ke dialogue
1.0.0


Это реализация документа:
Изучение баз знаний с параметрами для задачно-ориентированных диалоговых систем . Андреа Мадто , Сэмюэл Кахьявиджая, Гента Индра Вината, Ян Сюй, Цзихань Лю, Чжаоцзян Линь, Паскаль Фунг Результаты EMNLP 2020 [PDF]
Если вы используете в своей работе какие-либо исходные коды или наборы данных, включенные в этот набор инструментов, пожалуйста, дайте ссылку на следующий документ. Бибтекс указан ниже:
@article{madotto2020learning,
title={Обучение базам знаний с параметрами для задачно-ориентированных диалоговых систем},
автор={Мадотто, Андреа и Кахьявиджая, Самуэль и Вината, Гента Индра и Сюй, Ян и Лю, Зихан и Линь, Чжаоцзян и Фунг, Паскаль},
журнал = {препринт arXiv arXiv:2009.13656},
год={2020}
}
Диалоговые системы, ориентированные на задачи, либо имеют модульную структуру с отдельными этапами отслеживания состояния диалога (DST) и управления, либо являются сквозными для обучения. В любом случае база знаний (КБ) играет важную роль в выполнении запросов пользователей. Модульные системы полагаются на DST для взаимодействия с базой знаний, что требует больших затрат с точки зрения времени аннотаций и вывода. Сквозные системы используют базу знаний непосредственно в качестве входных данных, но они не могут масштабироваться, если база знаний превышает несколько сотен записей. В этой статье мы предлагаем метод встраивания базы знаний любого размера непосредственно в параметры модели. Полученная модель не требует каких-либо ответов DST или шаблонов, а также базы знаний в качестве входных данных, и она может динамически обновлять свою базу знаний посредством точной настройки. Мы оцениваем наше решение в пяти наборах данных диалогов, ориентированных на задачи, малого, среднего и большого размера в КБ. Наши эксперименты показывают, что сквозные модели могут эффективно внедрять базы знаний в свои параметры и достигать конкурентоспособной производительности во всех оцениваемых наборах данных.
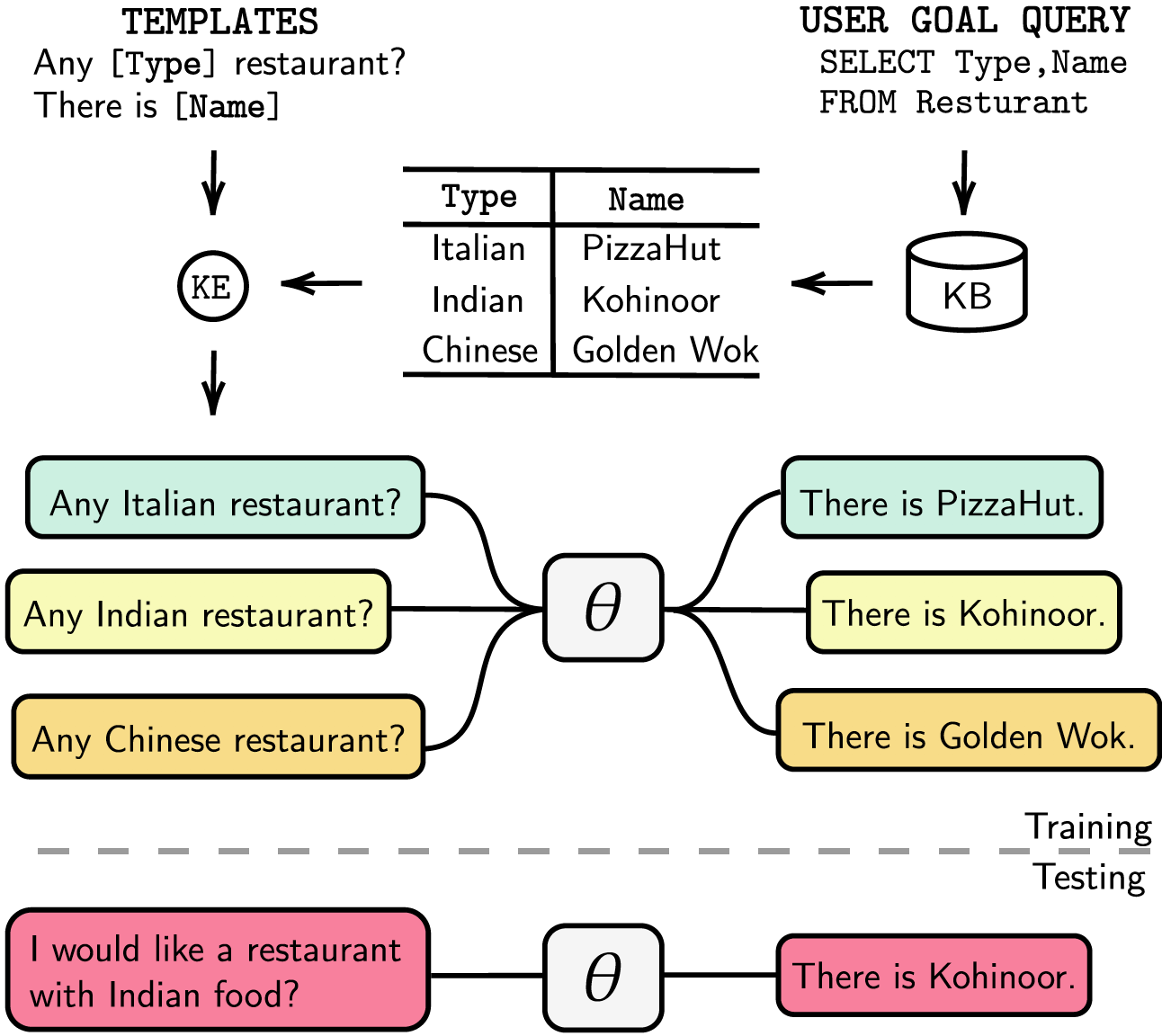
Мы перечислили наши зависимости в файле requirements.txt , вы можете установить зависимости, запустив
❱❱❱ pip install -r requirements.txt Кроме того, наш код также включает поддержку fp16 с помощью apex . Вы можете найти пакет по адресу https://github.com/NVIDIA/apex.
Набор данных Загрузите предварительно обработанный набор данных и поместите zip-файл в папку ./knowledge_embed/babi5 . Распакуйте zip-файл, выполнив
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipСгенерируйте делексикальные диалоги из набора данных bAbI-5 с помощью
❱❱❱ python3 generate_delexicalization_babi.pyСгенерируйте лексикализованные данные из набора данных bAbI-5 через
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Максимальное значение <num_augmented_knowledge> равно 558 (рекомендуется), а <num_augmented_dialogues> равно 264, поскольку оно соответствует количеству знаний и количеству диалогов в наборе данных bAbI-5.
Точная настройка GPT-2
Мы предоставляем КПП модели GPT-2, доработанной на обучающем комплексе bAbi. Вы также можете обучить модель самостоятельно, используя следующую команду.
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Отмечает, что значение --kbpercentage равно <num_augmented_dialogues> , полученному в результате лексикализации. Этот параметр используется для выбора файла расширения для встраивания в набор данных поезда.
Вы можете оценить модель, выполнив следующий скрипт
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks Оценка bAbI-5 Чтобы запустить программу оценки для модели задачи bAbI-5, вы можете запустить следующую команду. Секретарь прочитает весь файл result.json в папке runs , созданной из evaluate.py
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0Набор данных
Загрузите предварительно обработанный набор данных и поместите zip-файл в папку ./knowledge_embed/camrest . Разархивируйте zip-файл, выполнив
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipСгенерируйте делексизированные диалоги из набора данных CamRest с помощью
❱❱❱ python3 generate_delexicalization_CAMREST.pyСгенерируйте лексикализованные данные из набора данных CamRest с помощью
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Максимальное <num_augmented_knowledge> равно 201 (рекомендуется), а <num_augmented_dialogues> равно 156, что довольно велико, поскольку оно соответствует количеству знаний и количеству диалогов в наборе данных CamRest.
Точная настройка GPT-2
Мы предоставляем КПП модели GPT-2, доработанной на обучающем наборе CamRest. Вы также можете обучить модель самостоятельно, используя следующую команду.
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Отмечает, что значение --kbpercentage равно <num_augmented_dialogues> , полученному в результате лексикализации. Этот параметр используется для выбора файла расширения для встраивания в набор данных поезда.
Вы можете оценить модель, выполнив следующий скрипт
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest Оценка CamRest Чтобы запустить программу оценки для модели задачи bAbi 5, вы можете запустить следующую команду. Секретарь прочитает весь файл result.json в папке runs , созданной из evaluate.py
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0Набор данных
Загрузите предварительно обработанный набор данных и поместите его в папку ./knowledge_embed/smd .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipТочная настройка GPT-2
Мы предоставляем КПП модели ГПТ-2, доработанной на обучающем комплексе SMD. Загрузите контрольную точку и поместите ее в папку ./modeling .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runsВы также можете обучить модель самостоятельно, используя следующую команду.
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12Подготовьте диалоги, основанные на знаниях
Во-первых, нам нужно создать базы данных для SQL-запросов.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test Затем генерируем диалоги по заранее разработанным шаблонам по доменам. Следующая команда позволяет создавать диалоги в области weather . Пожалуйста, замените weather на navigate или schedule в аргументах dialogue_path и domain если вы хотите генерировать диалоги в двух других доменах. Вы также можете изменить количество шаблонов, используемых в процессе релексикализации, изменив аргумент num_augmented_dialogue .
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/testАдаптируйте настроенную модель GPT-2 к тестовому набору.
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""Вы также можете ускорить процесс тонкой настройки, проводя эксперименты параллельно. Измените настройки графического процессора в #L14 кода.
❱❱❱ python runner_expe_SMD.py Набор данных
Загрузите предварительно обработанный набор данных и поместите его в папку ./knowledge_embed/mwoz .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zipПодготовьте диалоги со встроенными знаниями (вы можете пропустить этот шаг, если загрузили zip-файл выше)
Вы можете подготовить наборы данных, запустив
❱❱❱ bash generate_MWOZ_all_data.shСценарий оболочки генерирует делексизированные диалоги из набора данных MWOZ, вызывая
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyТочная настройка GPT-2
Мы предоставляем КПП модели ГПТ-2, доработанную на учебном комплексе MWOZ. Загрузите контрольную точку и поместите ее в папку ./modeling .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runsВы также можете обучить модель самостоятельно, используя следующую команду.
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 Приступая к работе Мы используем версию сервера сообщества neo4j и библиотеку apoc для обработки графических данных. apoc используется для распараллеливания запроса в neo4j , чтобы мы могли быстрее обрабатывать крупномасштабные графы.
Прежде чем перейти к разделу набора данных, вам необходимо убедиться, что у вас установлены neo4j (https://neo4j.com/download-center/#community) и apoc (https://neo4j.com/developer/neo4j-apoc/). в вашей системе.
Если вы не знакомы с синтаксисами CYPHER и apoc , вы можете следовать руководству по https://neo4j.com/developer/cypher/ и https://neo4j.com/blog/intro-user-defined-procedures-apoc/
Набор данных Загрузите исходный набор данных и поместите zip-файл в папку ./knowledge_embed/opendialkg . Распакуйте zip-файл, выполнив
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipСгенерируйте удаленные диалоги из набора данных opendialkg с помощью ( ВНИМАНИЕ : для запуска требуется около 12 часов)
❱❱❱ python3 generate_delexicalization_DIALKG.py Этот скрипт создаст файл ./opendialkg/dialogkg_train_meta.pt , который будет использоваться для создания лексикализованного диалога. Затем вы можете сгенерировать лексикализованный диалог из набора данных opendialkg через
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 Этот скрипт будет создавать образцы диалогов не более чем в batch_size * max_iter , но в каждом пакете существует вероятность отсутствия действительного кандидата, что приведет к меньшему количеству образцов. Количество генераций ограничено другим фактором, называемым stop_count , который остановит генерацию, если количество сгенерированных выборок превышает указанное значение stop_count . Файл создаст 4 файла: ./opendialkg/db_count_records_{random_seed}.csv , ./opendialkg/used_count_records_{random_seed}.csv и ./opendialkg/generation_iteration_{random_seed}.csv , которые используются для проверки смещения распределения считать в БД; и ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json , который содержит сгенерированные образцы.
Примечания :
neo4j внутри generate_delexicalization_DIALKG.py generate_dialogues_DIALKG.py вручную.Точная настройка GPT-2
Мы предоставляем КПП модели GPT-2, доработанную на обучающем наборе opendialkg. Вы также можете обучить модель самостоятельно, используя следующую команду.
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 Отмечает, что значение --kbpercentage равно <random_seed> , полученному в результате лексикализации. Этот параметр используется для выбора файла расширения для встраивания в набор данных поезда.
Вы можете оценить модель, выполнив следующий скрипт
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg Оценка OpenDialKG Чтобы запустить программу оценки для модели задач bAbI-5, вы можете запустить следующую команду. Секретарь прочитает весь файл result.json в папке runs , созданной из evaluate.py
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 Подробную информацию об экспериментах, гиперпараметрах и результатах оценки вы можете найти в основной статье и дополнительных материалах нашей работы.


