REaLTabFormer
v0.2.1
REaLTabFormer (Реалистичные реляционные и табличные данные с использованием преобразователей) предлагает унифицированную структуру для синтеза табличных данных разных типов. Модель «последовательность-последовательность» (Seq2Seq) используется для создания синтетических реляционных наборов данных. Модель REaLTabFormer для нереляционных табличных данных использует GPT-2 и может использоваться в готовом виде для моделирования любых табличных данных с независимыми наблюдениями.
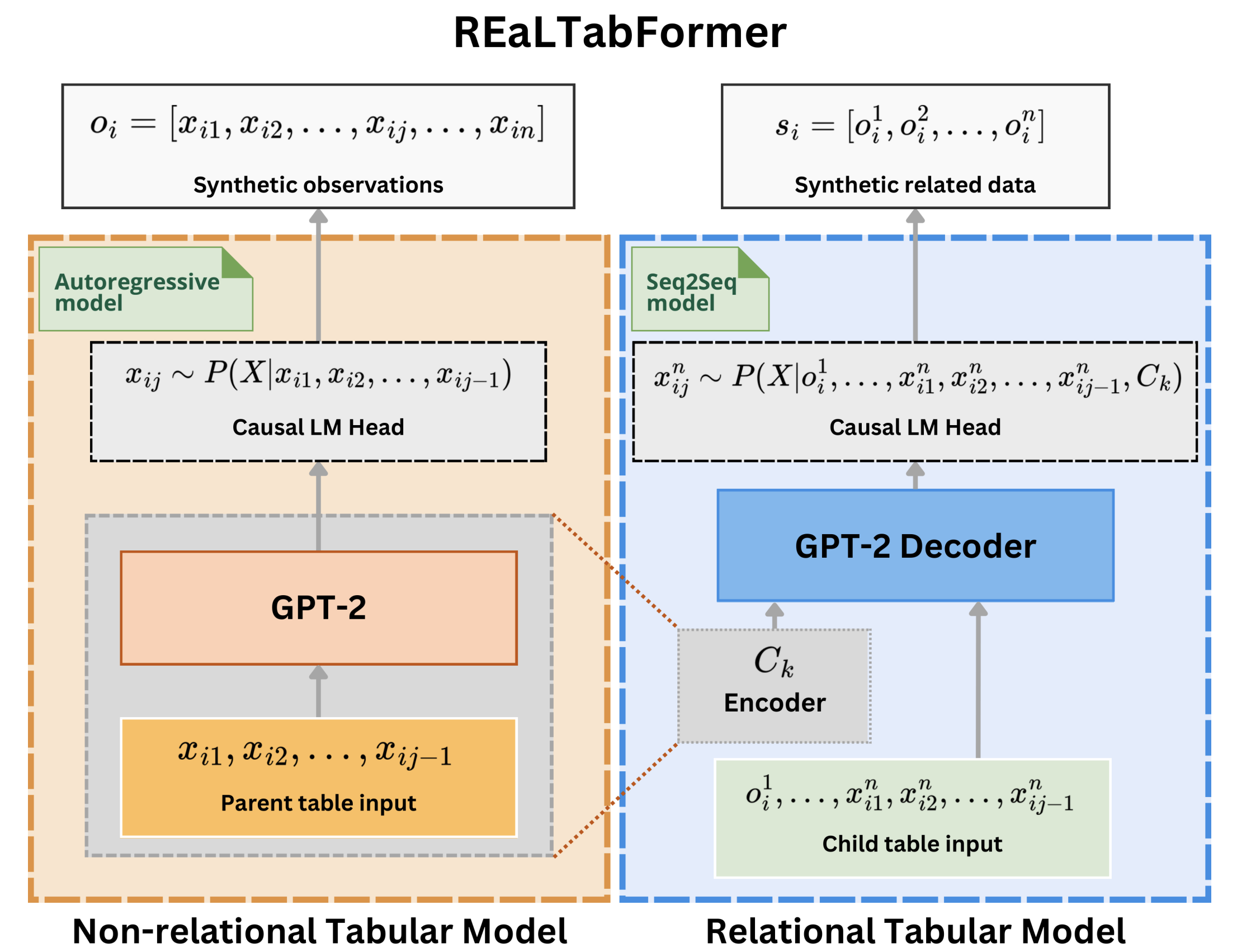
REaLTabFormer: генерация реалистичных реляционных и табличных данных с помощью преобразователей
Статья об ArXiv
REaLTabFormer доступен на PyPi и может быть легко установлен с помощью pip (версия Python >= 3.7):
pip установить Realtabformer
Мы показываем примеры использования REaLTabFormer для моделирования и генерации синтетических данных из обученной модели.
Примечание
Модель реализует оптимальный критерий остановки на основе синтетического распределения данных при обучении нереляционной табличной модели. Модель прекратит обучение, когда распределение синтетических данных будет близко к реальному распределению данных.
Обязательно установите для параметра epochs большое число, чтобы модель лучше соответствовала данным. Модель прекратит обучение, когда будет выполнен оптимальный критерий остановки.
# pip install realtabformerimport pandas as pdfrom realtabformer import REaLTabFormerdf = pd.read_csv("foo.csv")# ПРИМЕЧАНИЕ. Удалите из# данных все уникальные идентификаторы, которые вы не хотите моделировать.# Нереляционная или родительская таблица. rtf_model = REaLTabFormer(model_type="tabular",gradient_accumulation_steps=4,logging_steps=100)# Подгонка модели к набору данных.# Дополнительные параметры могут быть# переданы методу `.fit`.rtf_model.fit(df)# Сохраните модель в текущий каталог.# Будет создан новый каталог `rtf_model/`.# В нем также будет каталог с идентификатором # эксперимента модели `idXXXX` Created#, где будут храниться артефакты модели.rtf_model.save("rtf_model/")# Генерация синтетических данных с тем же # количеством наблюдений, что и реальный набор данных.samples = rtf_model.sample(n_samples=len(df)) # Загрузите сохраненную модель. Необходимо указать каталог # эксперимента.rtf_model2 = REaLTabFormer.load_from_dir(path="rtf_model/idXXXX") # pip install realtabformerimport osimport pandas as pdfrom pathlib import Pathfrom realtabformer import REaLTabFormerparent_df = pd.read_csv("foo.csv")child_df = pd.read_csv("bar.csv")join_on = "unique_id"# Убедитесь, что ключевые столбцы в родительская и дочерняя таблицы # имеют одинаковое имя.assert ((join_on в родительском_df.columns) и (join_on в child_df.columns))# Нереляционная или родительская таблица. Не включайте # unique_id field.parent_model = REaLTabFormer(model_type="tabular")parent_model.fit(parent_df.drop(join_on, axis=1))pdir = Path("rtf_parent/")parent_model.save(pdir)# # Получите самую последнюю сохраненную родительскую модель # # или укажите другую сохраненную модель. #parent_model_path = pdir / "idXXX"parent_model_path = sorted([p для p в pdir.glob("id*") if p.is_dir()],key=os.path.getmtime)[-1]child_model = REaLTabFormer(model_type="relational",parent_realtabformer_path=parent_model_path,output_max_length=None,train_size=0.8)child_model.fit(df=child_df,in_df=parent_df,join_on=join_on)# Создать родительские образцы.parent_samples = родительская_модель.sample(len(parend_df) ))# Создаём уникальный идентификаторы на основе index.parent_samples.index.name = join_onparent_samples = Parent_samples.reset_index()# Сгенерировать реляционные наблюдения.child_samples = child_model.sample(input_unique_ids=parent_samples[join_on],input_df=parent_samples.drop(join_on, axis=1) ,gen_batch=64) Платформа REaLTabFormer предоставляет интерфейс для простого создания валидаторов наблюдений для фильтрации недействительных синтетических образцов. Ниже мы покажем пример использования GeoValidator . На диаграмме слева показано распределение сгенерированных широты и долготы без проверки. На диаграмме справа показаны синтетические образцы с наблюдениями, которые были проверены с помощью GeoValidator с границей Калифорнии. Тем не менее, даже если мы не обучили модель оптимальным образом для ее создания, недействительных выборок (выходящих за границу) мало в сгенерированных данных без валидатора.
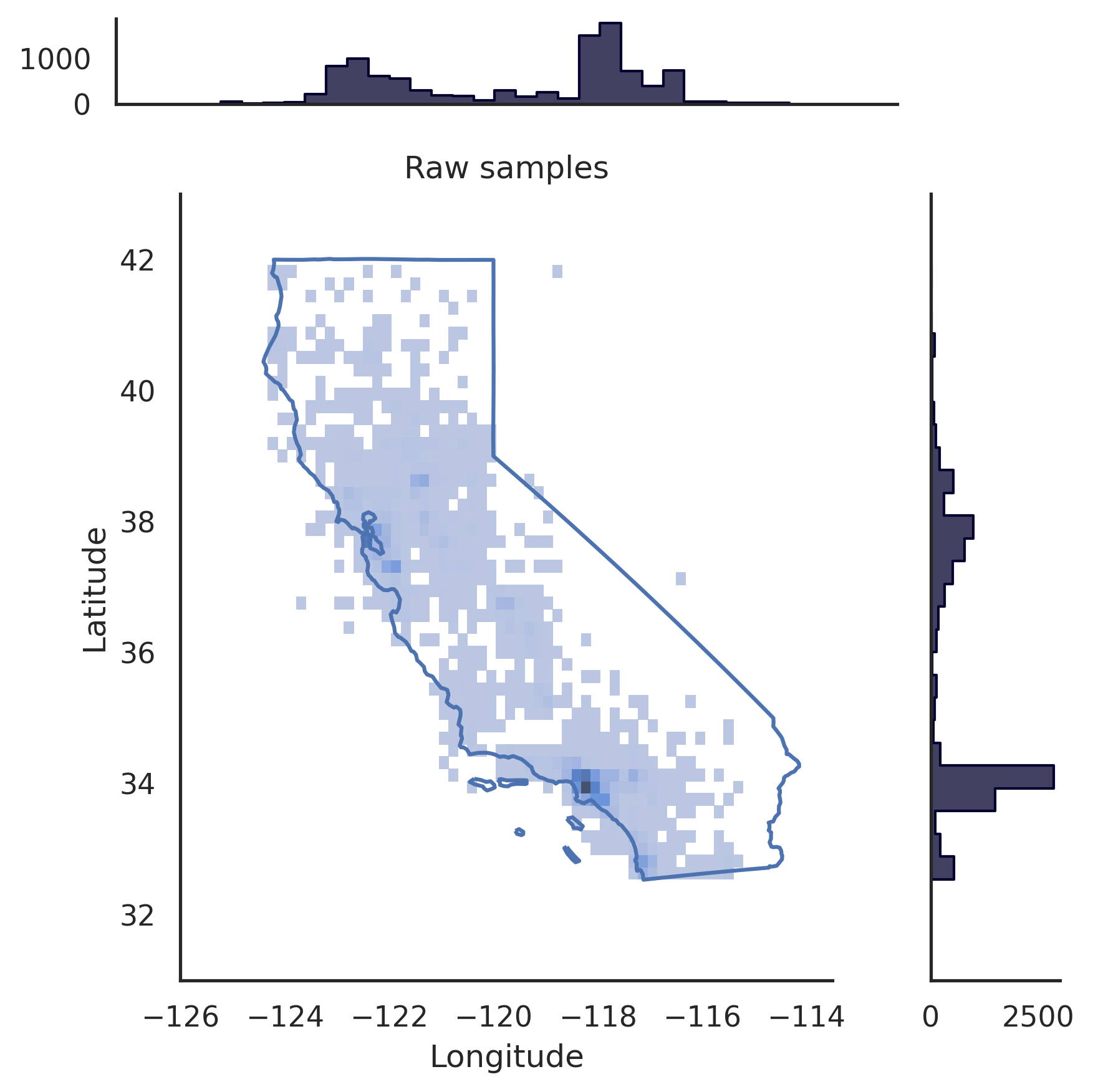
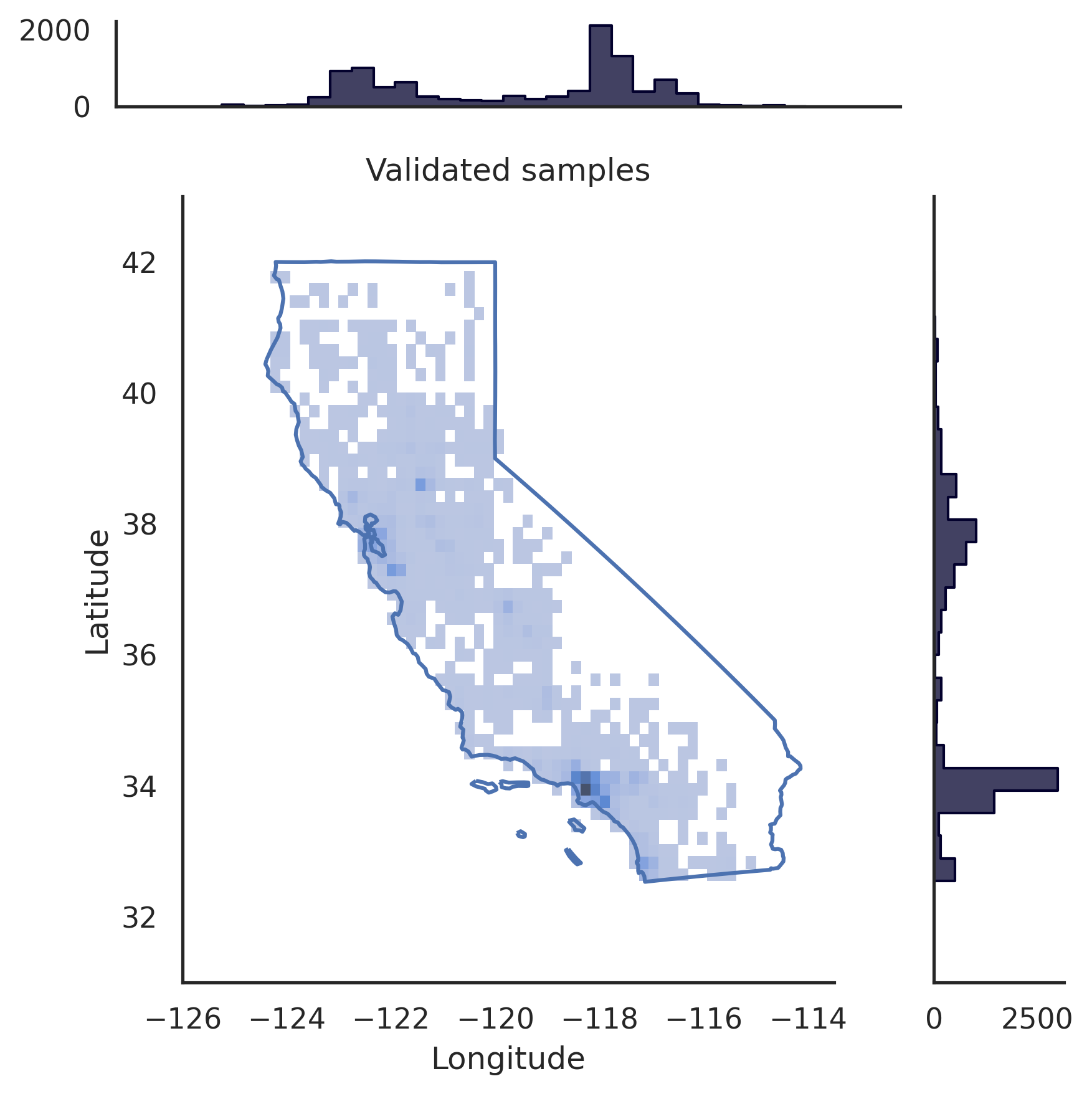
# !pip install geopandas &> /dev/null# !pip install realtabformer &> /dev/null# !git clone https://github.com/joncutrer/geopandas-tutorial.git &> /dev/nullimport geopandasimport seaborn as snsimport matplotlib.pyplot as pltfrom realtabformer import REaLTabFormerfrom realtabformer import rtf_validators as rtf_valfrom shapely.geometry import Polygon, LineString, Point, MultiPolygonfrom sklearn.datasets import fetch_california_housingdefplot_sf(data, sample, title=None):xlims = (-126, -113.5)ylims = (31, 43)bins = (50) , 50)dd = sample.copy()pp = dd.loc[dd["Долгота"].between(data["Долгота"].min(), data["Долгота".max()) &dd["Широта"].between(данные["Широта"] .min(), данные["Широта"].max())
]g = sns.JointGrid(data=pp, x="Longitude", y="Latitude", Marginal_ticks=True)g.plot_joint(sns.histplot,bins=bins,
)states[states['NAME'] == 'Калифорния'].boundary.plot(ax=g.ax_joint)g.ax_joint.set_xlim(*xlims)g.ax_joint.set_ylim(*ylims)g.plot_marginals(sns. histplot, element="step", color="#03012d")if title:g.ax_joint.set_title(title)plt.tight_layout()# Получить географические файлыstates = geopandas.read_file('geopandas-tutorial/data/usa-states-census-2014.shp')states =states.to_crs("EPSG :4326") # GPS Projection# Получите набор данных о жилье в Калифорнии = fetch_california_housing(as_frame=True).frame# Для демонстрации мы создаем модель с небольшими эпохами, значение по умолчанию — 200.rtf_model = REaLTabFormer(model_type="tabular",batch_size=64,epochs=10,gradient_accumulation_steps=4,logging_steps=100) # Подходит для указанной модели. Мы также уменьшаем num_bootstrap, по умолчанию — 500.rtf_model.fit(data, num_bootstrap=10)# Сохраняем обученную модельrtf_model.save("rtf_model/")# Выборка необработанных данных без валидаторовamples_raw = rtf_model.sample(n_samples=10240, gen_batch= 512)# Пример данных с географическим validatorobs_validator = rtf_val.ObservationValidator()obs_validator.add_validator("geo_validator",rtf_val.GeoValidator(MultiPolygon(states[states['NAME'] == 'California'].geometry[0])),
(«Долгота», «Широта»)
)samples_validated = rtf_model.sample(n_samples=10240, gen_batch=512,validator=obs_validator,
)# Визуализация sampleplot_sf(data, sample_raw, title="Необработанные образцы")plot_sf(data, sample_validated, title="Проверенные образцы")Пожалуйста, цитируйте нашу работу, если вы используете REaLTabFormer в своих проектах или исследованиях.
@article{solatorio2023realtabformer, title={REALTabFormer: Генерация реалистичных реляционных и табличных данных с помощью преобразователей}, автор={Соляторио, Эйвин В. и Дюпри, Оливье}, журнал={препринт arXiv arXiv:2302.02041}, год={2023}}Мы благодарим Объединенный центр данных Всемирного банка и УВКБ ООН по принудительному перемещению (JDC) за финансирование проекта «Расширение ответственного доступа к микроданным для улучшения политики и реагирования в ситуациях принудительного перемещения» (KP-P174174-GINP-TF0B5124). Часть фонда пошла на поддержку разработки системы REaLTabFormer, которая использовалась для создания синтетической совокупности для исследований риска раскрытия информации и эффекта мозаики.
Мы также отправляем? к HuggingFace? для всего программного обеспечения с открытым исходным кодом, которое они выпускают. И всем проектам с открытым кодом спасибо!


