BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT — это исследовательский проект, предназначенный для постепенного создания языковой модели, подобной GPT. Проект начинается с простой модели Biggram и постепенно включает в себя передовые концепции архитектуры модели Transformer.
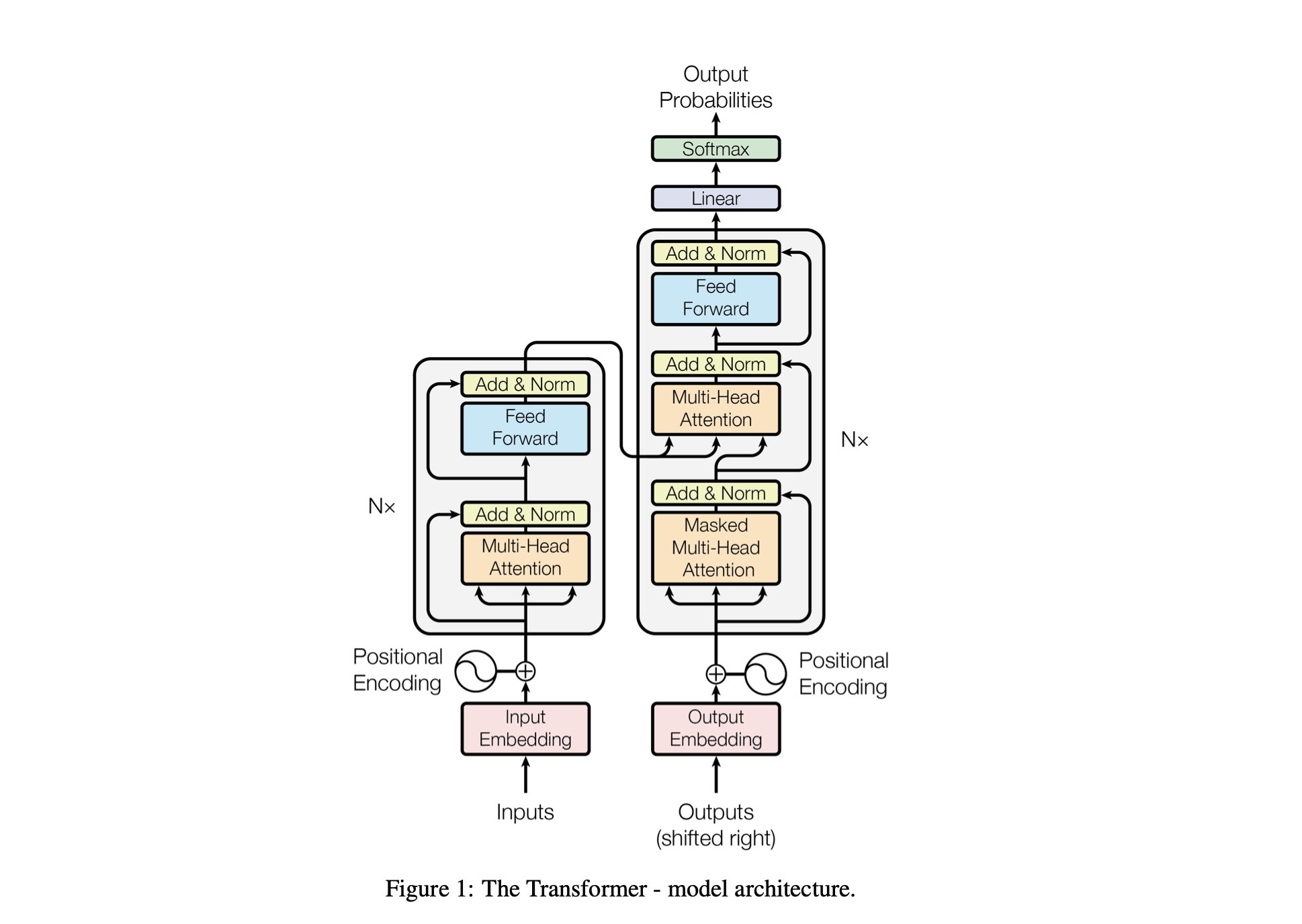
Производительность модели настраивается с использованием следующих гиперпараметров:
batch_size : количество последовательностей, обрабатываемых параллельно во время обучения.block_size : длина последовательностей, обрабатываемых моделью.d_model : количество функций в модели (размер вложений)d_k : количество функций на одну голову внимания.num_iter : общее количество итераций обучения, которые выполнит модель.Nx : количество блоков или слоев трансформатора в модели.eval_interval : интервал, в котором вычисляются и оцениваются потери модели.lr_rate : скорость обучения оптимизатора Адама.device : автоматически устанавливается значение 'cuda' , если доступен совместимый графический процессор, в противном случае по умолчанию используется значение 'cpu' .eval_iters : количество итераций, по которым усредняется потеря оценки.h : Количество головок внимания в механизме внимания с несколькими головками.dropout_rate : частота отсева, используемая во время обучения, чтобы предотвратить переобучение.Эти гиперпараметры были тщательно выбраны, чтобы сбалансировать способность модели учиться на данных без переобучения и эффективно управлять вычислительными ресурсами.
| Гиперпараметр | Модель процессора | Модель графического процессора |
|---|---|---|
device | 'Процессор' | «cuda», если доступно, иначе «процессор» |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10000 | 10000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0,2 | 0,2 |
lr_rate | 0,005 (5е-3) | 0,001 (1е-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int и int_to_chars .encode и обратно с помощью функции decode .train_data ) и проверочный ( valid_data ) наборы.get_batch подготавливает данные для обучения в мини-пакетах.BigramLM .Мини-пакетирование — это метод машинного обучения, при котором обучающие данные делятся на небольшие пакеты. Каждый мини-пакет обрабатывается отдельно во время обучения модели. Этот подход помогает:
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | Фактор | Небольшой размер партии | Большой размер партии |
|---|---|---|
| Градиентный шум | Выше (больше различий в обновлениях) | Ниже (более последовательные обновления) |
| Конвергенция | Склонен искать больше решений, включая более плоские минимумы. | Часто сходится к более резким минимумам |
| Обобщение | Потенциально лучше (из-за более плоских минимумов) | Потенциально хуже (из-за более резких минимумов) |
| Предвзятость | Ниже (менее вероятно переподгонка к шаблонам обучающих данных) | Выше (может соответствовать шаблонам обучающих данных) |
| Дисперсия | Выше (из-за большего исследования пространства решений) | Ниже (из-за меньшего исследования пространства решений) |
| Вычислительная стоимость | Выше за эпоху (больше обновлений) | Меньше за эпоху (меньше обновлений) |
| Использование памяти | Ниже | Выше |
Функция estimate_loss вычисляет средние потери для модели за указанное количество итераций (eval_iters). Он используется для оценки производительности модели, не затрагивая ее параметры. Модель переведена в режим оценки, чтобы отключить определенные уровни, такие как отсев, для последовательного расчета потерь. После вычисления средних потерь для данных обучения и проверки модель возвращается в режим обучения. Эта функция необходима для контроля тренировочного процесса и внесения корректировок при необходимости.
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses Позиционное кодирование : добавление позиционной информации в модель с помощью positional_encodings_table в классе BigramLM . Мы добавляем позиционные кодировки к встраиваниям наших персонажей, как в архитектуре трансформера.
Здесь мы настраиваем и используем оптимизатор AdamW для обучения модели нейронной сети в PyTorch. Оптимизатор Адама предпочтителен во многих сценариях глубокого обучения, поскольку он сочетает в себе преимущества двух других расширений стохастического градиентного спуска: AdaGrad и RMSProp. Адам вычисляет скорость адаптивного обучения для каждого параметра. В дополнение к хранению экспоненциально убывающего среднего значения прошлых квадратов градиентов, такого как RMSProp, Адам также сохраняет экспоненциально убывающее среднее значение прошлых градиентов, аналогично импульсу. Это позволяет оптимизатору регулировать скорость обучения для каждого веса нейронной сети, что может привести к более эффективному обучению на сложных наборах данных и архитектурах.
AdamW изменяет способ включения затухания веса в процесс оптимизации, решая проблему исходного оптимизатора Адама, где затухание веса плохо отделяется от обновлений градиента, что приводит к неоптимальному применению регуляризации. Использование AdamW иногда может привести к повышению производительности обучения и обобщению невидимых данных. Мы выбрали AdamW из-за его способности более эффективно справляться с уменьшением веса, чем стандартный оптимизатор Адама, что потенциально может привести к улучшению обучения и обобщения модели.
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()Self-Attention — это механизм, который позволяет модели по-разному взвешивать важность различных частей входных данных. Это ключевой компонент архитектуры Transformer, позволяющий модели сосредоточиться на соответствующих частях входной последовательности для составления прогнозов.
Внимание к скалярному произведению : простой механизм внимания, который вычисляет взвешенную сумму значений на основе скалярного произведения между запросами и ключами.
Масштабированное внимание к скалярному произведению : усовершенствование по сравнению с вниманием к скалярному произведению, которое уменьшает скалярное произведение в зависимости от размерности клавиш, не позволяя градиентам становиться слишком маленькими во время обучения.
OneHeadSelfAttention : реализация однонаправленного механизма самообслуживания, который позволяет модели обслуживать разные позиции входной последовательности. Класс SelfAttention демонстрирует интуитивно понятный механизм внимания и его масштабированную версию.
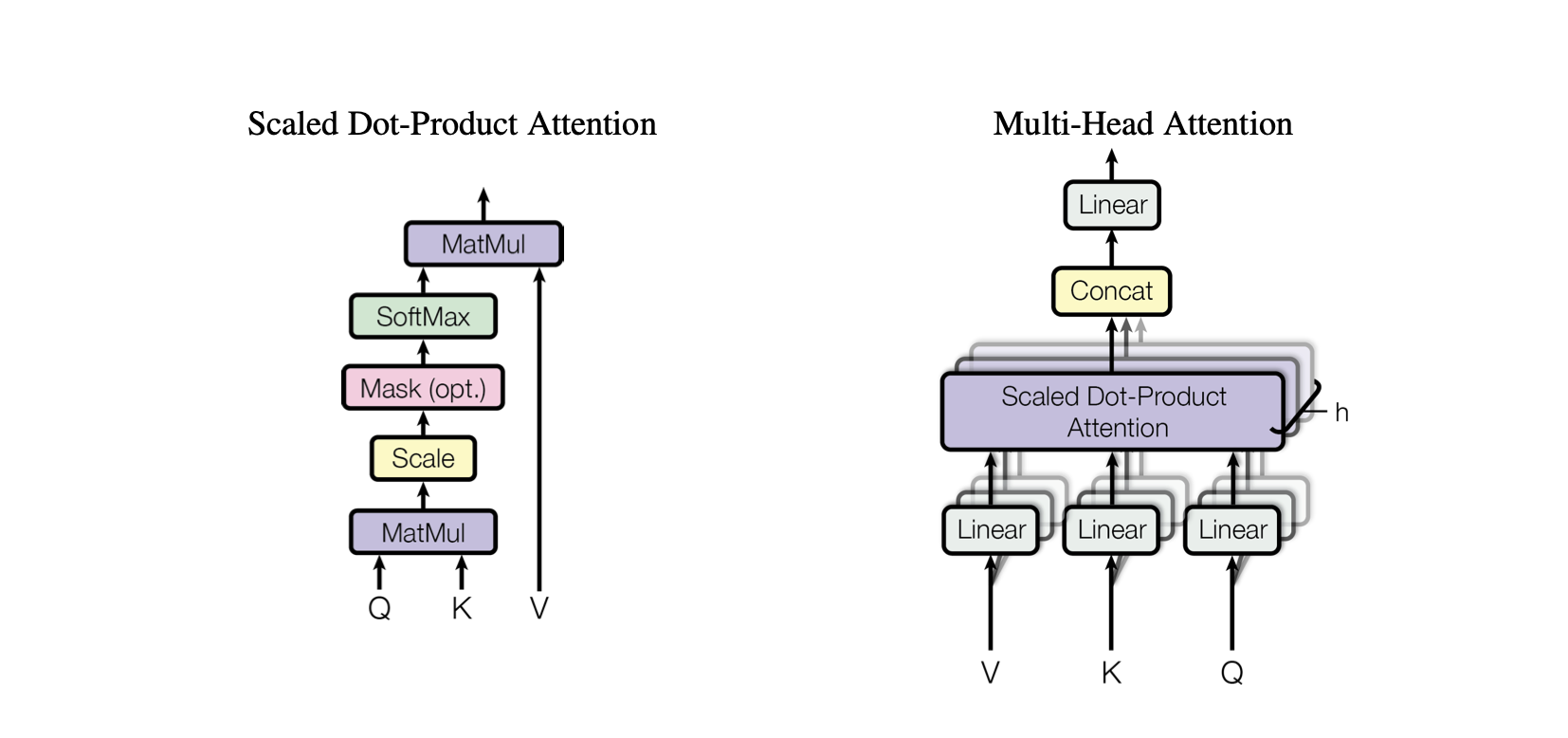
Каждая соответствующая модель в проекте Baby GPT постепенно дополняет предыдущую, начиная с интуитивного понимания механизма самообслуживания, за которым следуют практические реализации точечного и масштабированного точечного произведения внимания, а кульминацией является интеграция единого модуль самообслуживания головы.
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur Класс SelfAttention представляет собой фундаментальный строительный блок модели Transformer, инкапсулирующий механизм самообслуживания с помощью одной головы. Вот представление о его компонентах и процессах:
Инициализация : конструктор __init__(self, d_k) инициализирует линейные слои для ключей, запросов и значений, все с размерностью d_k . Эти линейные преобразования проецируют входные данные в различные подпространства для последующих вычислений внимания.
Буферы : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) регистрирует нижнюю треугольную матрицу как постоянный буфер, который не считается параметром модели. Эта матрица используется для маскировки в механизме внимания, чтобы предотвратить рассмотрение будущих позиций на каждом этапе расчета (полезно при самоконтроле декодера).
Прямой проход : метод forward(self, X) определяет вычисления, выполняемые при каждом вызове модуля самообслуживания.
MultiHeadAttention : объединение выходных данных от нескольких головок SelfAttention в классе MultiHeadAttention . Класс MultiHeadAttention — это расширенная реализация механизма самообслуживания с одной головкой из предыдущего шага, но теперь несколько головок внимания работают параллельно, каждая из которых фокусируется на разных частях входных данных.
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : реализация нейронной сети прямого распространения с активацией ReLU в классе FeedForward . Чтобы добавить эту полностью связанную прямую связь в нашу модель, как в исходной модели трансформатора.
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks : объединение блоков преобразователей с использованием класса Block для создания более глубокой сетевой архитектуры. Глубина и сложность. В нейронных сетях глубина относится к количеству слоев, через которые обрабатываются данные. Каждый дополнительный уровень (или блок в случае с трансформерами) позволяет сети захватывать более сложные и абстрактные характеристики входных данных.
Последовательная обработка: каждый блок Transformer обрабатывает выходные данные предыдущего блока, постепенно создавая более сложное понимание входных данных. Эта последовательная обработка позволяет сети создавать глубокое, многоуровневое представление данных. Компоненты трансформаторного блока
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : улучшение класса Block для включения остаточных соединений, повышение эффективности обучения. Остаточные соединения, также известные как пропущенные соединения, являются важнейшим нововведением в разработке глубоких нейронных сетей, особенно в моделях Transformer. Они решают одну из основных проблем при обучении глубоких сетей: проблему исчезновения градиента.
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : добавление нормализации слоя к нашим выводам Transformer. Нормализация слоев с помощью nn.LayerNorm(d_model) в классе Block .
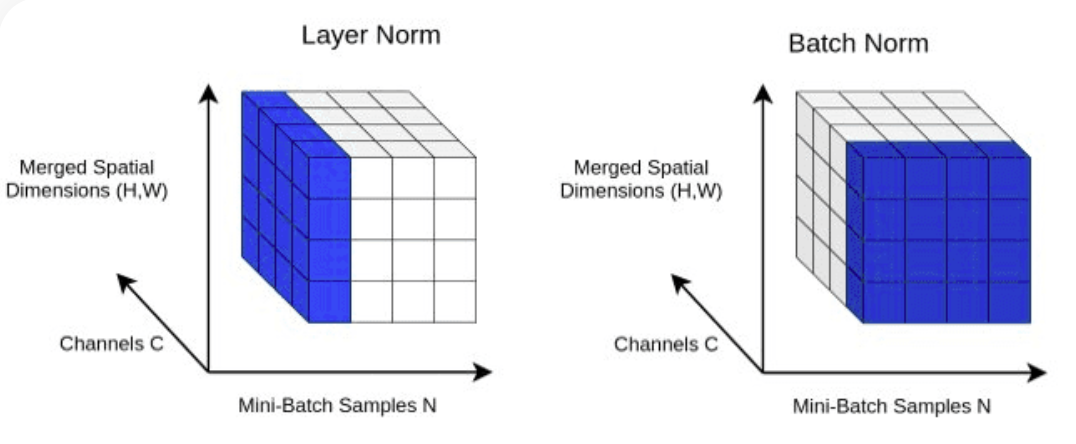
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] Dropout : необходимо добавить к слоям SelfAttention и FeedForward в качестве метода регуляризации для предотвращения переобучения. Мы добавляем выпадение в:
ScaleUp : увеличение сложности модели за счет расширения batch_size , block_size , d_model , d_k и Nx . Для обучения и тестирования этой более крупной модели вам понадобится набор инструментов CUDA, а также машина с графическим процессором NVIDIA.
Если вы хотите опробовать CUDA для ускорения графического процессора, убедитесь, что у вас установлена соответствующая версия PyTorch, поддерживающая CUDA.
import torch
torch . cuda . is_available ()Вы можете сделать это, указав версию CUDA в команде установки PyTorch, например, в командной строке:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

