?️Инструмент GenAI для преобразования изображения в речь с использованием LLM ?♨️
Инструмент искусственного интеллекта, который генерирует краткий аудиорассказ на основе контекста загруженного изображения, используя модель GenAI LLM, модели Hugging Face AI вместе с OpenAI и LangChain. Развертывается на Streamlit и Hugging Space Cloud отдельно.
? Запустите приложение с помощью Streamlit Cloud
Запустите приложение на Streamlit
? Запустите приложение с помощью HuggingFace Space Cloud
Запустите приложение на HuggingFace Space.
Демо:
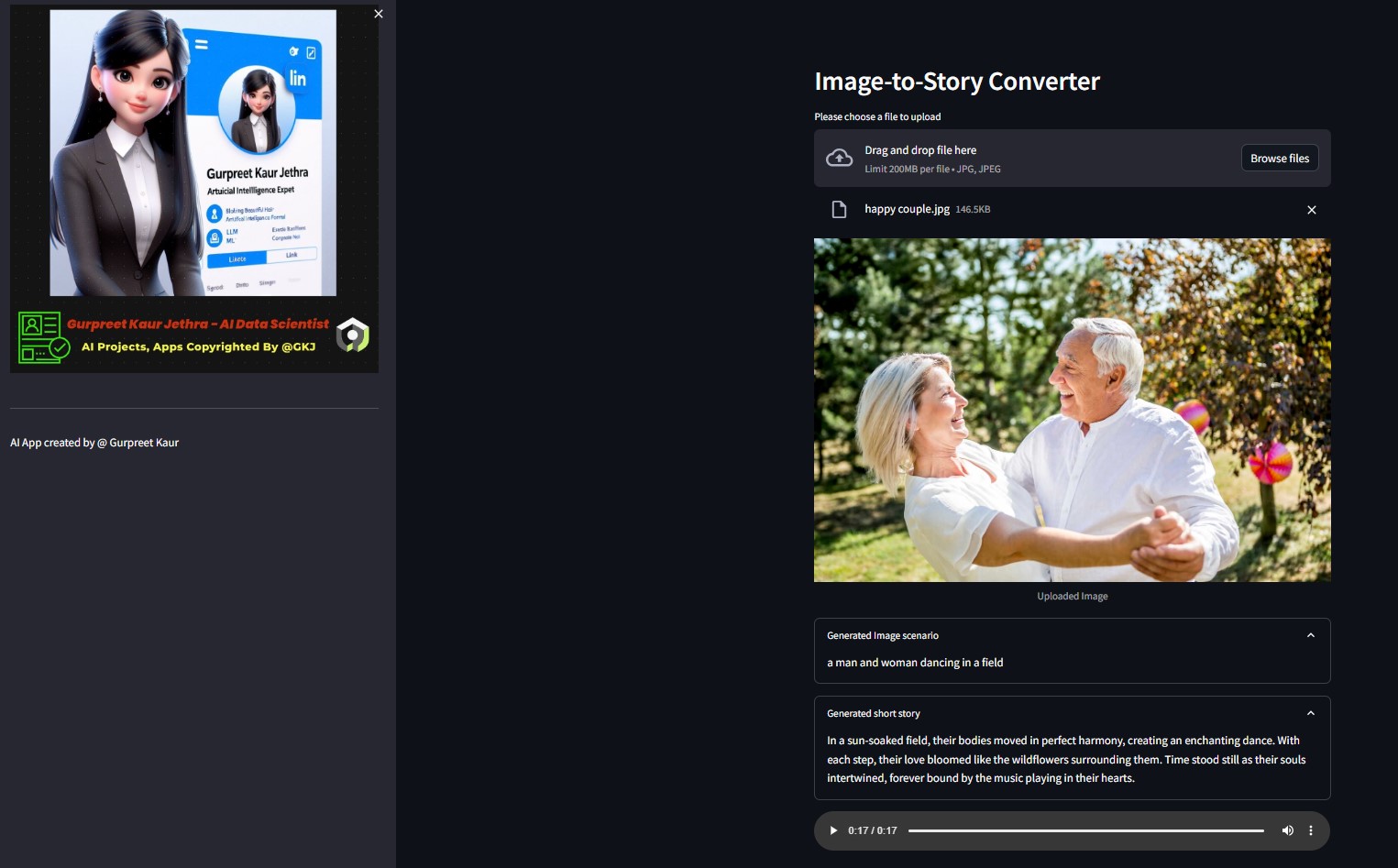
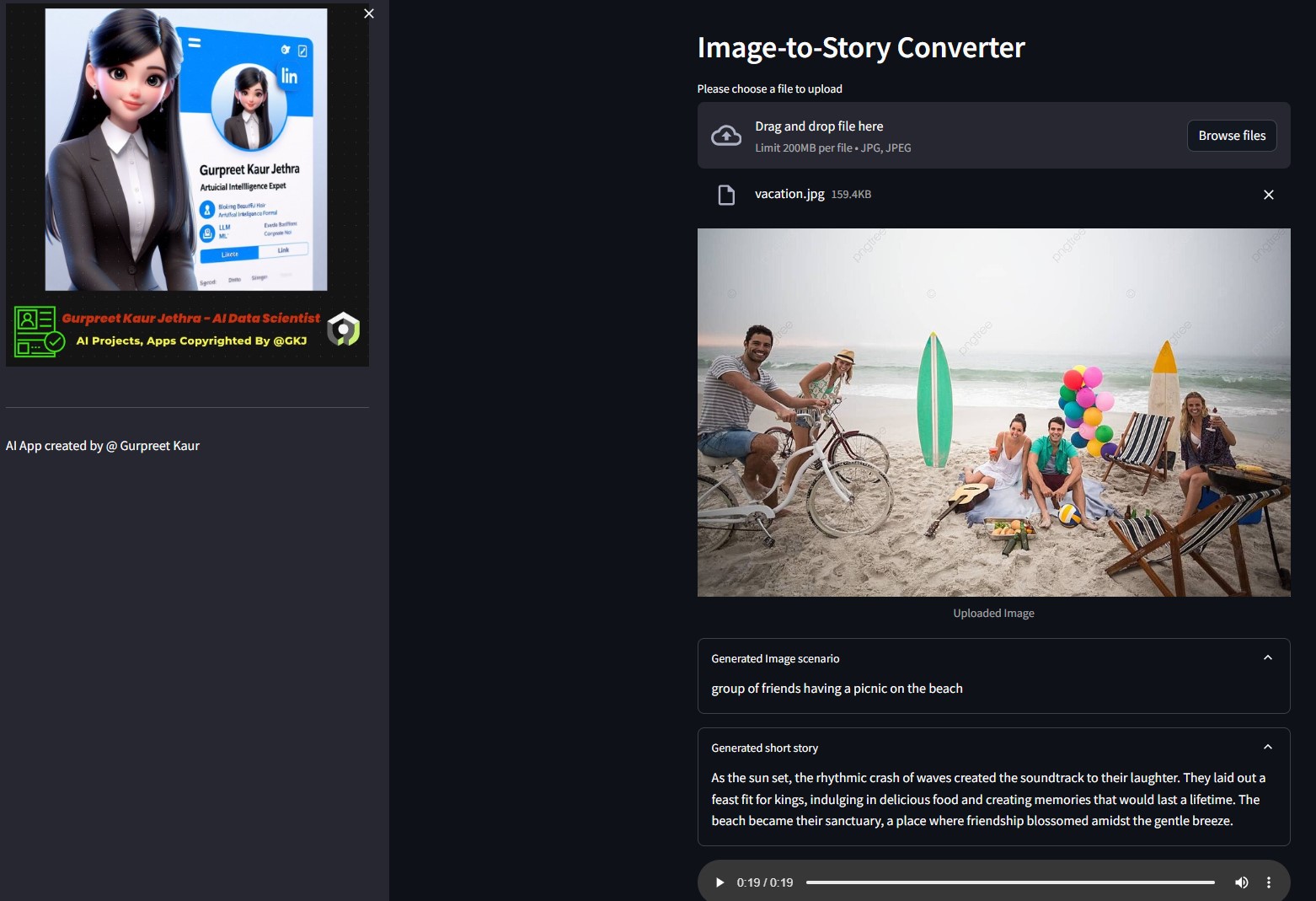
Вы можете прослушать соответствующий аудиофайл этих тестовых демонстрационных изображений в соответствующей папке img-audio .
?Системный дизайн
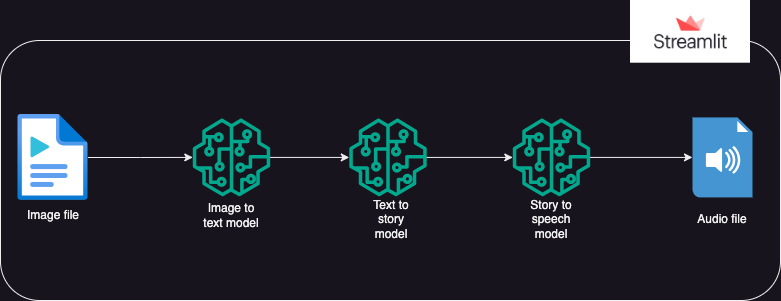
?Подход
Приложение, которое использует модели Hugging Face AI для генерации текста из изображения, которое затем генерирует звук из текста.
Исполнение разделено на 3 части:
- Изображение в текст: модель преобразования изображения в текст (Salesforce/blip-image-captioning-base) используется для создания текстового сценария на основе понимания ИИ контекста изображения.
- Текст в историю: модели OpenAI LLM предлагается создать короткий рассказ (50 слов: можно изменить по мере необходимости) на основе сгенерированного сценария. gpt-3.5-турбо
- История в речь: модель преобразования текста в речь (espnet/kan-bayashi_ljspeech_vits) используется для преобразования сгенерированного рассказа в аудиофайл с голосовым сопровождением.
- Пользовательский интерфейс построен с использованиемstreamlit, позволяющего загружать изображение и воспроизводить аудиофайл.
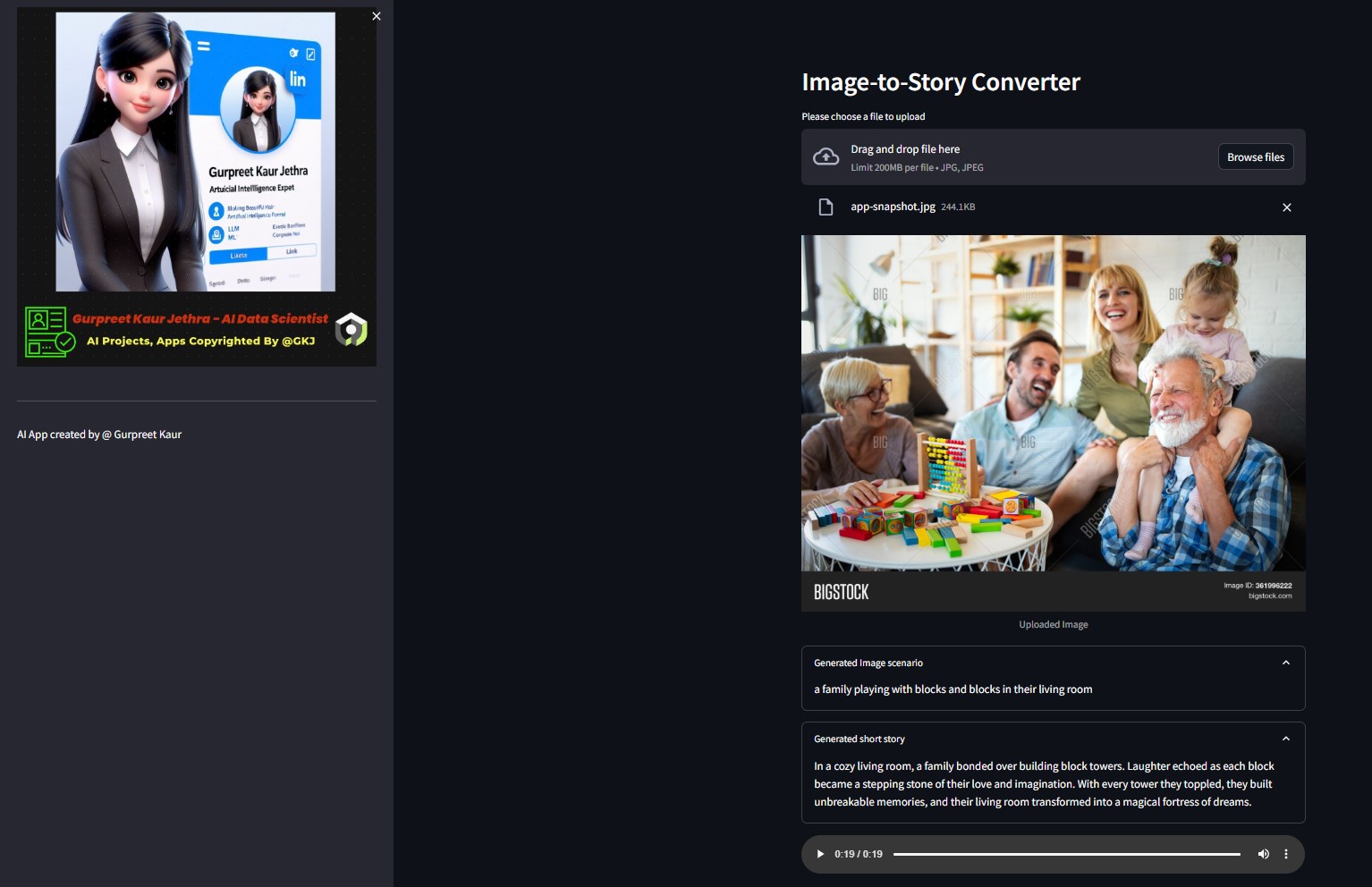 Вы можете прослушать соответствующий аудиофайл этого тестового изображения в соответствующей папке
Вы можете прослушать соответствующий аудиофайл этого тестового изображения в соответствующей папке img-audio .
?Требования
- ОС
- python-dotenv
- трансформаторы
- факел
- Лангчейн
- опенай
- запросы
- освещенный потоком света
Использование
- Перед использованием приложения пользователю необходимо иметь персональные токены Hugging Face и Open AI.
- Пользователь должен настроить среду venv и установить библиотеку ipykernel для запуска приложения в локальной системе.
- Пользователь должен сохранить личные токены в файле «.env» внутри пакета в виде строковых объектов под именами объектов: HUGGINGFACE_TOKEN и OPENAI_TOKEN.
- Затем пользователь может запустить приложение с помощью команды:streamlit run app.py.
- Как только приложение заработает на потоке, пользователь может загрузить целевое изображение.
- Выполнение начнется автоматически и может занять несколько минут.
- После завершения приложение отобразит:
- Текст сценария, сгенерированный преобразователем изображения в текст моделью HuggingFace.
- Краткая история, созданная по инициативе OpenAI LLM
- Аудиофайл, повествующий рассказ, созданный с помощью модели преобразователя текста в речь.
- Развернуто приложение Gen AI в облаке с подсветкой и Hugging Space.
▶️ Установка
Клонируем репозиторий:
git clone https://github.com/GURPREETKAURJETHRA/Image-to-Speech-GenAI-Tool-Using-LLM.git
Установите необходимые пакеты Python:
pip install -r requirements.txt
Настройте ключ API OpenAI и токен Hugging Face, создав файл .env в корневом каталоге проекта со следующим содержимым:
OPENAI_API_KEY=<your-api-key-here> HUGGINGFACE_API_TOKEN=<<your-access-token-here>
Запустите приложение Streamlit:
streamlit run app.py
©️ Лицензия
Распространяется по лицензии MIT. См. LICENSE для получения дополнительной информации.
Если вам нравится этот проект LLM, зайдите в этот репозиторий, и вклады приветствуются! Если у вас есть какие-либо предложения по улучшению этого конвертера AI Img-Speech, отправьте запрос на включение.
Следуй за мной


