GenerativeRL
v0.0.1
английский | 简体中文 (упрощенный китайский)
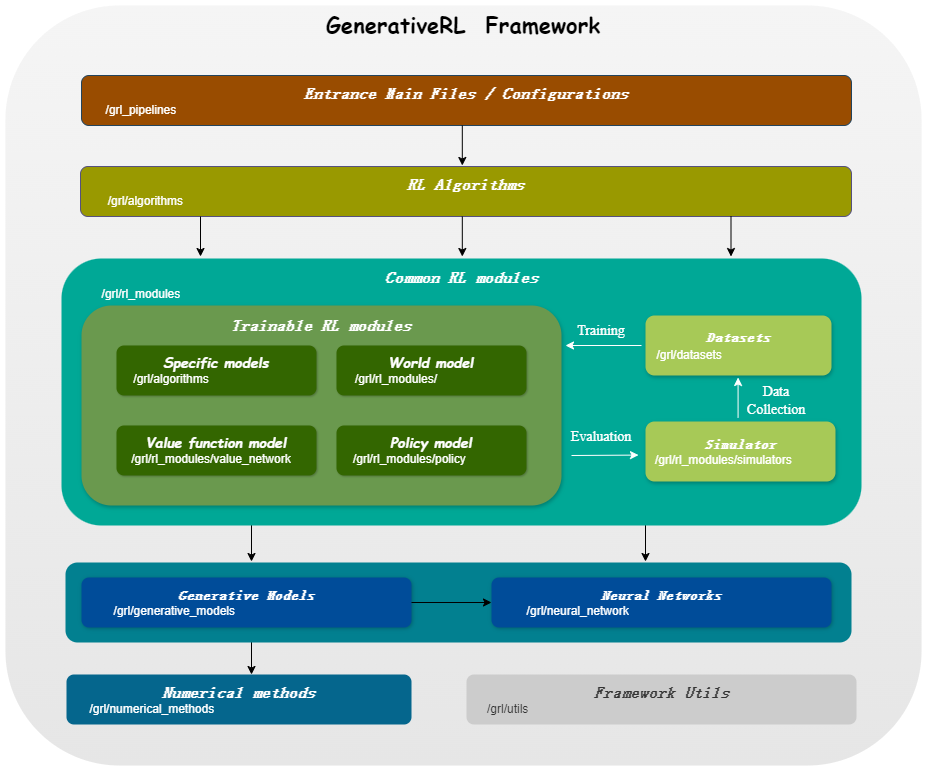
GenerativeRL , сокращение от Generative Reinforcement Learning, — это библиотека Python для решения задач обучения с подкреплением (RL) с использованием генеративных моделей, таких как модели диффузии и модели потока. Цель этой библиотеки — предоставить основу для объединения возможностей генеративных моделей с возможностями принятия решений алгоритмов обучения с подкреплением.
| Сопоставление очков | Согласование потока | |
|---|---|---|
| Диффузионная модель | ||
| Линейный ВП СДЕ | ✔ | ✔ |
| Обобщенный вице-президент SDE | ✔ | ✔ |
| Линейный СДУ | ✔ | ✔ |
| Модель потока | ||
| Независимое условное сопоставление потоков | ✔ | |
| Оптимальное согласование условного потока при транспортировке | ✔ |
| Алго./Модели | Диффузионная модель | Модель потока |
|---|---|---|
| ИДКЛ | ✔ | |
| КГПО | ✔ | |
| СРПО | ✔ | |
| ГМПО | ✔ | ✔ |
| ГМПГ | ✔ | ✔ |
pip install GenerativeRLИли, если вы хотите установить из исходного кода:
git clone https://github.com/opendilab/GenerativeRL.git
cd GenerativeRL
pip install -e .Или вы можете использовать образ докера:
docker pull opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashВот пример того, как обучить модель распространения для оптимизации политики на основе Q (QGPO) в среде LunarLanderContinous-v2 с использованием GenerativeRL.
Установите необходимые зависимости:
pip install ' gym[box2d]==0.23.1 '(Версия тренажерного зала может быть от 0,23 до 0,25 для сред box2d, но для совместимости с D4RL рекомендуется использовать версию 0.23.1.)
Загрузите набор данных отсюда и сохраните его как data.npz в текущем каталоге.
GenerativeRL использует WandB для ведения журналов. Он попросит вас войти в свою учетную запись, когда вы ее используете. Вы можете отключить его, выполнив:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )Более подробные примеры и документацию можно найти в документации GenerativeRL.
Полную документацию для GenerativeRL можно найти в документации GenerativeRL.
Мы предоставляем несколько учебных пособий, которые помогут вам лучше понять GenerativeRL. Подробнее см. в руководствах.
Мы предлагаем несколько базовых экспериментов для оценки эффективности алгоритмов генеративного обучения с подкреплением. Подробнее см. в бенчмарке.
Мы приветствуем вклад в GenerativeRL! Если вы заинтересованы в участии, пожалуйста, обратитесь к Руководству для участников.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}GenerativeRL распространяется по лицензии Apache License 2.0. Подробнее см. ЛИЦЕНЗИЯ.


