LLM Alignment Project
1.0.0
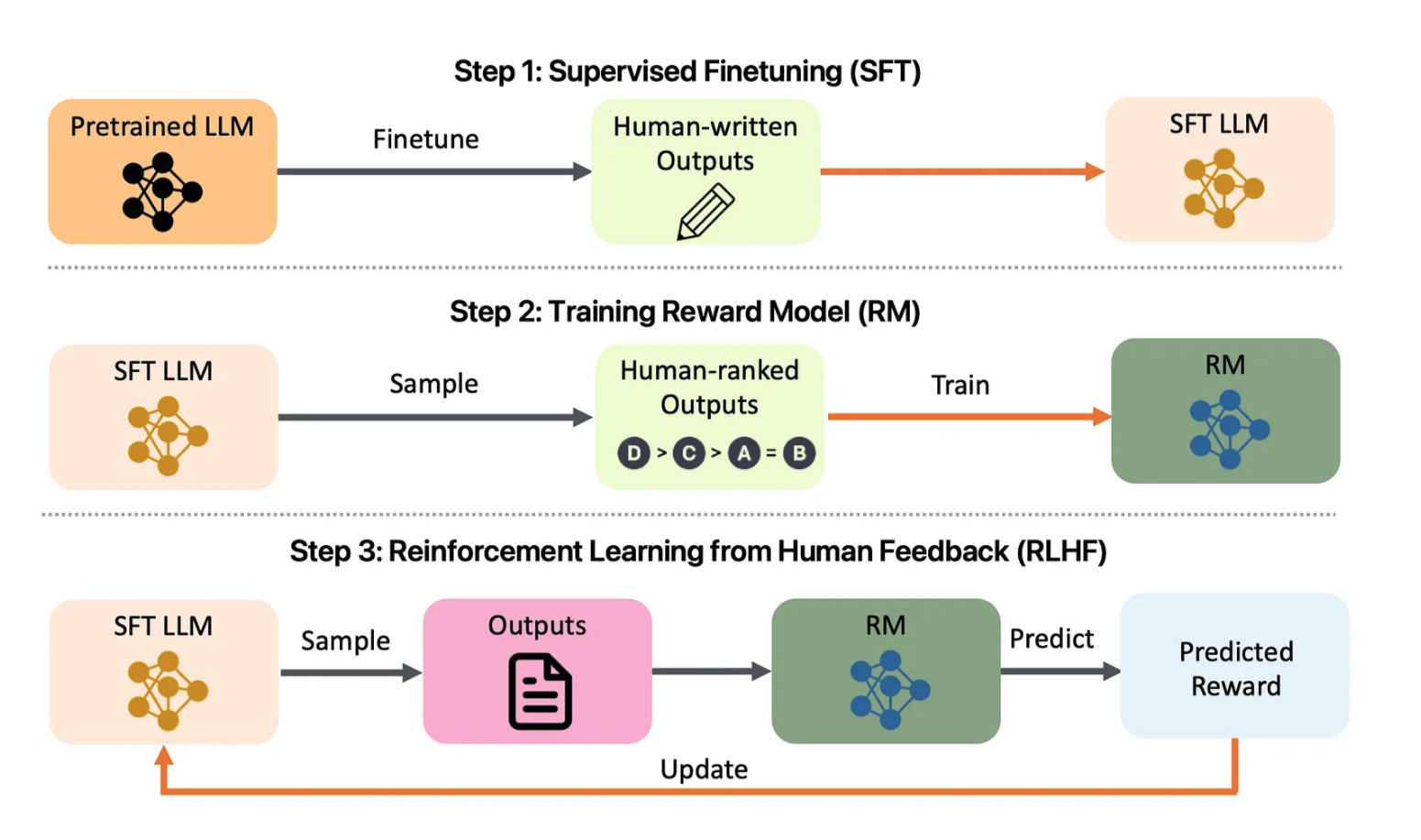
Рисунок 1: Обзор проекта согласования LLM. Взгляните на: arXiv:2308.05374.
Шаблон LLM Alignment — это не просто комплексный инструмент для согласования больших языковых моделей (LLM), но также мощный шаблон для создания собственного приложения выравнивания LLM. Этот репозиторий, созданный на основе шаблонов проектов, таких как шаблон проекта PyTorch , предназначен для предоставления полного набора функций и служит отправной точкой для настройки и расширения в соответствии с вашими собственными потребностями в согласовании LLM. Независимо от того, являетесь ли вы исследователем, разработчиком или специалистом по данным, этот шаблон обеспечивает прочную основу для эффективного создания и внедрения программ LLM, адаптированных к человеческим ценностям и целям.
Шаблон согласования LLM предоставляет полный набор функций, включая обучение, тонкую настройку, развертывание и мониторинг LLM с использованием подкрепленного обучения на основе обратной связи с человеком (RLHF). Этот проект также объединяет показатели оценки для обеспечения этичного и эффективного использования языковых моделей. Интерфейс предлагает удобный интерфейс для управления согласованием, визуализации показателей обучения и масштабного развертывания.
app/ : содержит код API и пользовательского интерфейса.
auth.py , feedback.py , ui.py : конечные точки API для взаимодействия с пользователем, сбора отзывов и общего управления интерфейсом.app.js , chart.js ), CSS ( styles.css ) и документация по API Swagger ( swagger.json ).chat.html , feedback.html , index.html ) для рендеринга пользовательского интерфейса. src/ : основная логика и утилиты для предварительной обработки и обучения.
preprocessing/ ):preprocess_data.py : объединяет исходные и дополненные наборы данных и применяет очистку текста.tokenization.py : обрабатывает токенизацию.training/ ):fine_tuning.py , transfer_learning.py , retrain_model.py : Скрипты для обучения и переобучения моделей.rlhf.py , reward_model.py : Скрипты для обучения модели вознаграждения с использованием RLHF.utils/ ): общие утилиты ( config.py , logging.py , validation.py ). dashboards/ : панели мониторинга производительности и объяснимости для мониторинга и анализа моделей.
performance_dashboard.py : отображает показатели обучения, потери при проверке и точность.explainability_dashboard.py : визуализирует значения SHAP, чтобы дать представление о решениях модели. tests/ : модульные, интеграционные и сквозные тесты.
test_api.py , test_preprocessing.py , test_training.py : различные модульные и интеграционные тесты.e2e/ ): тесты пользовательского интерфейса на основе Cypress ( ui_tests.spec.js ).load_testing/ ): использует Locust ( locustfile.py ) для нагрузочного тестирования. deployment/ : файлы конфигурации для развертывания и мониторинга.
kubernetes/ ): конфигурации развертывания и входа для масштабируемых и канареечных выпусков.monitoring/ ): Prometheus ( prometheus.yml ) и Grafana ( grafana_dashboard.json ) для мониторинга производительности и состояния системы. Клонируем репозиторий :
git clone https://github.com/yourusername/LLM-Alignment-Template.git
cd LLM-Alignment-TemplateУстановить зависимости :
pip install -r requirements.txt cd app/static
npm installСборка образов Docker :
docker-compose up --buildДоступ к приложению :
http://localhost:5000 . kubectl apply -f deployment/kubernetes/deployment.yml
kubectl apply -f deployment/kubernetes/service.ymlkubectl apply -f deployment/kubernetes/hpa.ymldeployment/kubernetes/canary_deployment.yml для безопасного развертывания новых версий.deployment/monitoring/ чтобы включить панели мониторинга.docker-compose.logging.yml для централизованного ведения журналов. Модуль обучения ( src/training/transfer_learning.py ) использует предварительно обученные модели, такие как BERT, для адаптации к пользовательским задачам, обеспечивая значительный прирост производительности.
Скрипт data_augmentation.py ( src/data/ ) применяет методы расширения, такие как обратный перевод и перефразирование, для улучшения качества данных.
rlhf.py и reward_model.py для точной настройки моделей на основе отзывов людей.feedback.html ), а модель переобучается с помощью retrain_model.py . Скрипт explainability_dashboard.py использует значения SHAP , чтобы помочь пользователям понять, почему модель сделала определенные прогнозы.
tests/ и охватывают функции API, предварительной обработки и обучения.tests/load_testing/locustfile.py ) для обеспечения стабильности под нагрузкой. Вклады приветствуются! Пожалуйста, отправляйте запросы на включение или проблемы для улучшений или новых функций.
Этот проект лицензируется по лицензии MIT. Дополнительную информацию смотрите в файле LICENSE.
Разработано с помощью ❤️ Амирсиной Торфи


