serverless rag ynetnews bedrock demo
1.0.0
Ответы на вопросы (QA) — это важная задача, которая включает в себя извлечение ответов на фактические вопросы, заданные на естественном языке. Обычно система контроля качества обрабатывает запрос к базе знаний, содержащей структурированные или неструктурированные данные, и генерирует ответ с точной информацией. Обеспечение высокой точности является ключом к разработке полезной, надежной и заслуживающей доверия системы ответов на вопросы, особенно для корпоративных случаев использования.
Генеративные модели искусственного интеллекта, такие как Amazon Titan, Anthropic Claude и AI21 Jurassic 2, используют распределения вероятностей для генерации ответов на вопросы. Эти модели обучаются на огромных объемах текстовых данных, что позволяет им предсказывать, что будет дальше в последовательности или какое слово может следовать за конкретным словом. Однако эти модели не способны дать точные или детерминированные ответы на каждый вопрос, поскольку в данных всегда присутствует некоторая степень неопределенности.
Предприятиям необходимо запрашивать специфичные для предметной области и собственные данные и использовать эту информацию для ответа на вопросы, а также, в более общем плане, данные, на которых модель не обучалась.
В этом репозитории мы рассмотрим следующий шаблон контроля качества:
Мы используем поисковую дополненную генерацию, которая является усовершенствованной по сравнению с первой, когда мы объединяем наши вопросы с максимально возможным контекстом, который, вероятно, будет содержать ответы или информацию, которую мы ищем. Проблема здесь: существует ограничение на количество используемой контекстной информации, определяемое лимитом токенов модели. 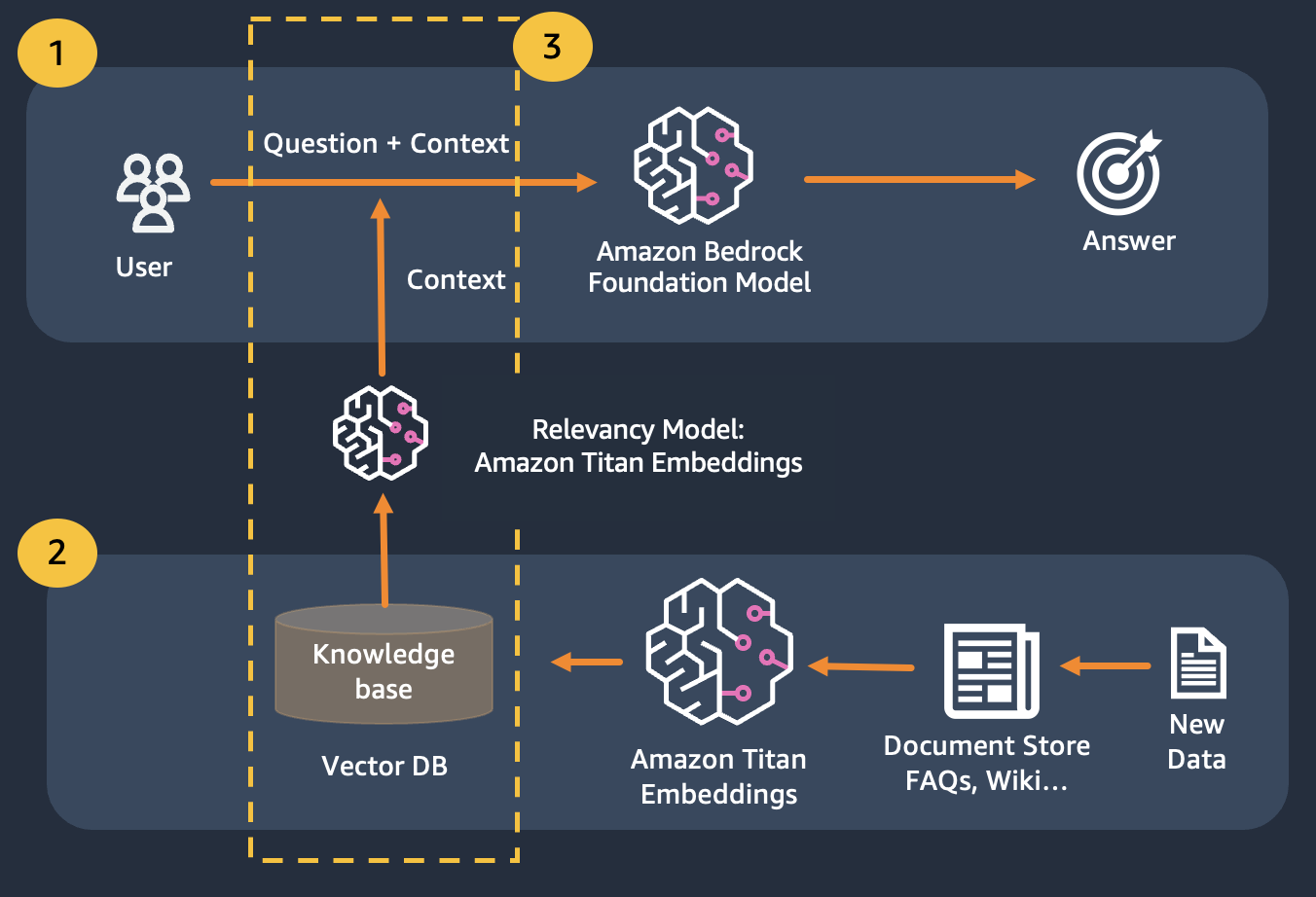
Это можно преодолеть с помощью Retrival Augmented Generation (RAG).
RAG сочетает в себе использование вложений для индексации корпуса документов для создания базы знаний и использование LLM для извлечения информации из подмножества документов в базе знаний.
На этапе подготовки к RAG документы, составляющие базу знаний, разбиваются на фрагменты фиксированного размера (соответствующие максимальному входному размеру выбранной модели внедрения), а затем передаются в модель для получения вектора внедрения. Встраивание вместе с исходным фрагментом документа и дополнительными метаданными сохраняется в векторной базе данных. База данных векторов оптимизирована для эффективного поиска сходства между векторами.
Клиенты с хранилищами данных, которые могут быть частными или часто меняться. Подход RAG решает две проблемы. Клиенты, имеющие следующие проблемы, могут получить пользу от этой лаборатории.
После этого модуля вы должны иметь хорошее представление о:
В этом модуле мы покажем вам, как реализовать шаблон контроля качества с помощью Bedrock. Кроме того, мы подготовили для вас вложения для загрузки в векторную базу данных.
Обратите внимание, что вы можете использовать Titan Embeddings для получения вложений пользовательского вопроса, а затем использовать эти встраивания для извлечения наиболее релевантных документов из векторной базы данных, создать подсказку, объединяющую 3 лучших документа, и вызвать модель LLM через Bedrock.


