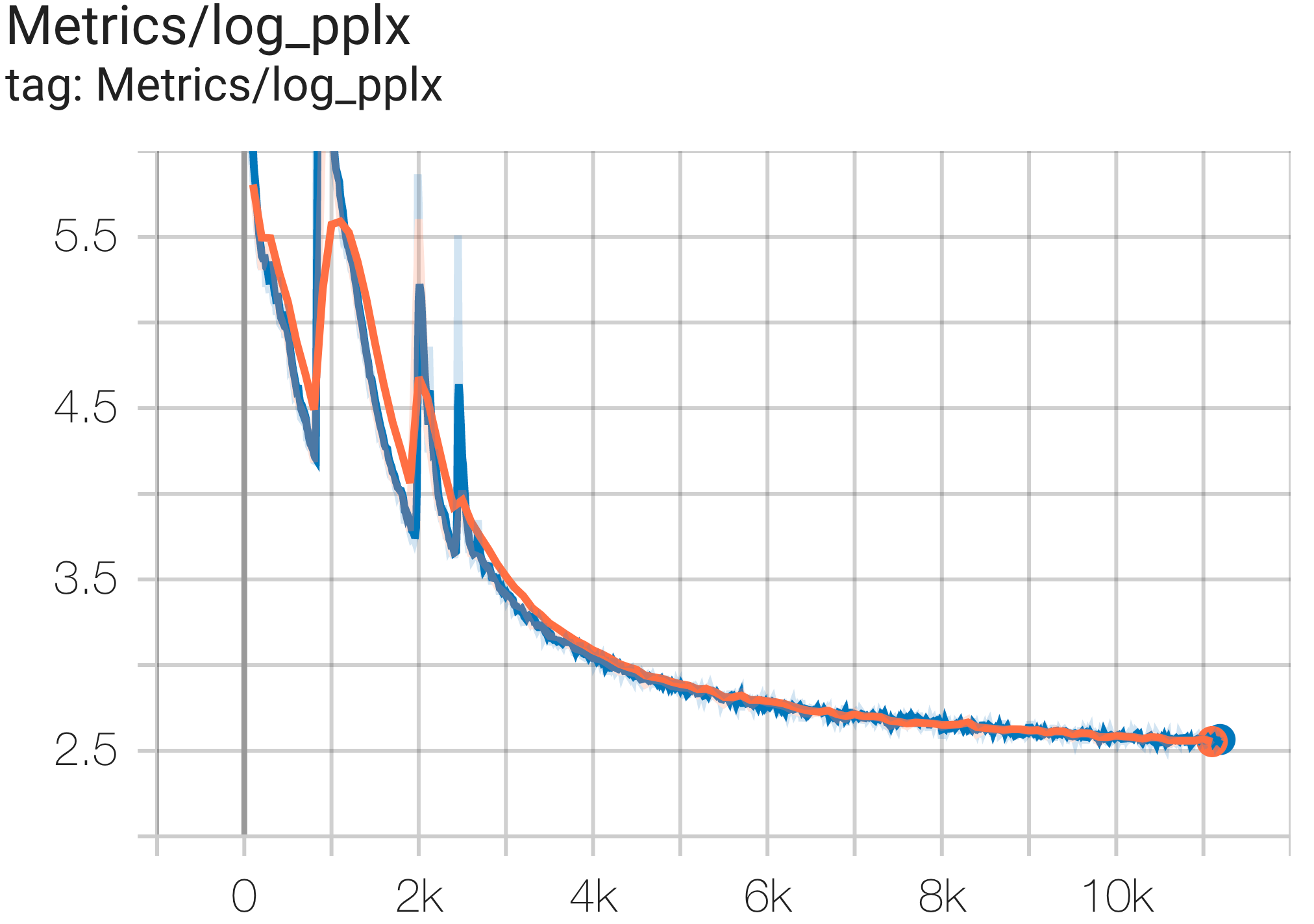
Вы можете запустить модель GPT3-XL в наборе данных c4 на TPU v4-128 используя конфигурацию C4SpmdPipelineGpt3SmallAdam64Replicas из c4.py следующим образом:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket > Вы можете наблюдать кривую потерь и график log perplexity следующим образом:
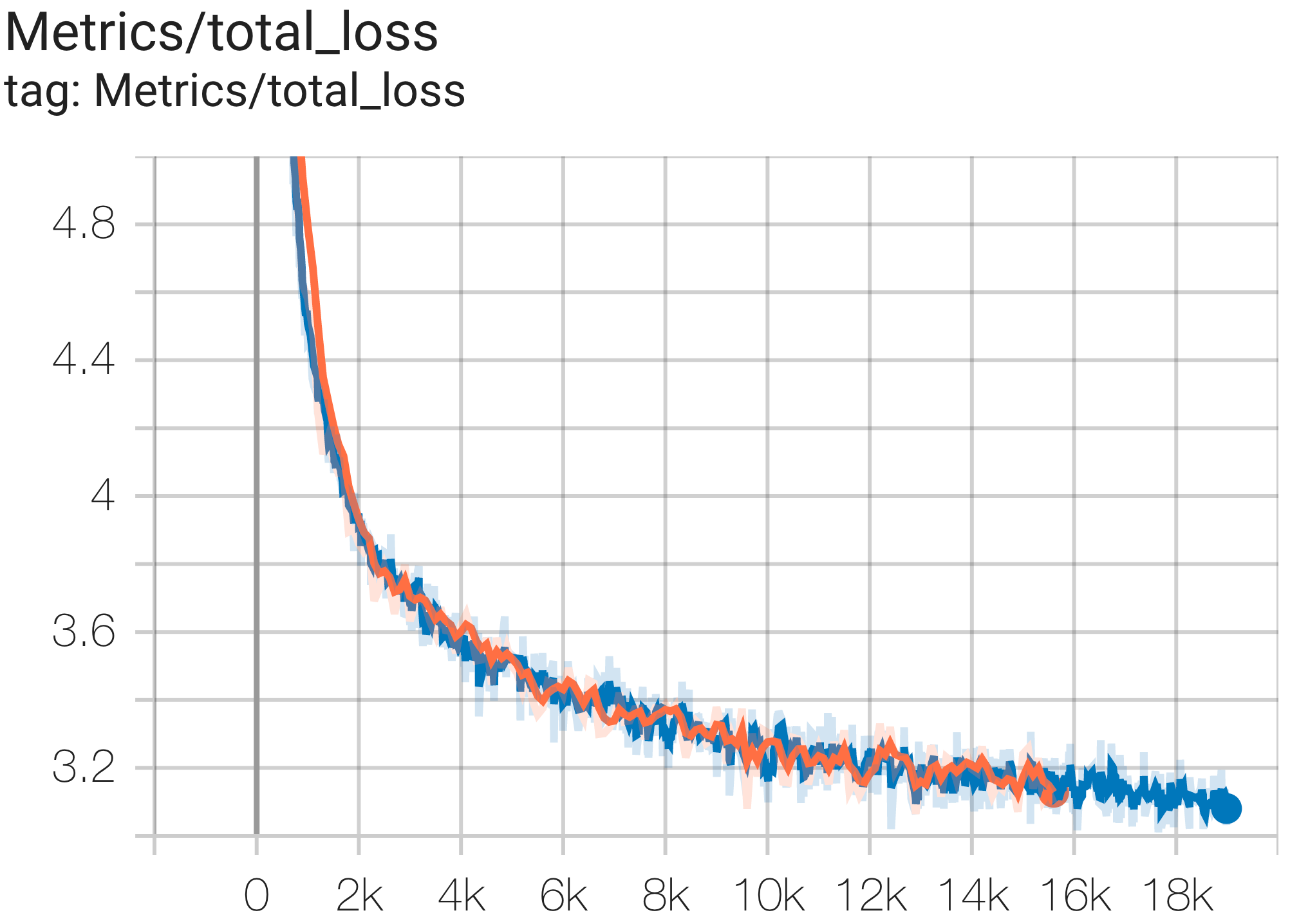
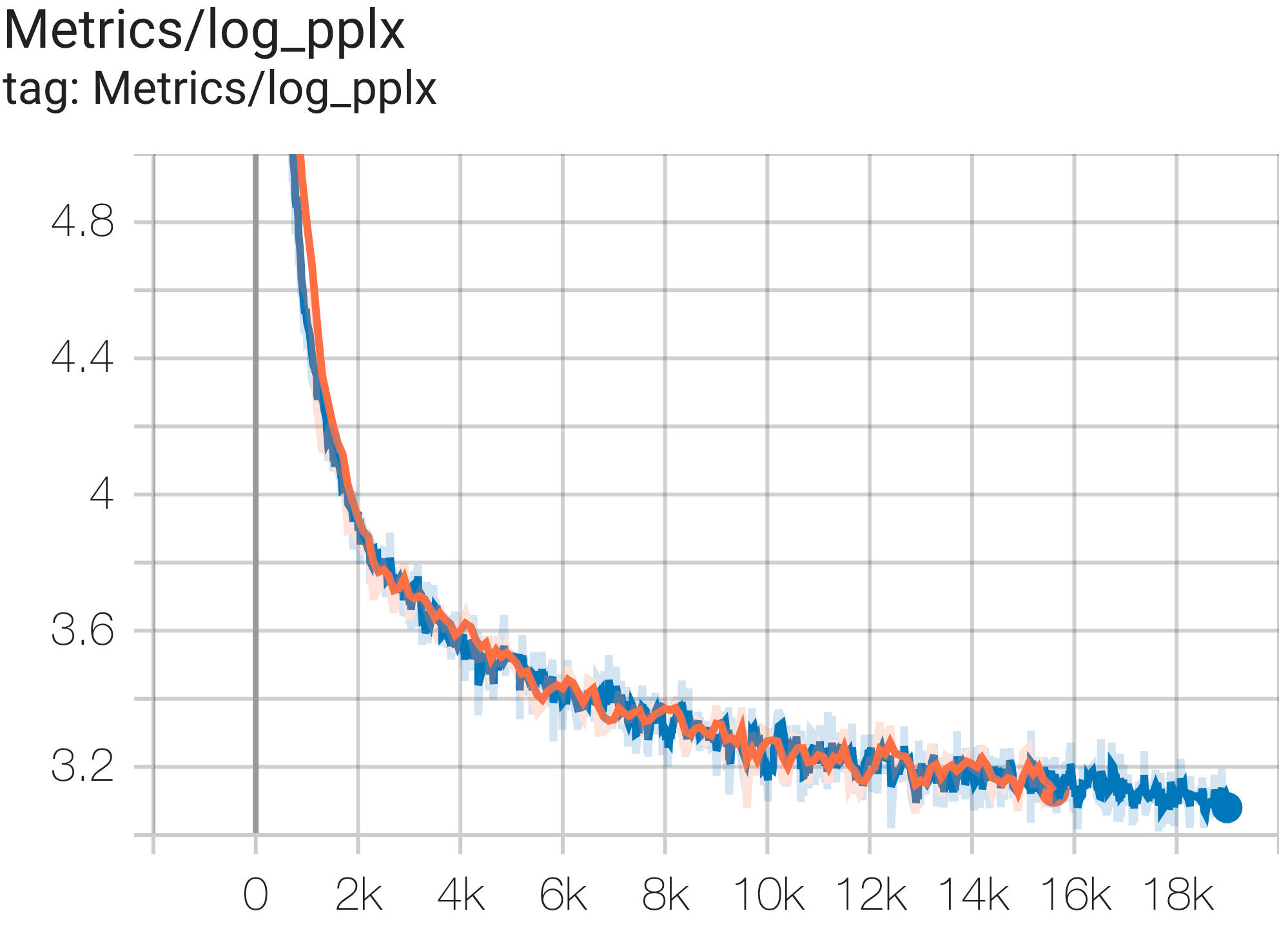
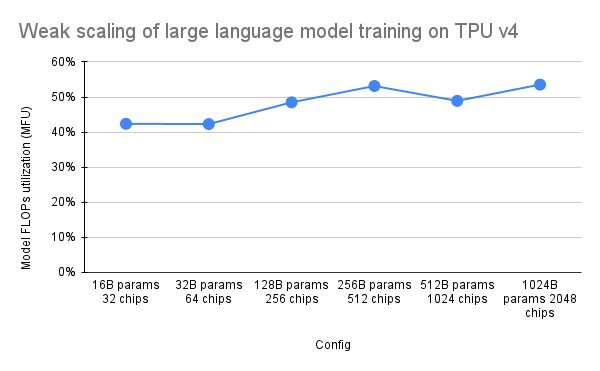
В документе PaLM был представлен показатель эффективности под названием Model FLOPs Utilization (MFU). Это измеряется как отношение наблюдаемой пропускной способности (например, в токенах в секунду для языковой модели) к теоретической максимальной пропускной способности системы, использующей 100% пиковых FLOP. Он отличается от других способов измерения использования вычислительных ресурсов, поскольку не включает FLOP, потраченные на повторную материализацию активации во время обратного прохода, а это означает, что эффективность, измеряемая MFU, напрямую преобразуется в скорость сквозного обучения.
Чтобы оценить MFU ключевого класса рабочих нагрузок на модулях TPU v4 с Pax, мы провели кампанию по углубленному тестированию серии конфигураций языковой модели Transformer (GPT), предназначенных только для декодера, размер которых варьируется от миллиардов до триллионов параметров. в наборе данных c4. На следующем графике показана эффективность обучения с использованием шаблона «слабого масштабирования», где мы увеличивали размер модели пропорционально количеству используемых чипов.
Конфигурации мультисрезов в этом репозитории относятся к 1. Конфигурациям одиночных срезов для архитектуры синтаксиса/модели и 2. Репозиторию MaxText для значений конфигурации.
Мы предоставляем примеры запуска под c4_multislice.py` в качестве отправной точки для Pax в multislice.
Мы обращаемся к этой странице для получения более подробной документации об использовании ресурсов в очереди для многосрезового проекта Cloud TPU. Ниже показаны шаги, необходимые для настройки TPU для запуска примеров конфигураций в этом репозитории.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run Скажем, для запуска C4Spmd22BAdam2xv4_128 на двух фрагментах v4-128 вам необходимо настроить TPU следующим образом:
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX Описанные ранее команды настройки необходимо запускать на ВСЕХ рабочих процессах во ВСЕХ слайсах. Вы можете: 1) подключаться по SSH к каждому работнику и каждому фрагменту индивидуально; или 2) используйте цикл for с флагом --worker=all в качестве следующей команды.
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done Чтобы запустить мультисрезовые конфигурации, откройте столько же терминалов, сколько у вас $NODE_COUNT. Для наших экспериментов на двух срезах ( C4Spmd22BAdam2xv4_128 ) откройте два терминала. Затем запустите каждую из этих команд индивидуально с каждого терминала.
Из терминала 0 запустите команду обучения для среза 0 следующим образом:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Из Терминала 1 одновременно запустите команду обучения для среза 1 следующим образом:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "В этой таблице подробно описано, как имена переменных MaxText были переведены в Pax.
Обратите внимание, что MaxText имеет «масштаб», который умножается на несколько параметров (base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads) для получения окончательных значений.
Еще следует упомянуть: хотя Pax охватывает DCN и ICN MESH_SHAPE как массив, в MaxText есть отдельные переменные data_parallelism, fsdp_parallelism и tensor_parallelism для DCN и ICI. Поскольку по умолчанию для этих значений установлено значение 1, в эту таблицу перевода записываются только переменные со значением больше 1.
То есть ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] и DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| Пакс C4Spmd22BAdam2xv4_128 | Макстекст 2xv4-128.sh | (после нанесения масштаба) | ||
|---|---|---|---|---|
| масштаб (применяется к следующим 4 переменным) | 3 | |||
| NUM_LAYERS | 48 | base_num_decoder_layers | 16 | 48 |
| МОДЕЛЬ_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| HIDDEN_DIMS | 24576 | МОДЕЛЬ_DIMS * 4 (= base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | head_dim | 256 | |
| PERCORE_BATCH_SIZE | 16 | per_device_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | max_target_length | 1024 | |
| VOCAB_SIZE | 32768 | vocab_size | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | dtype | bfloat16 | |
| USE_REPEATED_LAYER | истинный | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_parallelism | 64 | |
| DCN_MESH_SHAPE | [2, 1, 1] | dcn_data_parallelism | 2 |
Ввод — это экземпляр класса BaseInput для ввода данных в модель для обучения/оценки/декодирования.
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass Он действует как итератор: get_next() возвращает NestedMap , где каждое поле представляет собой числовой массив с размером пакета в качестве ведущего измерения.
Каждый ввод настраивается подклассом BaseInput.HParams . На этой странице мы используем p для обозначения экземпляра BaseInput.Params , и он создает экземпляр input .
В Pax данные всегда многохостовые: для каждого процесса Jax будет создан отдельный, независимый input экземпляр. Их параметры будут иметь разные значения p.infeed_host_index , автоматически установленные Pax.
Следовательно, размер локального пакета, видимый на каждом хосте, равен p.batch_size , а размер глобального пакета — (p.batch_size * p.num_infeed_hosts) . Часто можно увидеть, что для p.batch_size установлено значение jax.local_device_count() * PERCORE_BATCH_SIZE .
Из-за такой многохостовой природы input должны быть правильно сегментированы.
Для обучения каждый input никогда не должен выдавать одинаковые пакеты, а для оценки конечного набора данных каждый input должен завершаться после одинакового количества пакетов. Лучшее решение — правильно распределить данные во входной реализации, чтобы каждый input на разных хостах не перекрывался. В противном случае можно также использовать разные случайные начальные числа, чтобы избежать дублирования партий во время обучения.
input.reset() никогда не вызывается для обучающих данных, но может для проверки (или декодирования) данных.
Для каждого запуска оценки (или декодирования) Pax извлекает N пакетов из input , вызывая input.get_next() N раз. Количество используемых пакетов N может быть фиксированным числом, указанным пользователем через p.eval_loop_num_batches ; или N может быть динамическим ( p.eval_loop_num_batches=None ), т.е. мы вызываем input.get_next() до тех пор, пока не исчерпаем все его данные (путем вызова StopIteration или tf.errors.OutOfRange ).
Если p.reset_for_eval=True , p.eval_loop_num_batches игнорируется, а N определяется динамически как количество пакетов для исчерпания данных. В этом случае для параметра p.repeat должно быть установлено значение False, иначе это приведет к бесконечному декодированию/оценке.
Если p.reset_for_eval=False , Pax будет получать пакеты p.eval_loop_num_batches . Это значение следует установить с помощью p.repeat=True , чтобы данные не исчерпались преждевременно.
Обратите внимание, что для входных данных LingvoEvalAdaptor требуется p.reset_for_eval=True .
N : статический | N : динамический | |
|---|---|---|
p.reset_for_eval=True | Каждый запуск оценки использует | Одна эпоха на прогон оценки. |
:: первые N партий. Не: eval_loop_num_batches : | ||
| :: пока поддерживается. : игнорируется. Ввод должен: | ||
| : : : быть конечным : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | Каждый прогон оценки использует | Не поддерживается. |
: : непересекающиеся N : : | ||
| :: партии в прокате: : | ||
| : : на основе : : | ||
: : eval_loop_num_batches : : | ||
| : : . Ввод должен повторяться : : | ||
| : : на неопределенный срок : : | ||
: : ( p.repeat=True ) или : : | ||
| : : в противном случае может повыситься : : | ||
| : : исключение : : |
Если декодирование/оценка выполняется ровно в одну эпоху (т. е. когда p.reset_for_eval=True ), ввод должен правильно обрабатывать сегментирование, чтобы каждый сегмент поднимался на одном и том же шаге после создания точно такого же количества пакетов. Обычно это означает, что входные данные должны дополнять оценочные данные. Это делается автоматически SeqIOInput и LingvoEvalAdaptor (подробнее см. ниже).
Для большинства входных данных мы вызываем get_next() только для получения пакетов данных. Исключением является один тип оценочных данных, где «как вычислять метрики» также определяется для входного объекта.
Это поддерживается только с помощью SeqIOInput , который определяет некоторый канонический тест оценки. В частности, Pax использует predict_metric_fns и score_metric_fns() определенные в задаче SeqIO, для вычисления показателей оценки (хотя Pax не зависит напрямую от оценщика SeqIO).
Когда модель использует несколько входных данных, либо между обучением и оценкой, либо с разными данными обучения между предобучением и точной настройкой, пользователи должны убедиться, что токенизаторы, используемые входными данными, идентичны, особенно при импорте различных входных данных, реализованных другими.
Пользователи могут проверить работоспособность токенизаторов, декодировав некоторые идентификаторы с помощью input.ids_to_strings() .
Всегда полезно проверить работоспособность данных, просмотрев несколько партий. Пользователи могут легко воспроизвести параметр в колабе и проверить данные:
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) В обучающих данных обычно не следует использовать фиксированное случайное начальное число. Это связано с тем, что если задание обучения прерывается, данные обучения начнут повторяться. В частности, для входных данных Lingvo мы рекомендуем установить p.input.file_random_seed = 0 для обучающих данных.
Чтобы проверить, правильно ли обрабатывается сегментирование, пользователи могут вручную установить разные значения для p.num_infeed_hosts, p.infeed_host_index и посмотреть, отправляют ли экземпляры входных данных разные пакеты.
Pax поддерживает 3 типа ввода: SeqIO, Lingvo и пользовательский.
SeqIOInput можно использовать для импорта наборов данных.
Входы SeqIO автоматически обрабатывают правильное сегментирование и заполнение оценочных данных.
LingvoInputAdaptor можно использовать для импорта наборов данных.
Ввод полностью делегируется реализации Lingvo, которая может автоматически обрабатывать или не обрабатывать сегментирование.
Для реализации ввода Lingvo на основе GenericInput с использованием фиксированного packing_factor мы рекомендуем использовать LingvoInputAdaptorNewBatchSize чтобы указать больший размер пакета для внутреннего ввода Lingvo и указать желаемый (обычно намного меньший) размер пакета в p.batch_size .
Для данных оценки мы рекомендуем использовать LingvoEvalAdaptor для обработки сегментирования и заполнения при выполнении оценки в течение одной эпохи.
Пользовательский подкласс BaseInput . Пользователи реализуют свой собственный подкласс, обычно с помощью tf.data или SeqIO.
Пользователи также могут наследовать существующий класс ввода, чтобы настроить только постобработку пакетов. Например:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchГиперпараметры являются важной частью определения моделей и настройки экспериментов.
Для лучшей интеграции с инструментами Python Pax/Praxis использует стиль конфигурации гиперпараметров на основе Pythonic-классов данных.
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0Также возможно вкладывать классы данных HParams: в приведенном ниже примере атрибут Linear_tpl является вложенным Linear.HParams.
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )Слой представляет собой произвольную функцию, возможно, с обучаемыми параметрами. Слой может содержать другие слои в качестве дочерних. Слои являются важными строительными блоками моделей. Слои наследуются от Flax nn.Module.
Обычно слои определяют два метода:
Этот метод создает обучаемые веса и дочерние слои.
Этот метод определяет функцию прямого распространения, вычисляя некоторый результат на основе входных данных. Кроме того, fprop может добавлять сводки или отслеживать вспомогательные потери.
Fiddle — это библиотека конфигурации Python с открытым исходным кодом, предназначенная для приложений машинного обучения. Pax/Praxis поддерживает взаимодействие с Fiddle Config/Partial(s) и некоторые расширенные функции, такие как быстрая проверка ошибок и общие параметры.
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )Используя Fiddle, слои можно настроить для совместного использования (например, создавать экземпляры только один раз с общими обучаемыми весами).
Модель определяет исключительно сеть, обычно набор слоев, и определяет интерфейсы для взаимодействия с моделью, такие как декодирование и т. д.
Некоторые примеры базовых моделей включают в себя:
Задача содержит еще одну модель и обучающегося/оптимизатора. Самый простой подкласс Task — это SingleTask , для которого требуются следующие Hparams:
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| Версия PyPI | Совершить |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


