distrifuser
v0.0.1beta0
[29 июля 2024 г.] DistriFusion поддерживается в ColossalAI!
[4 апреля 2024 г.] DistriFusion выбран в качестве главного постера CVPR 2024!
[29 февраля 2024 г.] DistriFusion принят на CVPR 2024! Наш код общедоступен!
 Мы представляем DistriFusion, не требующий обучения алгоритм, позволяющий использовать несколько графических процессоров для ускорения вывода модели диффузии без ущерба для качества изображения. Наивный патч (обзор (б)) страдает от проблемы фрагментации из-за отсутствия взаимодействия с патчами. Представленные примеры созданы с помощью SDXL с использованием 50-шагового сэмплера Эйлера с разрешением 1280×1920, а задержка измеряется на графических процессорах A100.
Мы представляем DistriFusion, не требующий обучения алгоритм, позволяющий использовать несколько графических процессоров для ускорения вывода модели диффузии без ущерба для качества изображения. Наивный патч (обзор (б)) страдает от проблемы фрагментации из-за отсутствия взаимодействия с патчами. Представленные примеры созданы с помощью SDXL с использованием 50-шагового сэмплера Эйлера с разрешением 1280×1920, а задержка измеряется на графических процессорах A100.
DistriFusion: распределенный параллельный вывод для моделей диффузии высокого разрешения
Муян Ли*, Тяньлэ Цай*, Цзясинь Цао, Циньшэн Чжан, Хан Цай, Цзюньцзе Бай, Янцин Цзя, Мин-Ю Лю, Кай Ли и Сун Хан
Массачусетский технологический институт, Принстон, Lepton AI и NVIDIA
В ЦВПР 2024.
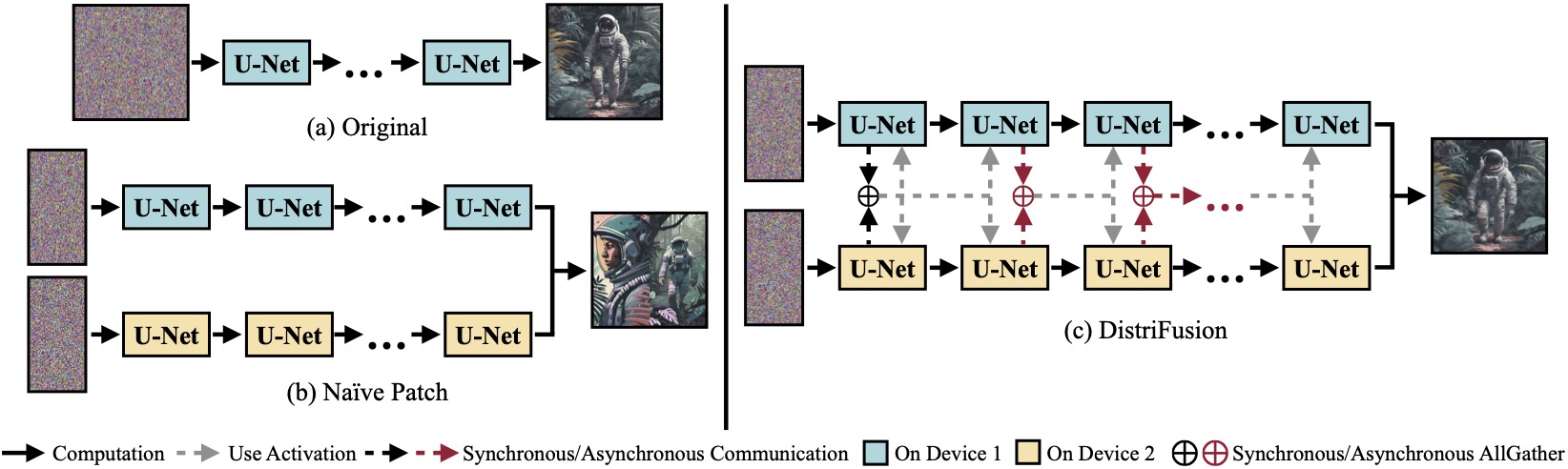 (а) Исходная диффузионная модель, работающая на одном устройстве. (б) Наивное разделение изображения на 2 патча на двух графических процессорах имеет очевидный шов на границе из-за отсутствия взаимодействия между патчами. (c) Наш DistriFusion использует синхронную связь для взаимодействия патчей на первом этапе. После этого мы повторно используем активации с предыдущего шага посредством асинхронной связи. Таким образом, накладные расходы на связь могут быть скрыты в вычислительном конвейере.
(а) Исходная диффузионная модель, работающая на одном устройстве. (б) Наивное разделение изображения на 2 патча на двух графических процессорах имеет очевидный шов на границе из-за отсутствия взаимодействия между патчами. (c) Наш DistriFusion использует синхронную связь для взаимодействия патчей на первом этапе. После этого мы повторно используем активации с предыдущего шага посредством асинхронной связи. Таким образом, накладные расходы на связь могут быть скрыты в вычислительном конвейере.
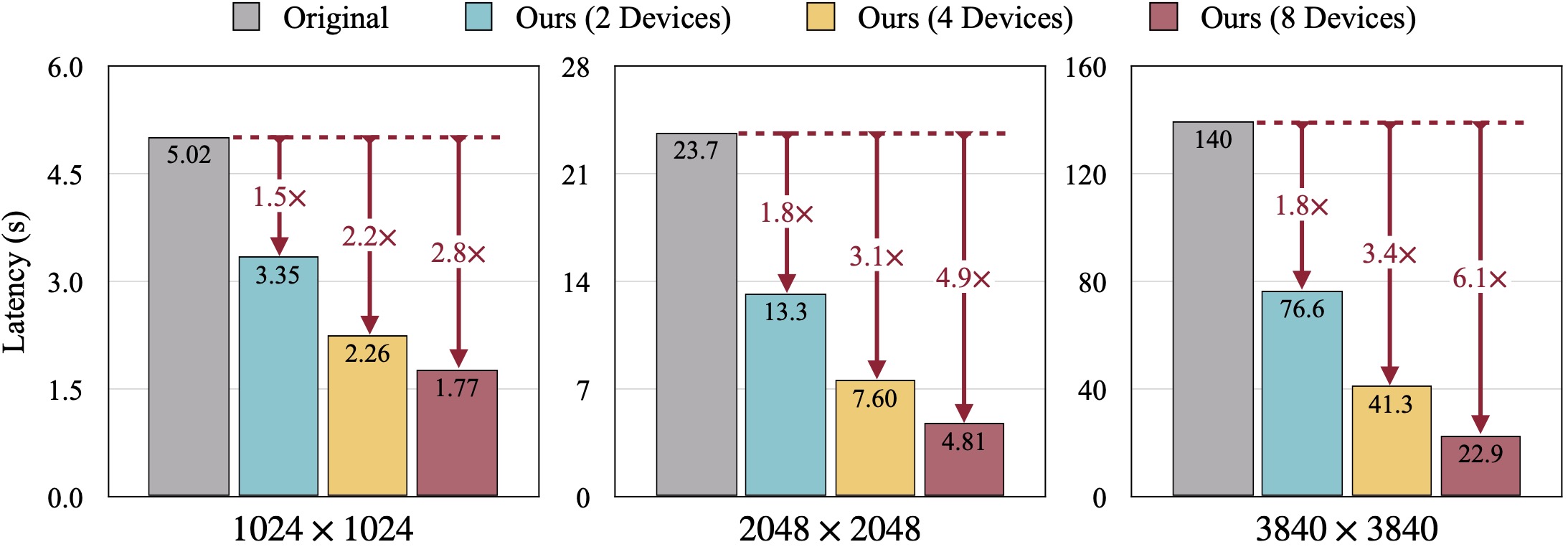
 Качественные результаты SDXL. FID рассчитывается на основе достоверных изображений. Наш DistriFusion может уменьшить задержку в зависимости от количества используемых устройств, сохраняя при этом четкость изображения.
Качественные результаты SDXL. FID рассчитывается на основе достоверных изображений. Наш DistriFusion может уменьшить задержку в зависимости от количества используемых устройств, сохраняя при этом четкость изображения.
Ссылки:
После установки PyTorch вы сможете установить distrifuser с PyPI.
pip install distrifuserили через GitHub:
pip install git+https://github.com/mit-han-lab/distrifuser.gitили локально для разработки
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . В scripts/sdxl_example.py мы предоставляем минимальный сценарий для запуска SDXL с DistriFusion.
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) В частности, наш distrifuser использует те же API, что и диффузоры, и может использоваться аналогичным образом. Вам просто нужно определить DistriConfig и использовать наш завернутый DistriSDXLPipeline для загрузки предварительно обученной модели SDXL. Затем мы можем сгенерировать изображение, подобное StableDiffusionXLPipeline в диффузорах. Команда запуска
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py где $N_GPUS — количество графических процессоров, которые вы хотите использовать.
Мы также предоставляем минимальный сценарий для запуска SD1.4/2 с DistriFusion в scripts/sd_example.py . Использование такое же.
Результаты наших тестов получены при использовании PyTorch 2.2 и диффузоров 0.24.0. Во-первых, вам может потребоваться установить некоторые дополнительные зависимости:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid Вы можете использовать scripts/generate_coco.py для создания изображений с подписями COCO. Команда
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
где $N_GPUS — количество графических процессоров, которые вы хотите использовать. По умолчанию сгенерированные результаты будут храниться в results/coco . Вы также можете настроить его с помощью --output_root . Некоторые дополнительные аргументы, которые вы можете настроить:
--num_inference_steps : количество шагов вывода. По умолчанию мы используем 50.--guidance_scale : шкала навигации без классификатора. По умолчанию мы используем 5.--scheduler : Диффузионный сэмплер. По умолчанию мы используем сэмплер DDIM. Вы также можете использовать euler для пробоотборника Эйлера и dpm-solver для решателя DPM.--warmup_steps : количество дополнительных шагов разминки (по умолчанию 4).--sync_mode : различные режимы синхронизации GroupNorm. По умолчанию используется исправленный асинхронный GroupNorm.--parallelism : используемая вами парадигма параллелизма. По умолчанию это патч-параллелизм. Вы можете использовать tensor для тензорного параллелизма и naive_patch для наивного исправления. После создания всех изображений вы можете использовать наш сценарий scripts/compute_metrics.py для расчета PSNR, LPIPS и FID. Использование
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 где $IMAGE_ROOT0 и $IMAGE_ROOT1 — пути к папкам изображений, которые вы пытаетесь сравнить. Если IMAGE_ROOT0 является основным каталогом, добавьте флаг --is_gt для изменения размера. Мы также предоставляем скрипт scripts/dump_coco.py для создания дампа достоверных изображений.
Вы можете использовать scripts/run_sdxl.py для измерения задержки различными методами. Команда
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent где $N_GPUS — количество графических процессоров, которые вы хотите использовать. Подобно scripts/generate_coco.py , вы также можете изменить некоторые аргументы:
--num_inference_steps : количество шагов вывода. По умолчанию мы используем 50.--image_size : размер сгенерированного изображения. По умолчанию это 1024х1024.--no_split_batch : отключить разделение пакетов для руководства без классификатора.--warmup_steps : количество дополнительных шагов разминки (по умолчанию 4).--sync_mode : различные режимы синхронизации GroupNorm. По умолчанию используется исправленный асинхронный GroupNorm.--parallelism : используемая вами парадигма параллелизма. По умолчанию это патч-параллелизм. Вы можете использовать tensor для тензорного параллелизма и naive_patch для наивного исправления.--warmup_times / --test_times : количество прогонов/тестов. По умолчанию их 5 и 20 соответственно. Если вы используете этот код для своих исследований, пожалуйста, цитируйте нашу статью.
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}Наш код разработан на основеhuggingface/diffusers и lmxyy/sige. Мы благодарим torchprofile за измерение MAC, clean-fid за расчет FID и Lightning-AI/torchmetrics за PSNR и LPIPS.
Мы благодарим Цзюнь-Янь Чжу и Лигэн Чжу за полезное обсуждение и ценные отзывы. Проект поддерживается MIT-IBM Watson AI Lab, Amazon, MIT Science Hub и Национальным научным фондом.


