spelltest
v0.0.4
? Если вы считаете этот проект полезным, поставьте ему звездочку! Ваша поддержка мотивирует меня продолжать улучшать его! ?
Сегодняшние приложения, управляемые искусственным интеллектом, во многом зависят от моделей больших языков (LLM), таких как GPT-4, для предоставления инновационных решений. Однако обеспечение того, чтобы они давали актуальные и точные ответы в любой ситуации, является непростой задачей. Spelltest решает эту проблему, моделируя ответы LLM с использованием синтетических персонажей пользователей и метода оценки для автоматической оценки этих ответов (но все равно требует человеческого контроля).
spellforge.yaml : project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

Теперь вы можете опробовать этот проект в интерактивной веб-среде через Google Colab! Никакой установки не требуется.
Просто нажмите на значок выше, чтобы начать!
Гарантированное качество : имитируйте взаимодействие с пользователем для получения оптимальных ответов.
Эффективность и экономия : сэкономьте на расходах на ручное тестирование.
Плавная интеграция рабочего процесса : легко вписывается в ваш процесс разработки.
Имейте в виду, что это очень ранняя версия Spelltest. Таким образом, он еще не прошел тщательных испытаний в различных средах и вариантах использования. Решая использовать эту версию, вы соглашаетесь с тем, что используете платформу Spelltest на свой страх и риск. Мы настоятельно рекомендуем пользователям сообщать о любых проблемах или ошибках, с которыми они сталкиваются, чтобы помочь в улучшении проекта.
Что касается эксплуатационных расходов, важно отметить, что за выполнение моделирования с помощью Spelltest взимается плата, основанная на использовании API OpenAI. На данный момент нет ни оценок затрат, ни ограничений бюджета. Для сравнения, запуск пакета из 100 симуляций может стоить примерно от 0,7 до 1,8 доллара (gpt-3,5-turbo), в зависимости от нескольких факторов, включая конкретный LLM и сложность моделирования.
Учитывая эти затраты, мы настоятельно рекомендуем начинать с меньшего количества симуляций, чтобы снизить первоначальные затраты и помочь вам лучше оценить будущие расходы. По мере того, как вы лучше знакомитесь со структурой и ее финансовыми последствиями, вы можете регулировать количество симуляций в соответствии с вашим бюджетом и потребностями.
Помните, что цель Spelltest — обеспечить высококачественные ответы от LLM, оставаясь при этом максимально экономически эффективным в процессе разработки и тестирования ИИ.

Spelltest использует особый подход к обеспечению качества. Используя синтетические персонажи пользователей, мы не только имитируем взаимодействие, но и улавливаем уникальные ожидания пользователей, предоставляя контекстно-насыщенную среду для тестирования. Такая глубина контекста позволяет нам оценивать качество ответов LLM таким образом, чтобы точно отражать реальные приложения.
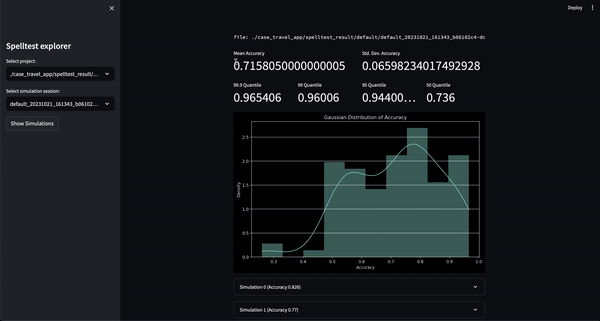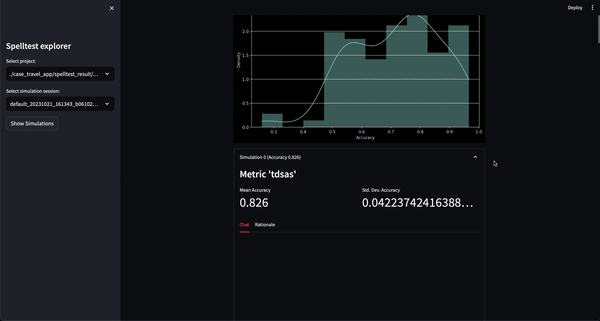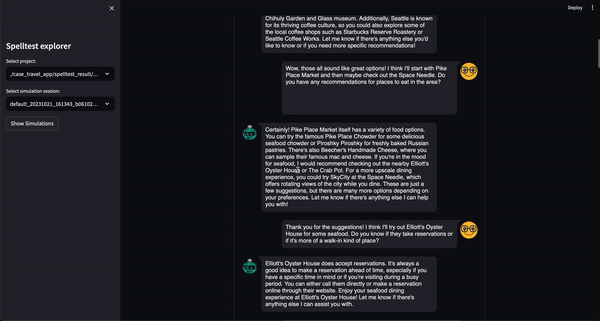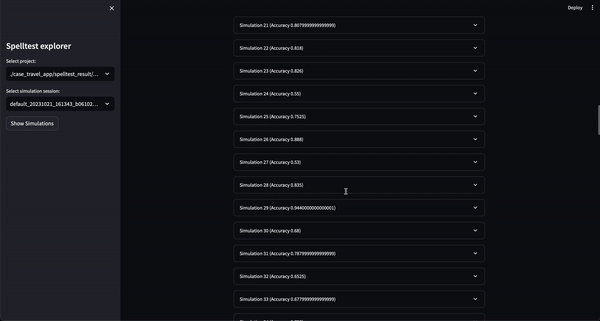
Результат? Показатель качества варьируется от 0,0 до 1,0 и служит генеральной репетицией перед тем, как ваше приложение встретится с реальными пользователями. Независимо от того, в режиме чата или в режиме завершения, Spelltest гарантирует, что ответы LLM точно соответствуют ожиданиям пользователей, повышая общую удовлетворенность пользователей.
Установите фреймворк с помощью pip:
pip install spelltest Файл .spellforge.yaml занимает центральное место в Spelltest и содержит синтетические профили пользователей, метрики, подсказки и симуляции. Ниже приведена разбивка его структуры:
Синтетические пользователи имитируют реальных пользователей, каждый из которых имеет уникальный опыт, ожидания и понимание приложения. Конфигурация для синтетических пользователей включает в себя:
Дополнительные подсказки : это описательные элементы, обеспечивающие контекст профиля пользователя. Они включают в себя:
description : Краткая информация о синтетическом пользователе.expectation : что пользователь ожидает от взаимодействия.user_knowledge_about_app : уровень знакомства с приложением.Каждый синтетический пользователь также имеет:
name : идентификатор синтетического пользователя.llm_name : используемые модели LLM (проверено только на моделях OpenAI).temperature : ...Пример синтетической пользовательской конфигурации:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... Метрики используются для оценки и оценки ответов LLM. Каждая метрика содержит дополнительное description , которое предоставляет контекст того, что оценивает метрика.
Пример простой конфигурации метрики:
...
metrics :
accuracy :
description : " Accuracy "
...Пример сложной/индивидуальной конфигурации метрик:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... Подсказки — это вопросы или задачи, которые ставит приложение. Они используются в моделировании для проверки способности LLM генерировать подходящие ответы. Каждое приглашение определяется description и фактическим текстом prompt или задачей.
...
prompts :
book_flight :
file : book-flight-prompt.txt
... Моделирование определяет сценарий тестирования. Ключевые элементы включают в себя prompt , users , llm_name , temperature , size , chat_mode и quality_threshold .
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
Полная конфигурация с файлами подсказок находится здесь.
Затраты на OpenAI . Использование этой платформы может привести к значительному количеству запросов к OpenAI, особенно при запуске обширного моделирования. Это может привести к значительным расходам на вашей учетной записи OpenAI. Убедитесь, что вы помните о своем бюджете OpenAI и понимаете модель ценообразования. Я не несу ответственности за любые понесенные расходы.
Ранний выпуск : эта версия Spelltest находится на ранней стадии и не имеет никаких гарантий стабильности. Пожалуйста, используйте его с осторожностью и не стесняйтесь оставлять отзывы или сообщать о проблемах.
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlПроверьте результаты моделирования.
spelltest --analyzeИнтеграция Spelltest в конвейер выпуска улучшает вашу стратегию развертывания за счет последовательного автоматизированного тестирования. Этот важный шаг гарантирует, что ваши приложения на основе LLM будут поддерживать высокий стандарт качества за счет систематического моделирования и оценки взаимодействия с пользователем перед любым выпуском. Такая практика может сэкономить значительное время, уменьшить количество ошибок, допускаемых вручную, и предоставить ключевую информацию о том, как изменения или новые функции повлияют на взаимодействие с пользователем.
Это руководство проведет вас через процесс настройки и автоматизации непрерывной интеграции для ваших проектов.
Прежде чем приступить к работе, убедитесь, что у вас есть следующие предварительные условия:
Репозиторий GitHub, содержащий ваш проект.
Доступ к SpellForge с помощью ключа API. Если у вас его нет, вы можете получить его на веб-сайте SpellForge.
Ключ OpenAI API для использования сервисов OpenAI. Если у вас его нет, вы можете получить его на веб-сайте OpenAI.
.spellforge.yaml Создайте файл .spellforge.yaml в корневом каталоге вашего проекта. Этот файл будет содержать инструкции для проверки правописания.
Создайте файл рабочего процесса GitHub Actions, например, .github/workflows/.spelltest.yaml, чтобы автоматизировать тестирование SpellForge. Вставьте в этот файл следующий код:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHЭтот рабочий процесс запускается при каждом отправке в основную ветку и запускает ваши тесты SpellForge.
Перейдите в свой репозиторий GitHub и перейдите на вкладку «Настройки».
В разделе «Секреты» добавьте два новых секрета:
OPENAI_API_KEY : установите этот секрет для вашего ключа API OpenAI.
Добавьте переменную среды GitHub:
SPELLTEST_CONFIG_PATH : установите для этой переменной полный путь к вашему файлу .spellforge.yaml в вашем репозитории.
Они моделируют взаимодействие реальных пользователей с конкретными характеристиками и ожиданиями.
История пользователя (поле description в .spellforge.yaml ): дополнительная подсказка, предоставляющая обзор того, кем является этот искусственный пользователь, и проблемы, которые он хочет решить с помощью приложения, например, путешественник, управляющий своим расписанием.
Ожидания пользователя (поле expectation ): дополнительное приглашение, определяющее, что искусственный пользователь ожидает от успешного взаимодействия или решения от использования приложения.
Осведомленность об окружающей среде (поле user_knowledge_about_app ): дополнительная подсказка, которая гарантирует, что искусственный пользователь понимает контекст приложения, обеспечивая реалистичные сценарии тестирования.
Дополнительная подсказка, представляющая стандарты или критерии, используемые для оценки и оценки ответов, генерируемых LLM в симуляциях. Метрики могут варьироваться от общих измерений до более специфичных для приложения, пользовательских метрик.
Общие примеры метрик:
Семантическое сходство : измеряет, насколько близко предоставленный ответ напоминает ожидаемый ответ с точки зрения значения.
Токсичность : оценивается ответ на любой язык или контент, который может считаться неуместным или вредным.
Структурное сходство : сравнивает структуру и формат сгенерированного ответа с заранее определенным стандартом или ожидаемым результатом.
Дополнительные примеры специальных метрик:
TPAS (показатель точности плана путешествия) : «Этот показатель измеряет точность сгенерированного ответа путем оценки включения ожидаемых результатов и качества предлагаемого плана путешествия. TPAS представляет собой числовое значение от 0 до 100, где 100 представляет собой идеальный соответствует ожидаемому результату, а 0 указывает на неточный результат».
EES (оценка вовлеченности в эмпатию) : «EES оценивает эмпатический резонанс ответов LLM. Оценивая понимание, подтверждение и поддерживающие элементы в сообщении, он оценивает передаваемый уровень эмпатии. EES варьируется от 0 до 100, где 100 указывает на уровень эмпатии. очень чуткий ответ, а 0 означает отсутствие чуткого участия».
Улучшите свое приложение на основе LLM с помощью Spelltest!


