все-ай
Ваш высококвалифицированный локальный чат-бот-помощник на базе искусственного интеллекта?
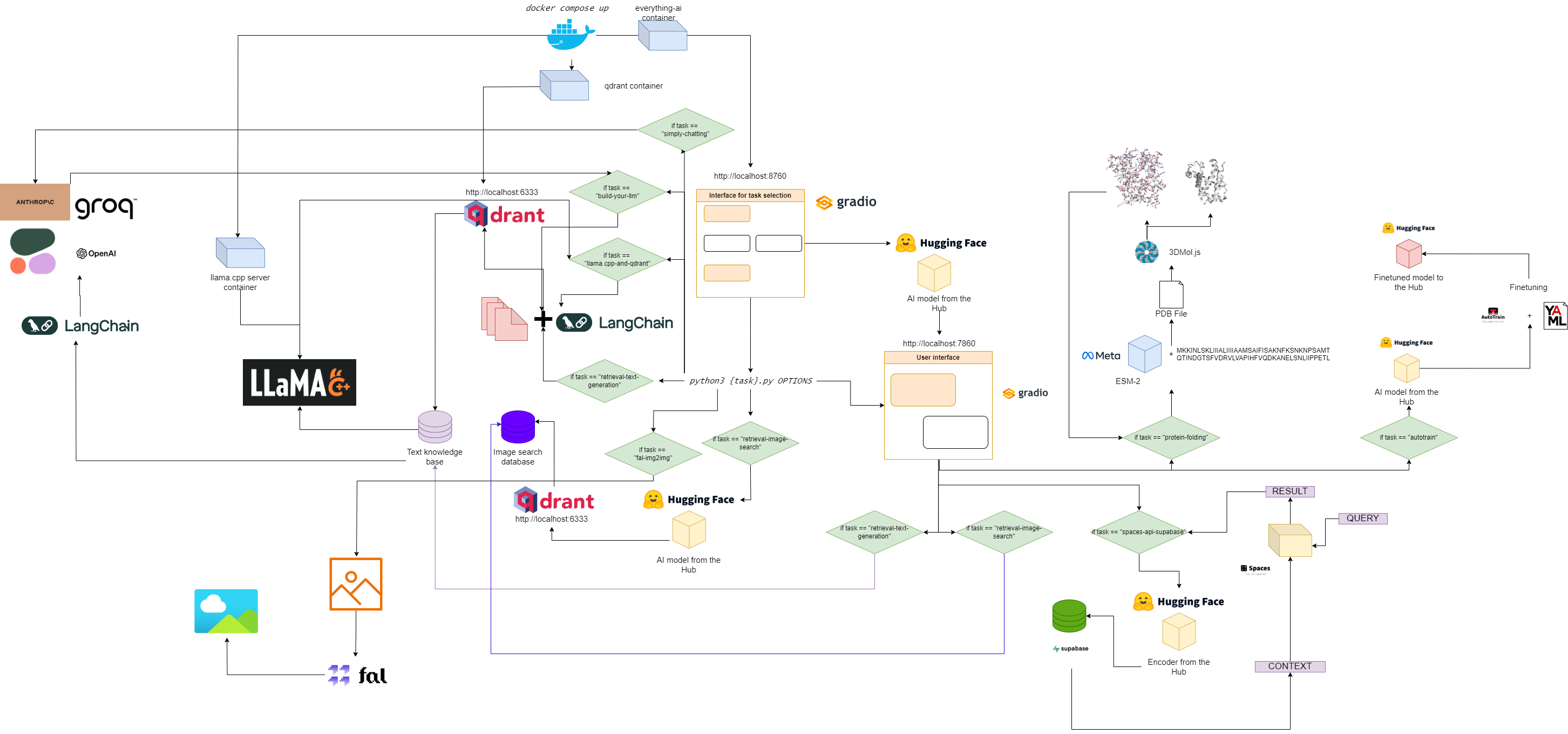
Блок-схема всего-ИИ
Быстрый старт
1. Клонируйте этот репозиторий
git clone https://github.com/AstraBert/everything-ai.git
cd everything-ai
2. Установите файл .env
Изменить:
- Переменная
VOLUME в файле .env, чтобы вы могли подключить локальную файловую систему к контейнеру Docker. - Переменная
MODELS_PATH в файле .env, чтобы вы могли сообщить llama.cpp, где вы сохранили загруженные модели GGUF. - Переменная
MODEL в файле .env, чтобы вы могли указать llama.cpp, какую модель использовать (используйте фактическое имя файла gguf и не забудьте расширение .gguf!) - Переменная
MAX_TOKENS в файле .env, чтобы вы могли сообщить llama.cpp, сколько новых токенов он может сгенерировать в качестве выходных данных.
Примером файла .env может быть:
VOLUME= " c:/Users/User/:/User/ "
MODELS_PATH= " c:/Users/User/.cache/llama.cpp/ "
MODEL= " stories260K.gguf "
MAX_TOKENS= " 512 "
Это означает, что теперь все, что находится в разделе «c:/Users/User/» на вашем локальном компьютере, находится в разделе «/User/» в вашем контейнере Docker, и llama.cpp знает, где искать модели и какую модель искать, вместе с максимальным количеством новых токенов для его вывода.
3. Вытащите необходимые изображения
docker pull astrabert/everything-ai:latest
docker pull qdrant/qdrant:latest
docker pull ghcr.io/ggerganov/llama.cpp:server
4. Запустите многоконтейнерное приложение.
5. Перейдите на localhost:8670 и выберите своего помощника.
Вы увидите что-то вроде этого:
Выберите задачу среди:
- поиск-текст-генерация : используйте бэкэнд
qdrant для создания удобной для поиска базы знаний, к которой вы можете запрашивать и настраивать ответ вашей модели. Вам необходимо передать либо PDF-файл/кучу PDF-файлов, указанные в виде путей, разделенных запятыми, либо каталог, в котором хранятся все интересующие PDF-файлы ( НЕ указывайте оба); вы также можете указать язык, на котором написан PDF-файл, используя номенклатуру ISO - МНОГОЯЗЫЧНЫЙ - agnostic-text-generation : генерация текста в стиле ChatGPT (без архитектуры поиска), но поддерживает все модели генерации текста в HF Hub (при условии, что ваше оборудование поддерживает ее!) - МНОГОЯЗЫЧНЫЙ
- суммирование текста : суммирование текста и PDF-файлов, поддержка всех моделей суммирования текста в HF Hub — ТОЛЬКО НА АНГЛИЙСКОМ ЯЗЫКЕ
- создание изображений : стабильное распространение, поддержка всех моделей преобразования текста в изображение в HF Hub - МНОГОЯЗЫЧНЫЙ
- image-generation-pollinations : стабильное распространение, используйте API Pollinations AI; если вы выберете «генерация-опыление изображений», вам не нужно больше ничего указывать, кроме задачи - МНОГОЯЗЫЧНЫЙ
- классификация изображений : классифицирует изображение, поддерживает все модели классификации изображений на HF Hub – ТОЛЬКО НА АНГЛИЙСКОМ ЯЗЫКЕ
- Преобразование изображения в текст : описание изображения, поддержка всех моделей преобразования изображения в текст в HF Hub – ТОЛЬКО НА АНГЛИЙСКОМ ЯЗЫКЕ.
- классификация звука : классифицируйте аудиофайлы или записи с микрофона, поддерживает модели классификации звука на ВЧ-концентраторе
- Распознавание речи : расшифровка аудиофайлов или записей с микрофона, поддержка моделей автоматического распознавания речи на ВЧ-концентраторе.
- создание видео : создание видео по текстовой подсказке, поддержка моделей преобразования текста в видео на ВЧ-концентраторе — ТОЛЬКО НА АНГЛИЙСКОМ ЯЗЫКЕ
- сворачивание белка : получите трехмерную структуру белка на основе его аминокислотной последовательности, используя модель основной цепи ESM-2 — ТОЛЬКО графический процессор.
- autotrain : точная настройка модели для конкретной последующей задачи с помощью autotrain-advanced, просто указав имя пользователя HF, токен записи HF и путь к файлу конфигурации yaml для обучения.
- space-api-supabase : используйте HF Spaces API в сочетании с базами данных Supabase PostgreSQL, чтобы раскрыть более мощные LLM и более крупные векторные базы данных, ориентированные на RAG - МНОГОЯЗЫЧНЫЕ
- llama.cpp-and-qdrant : то же, что и поиск-текст-генерация , но использует llama.cpp в качестве механизма вывода, поэтому НЕ ДОЛЖНО указывать модель - МНОГОЯЗЫЧНЫЙ
- build-your-llm : создайте настраиваемый чат LLM, объединив базу данных Qdrant с вашими PDF-файлами и мощью моделей Anthropic, OpenAI, Cohere или Groq: вам просто нужен ключ API! Чтобы создать базу данных Qdrant, необходимо передать либо PDF-файл/набор PDF-файлов, указанные в виде путей, разделенных запятыми, либо каталог, в котором хранятся все интересующие PDF-файлы ( НЕ указывайте оба); вы также можете указать язык, на котором написан PDF-файл, используя номенклатуру ISO — МНОГОЯЗЫЧНЫЙ , LANGFUSE INTEGRATION.
- Простое общение : создайте настраиваемый чат LLM с помощью моделей Anthropic, OpenAI, Cohere или Groq (без конвейера RAG): вам просто нужен ключ API! - МНОГОЯЗЫЧНАЯ ИНТЕГРАЦИЯ ЛАНГФУЗА
- fal-img2img : используйте fal.ai ComfyUI API для создания изображений, начиная с изображений PNG и JPEG: вам просто нужен ключ API! Вы также можете настроить генерацию, работающую с подсказками и семенами - ТОЛЬКО НА АНГЛИЙСКОМ ЯЗЫКЕ.
- image-retrival-search : поиск в базе данных изображений, загружая папку в качестве входных данных базы данных. Папка должна иметь следующую структуру:
./
├── test/
| ├── label1/
| └── label2/
└── train/
├── label1/
└── label2/
Вы можете запросить базу данных, начиная с ваших собственных изображений.
6. Перейдите по адресу localhost:7860 и начните использовать своего помощника.
Когда все будет готово, вы можете перейти на localhost:7860 и начать использовать своего помощника: