paperchat
1.0.0
Добро пожаловать в arXivchat!
arXivchat — это программное обеспечение на основе LLM, которое позволяет вам обсуждать опубликованные статьи arXiv в разговорной форме. Он работает как инструмент командной строки, поставщик API и плагин ChatGPT.
Сделано передовыми операторами. Мы работаем с одними из самых умных людей над проектами, связанными с LLM и ML.
Вы более чем можете внести свой вклад!
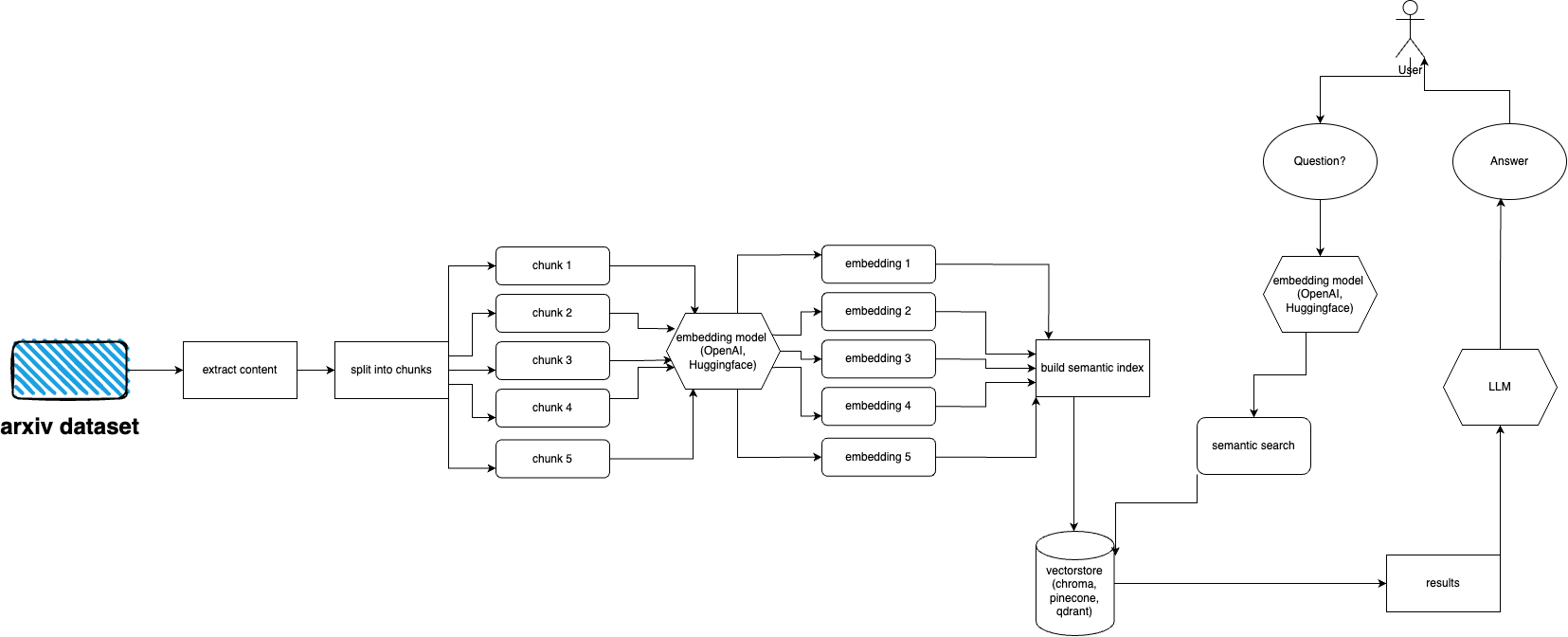
Выполните следующие действия, чтобы быстро настроить и запустить плагин arXiv:
Установите Python 3.10, если он еще не установлен.
Клонируйте репозиторий: git clone https://github.com/Forward-Operators/arxivchat.git.
Перейдите в каталог клонированного репозитория: cd /path/to/arxivchat.
Установить поэзию: pip install poetry
Создайте новую виртуальную среду с помощью Python 3.10: poetry env use python3.10
Активируйте виртуальную среду: poetry shell
Установите зависимости приложения: poetry install
Установите необходимые переменные среды:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
Запустите API локально: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
Откройте документацию по API по адресу http://0.0.0.0:8000/docs и протестируйте конечные точки API.
arXiv имеет набор данных из почти 2 миллионов публикаций. Получение слишком большого количества данных с их веб-сайта противоречит Условиям обслуживания arXiv (поскольку это создает нагрузку). К счастью, хорошие люди из Kaggle вместе с Корнельским университетом создают общедоступный набор данных, который вы можете использовать. Набор данных доступен бесплатно через сегменты Google Cloud Storage и обновляется еженедельно.
Теперь основная проблема заключается в следующем: как получить только часть всего этого набора данных, если мы не хотим принимать более 5 терабайт PDF-файлов? Набор данных разделен на каталоги по месяцам и годам, поэтому, если вы хотите получить все публикации за сентябрь 2021 года, вы можете просто запустить: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
Если вы хотите получить весь набор данных: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
Но если вы хотите получить только подмножество (для данной категории и дат), загляните в файл download.py .
По умолчанию ingester ожидает, что эти файлы будут находиться в /mnt/dataset/arxiv/pdf со всеми файлами PDF там.
Проверьте и запустите python scripy.py для приема данных. Там же можно включить отладку, если что-то не работает.
TODO: возможно, измените это на загрузчик каталогов TODO: реализовать развертывание сельдерея и использовать работника для приема
python cli.py 
Задайте вопрос по теме, которую вы уже загрузили в базу данных. Также возвращает информацию об источниках, работает постоянно. Другой вариант — использовать REST API (запустите uvicorn main:app --reload --host 0.0.0.0 --port 8000 из каталога app ) или используйте его как плагин ChatGPT (после развертывания).
В каталоге deployment есть файлы terraform. Используйте тот, который подходит вам лучше всего. В каждом из них есть файл README с инструкциями. Вы также можете просто создать образ Docker и запустить его где угодно. Однако файл изображения довольно большой.
На данный момент его можно развернуть как Cloud Run с использованием образа Docker, поэтому это развертывание только через API. Прием данных должен выполняться на другом компьютере (я рекомендую вычислительные движки с поддержкой графического процессора, особенно если вы хотите использовать встраивания Hugging Face и поскольку вы можете смонтировать базу данных из хранилища Google напрямую с помощью gcsfuse ). Возможное решение — использование корзины GCS с облаком. Бегать
На данный момент его можно развернуть как контейнерные приложения (развертывание только через API, для приема потребуется еще одно развертывание).
AWS пока не поддерживается. Вскоре.
arxivchat по умолчанию использует text-embedding-ada-002 для OpenAI, вы можете изменить это в app/tools/factory.py
На данный момент вы можете использовать любую модель, которая работает с sentence_transformers . Вы можете изменить модель в app/tools/factory.py
Если у вас возникли проблемы, сообщите о них с помощью вопросов GitHub.
Мы будем рады вашей помощи в том, чтобы сделать arXivchat еще лучше! Чтобы внести свой вклад, выполните следующие действия:
arXivchat выпускается под лицензией MIT.


