BinaryVectorDB
1.0.0
Этот репозиторий содержит базу данных двоичных векторов для эффективного поиска в больших наборах данных, предназначенную для образовательных целей.
Большинство моделей внедрения представляют свои векторы как float32: они потребляют много памяти, и поиск по ним происходит очень медленно. В Cohere мы представили первую модель внедрения с встроенной поддержкой int8 и двоичных файлов, которая обеспечивает превосходное качество поиска за небольшую часть стоимости:
| Модель | Качество поиска MIRACL | Время искать в 1 млн документов | Требуемая память: 250 МБ Вложений Википедии | Цена на AWS (экземпляр x2 ГБ) |
|---|---|---|---|---|
| OpenAI text-embedding-3-маленький | 44,9 | 680 мс | 1431 ГБ | 65 231 долл. США в год |
| OpenAI text-embedding-3-большой | 54,9 | 1240 мс | 2861 ГБ | 130 463 долларов США в год |
| Cohere Embed v3 (многоязычный) | ||||
| Встроить v3 - float32 | 66,3 | 460 мс | 954 ГБ | 43 488 долларов в год |
| Встроить v3 – двоичный файл | 62,8 | 24 мс | 30 ГБ | 1359 долларов США в год |
| Встроить v3 — двоичный файл + восстановление int8 | 66,3 | 28 мс | Память 30 ГБ + диск 240 ГБ | 1589 долларов в год |
Мы создали демо-версию, которая позволяет вам искать в 100M Wikipedia Embeddings виртуальную машину стоимостью всего 15 долларов в месяц: Демо — поиск в 100M Wikipedia Embeddings всего за 15 долларов в месяц.
Вы можете легко использовать BinaryVectorDB для своих собственных данных.
Настройка проста:
pip install BinaryVectorDB
Чтобы использовать некоторые из приведенных ниже примеров, вам понадобится ключ API Cohere (бесплатный или платный) с сайта cohere.com. Вы должны установить этот ключ API как переменную среды: export COHERE_API_KEY=your_api_key
Позже мы покажем, как построить векторную БД на собственных данных. Для начала давайте воспользуемся предварительно созданной базой данных бинарных векторов . Мы размещаем различные готовые базы данных на https://huggingface.co/datasets/Cohere/BinaryVectorDB. Вы можете скачать их и использовать локально.
Для начала давайте воспользуемся простой английской версией из Википедии:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
А затем разархивируйте этот файл:
unzip wikipedia-2023-11-simple.zip
Вы можете легко загрузить базу данных, указав ей разархивированную папку из предыдущего шага:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )База данных имеет 646 424 встраивания и общий размер 962 МБ. Однако в память загружается всего 80 МБ для двоичных вложений. Документы и их внедрения int8 хранятся на диске и загружаются только при необходимости.
Такое разделение двоичных вложений в памяти и вложений int8 и документов на диске позволяет нам масштабироваться до очень больших наборов данных без необходимости использования тонн памяти.
Создать собственную базу данных двоичных векторов довольно легко.
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) Документ может быть любым сериализуемым объектом Python. Вам необходимо предоставить функцию для docs2text , которая сопоставляет ваш документ со строкой. В приведенном выше примере мы объединяем заголовок и текстовое поле. Эта строка отправляется в модель внедрения для создания необходимых внедрений текста.
Добавлять/удалять/обновлять документы легко. См. example/add_update_delete.py для примера сценария добавления/обновления/удаления документов в базе данных.
Мы анонсировали наши встраивания Cohere int8 и двоичные встраивания, которые обеспечивают сокращение необходимой памяти в 4 и 32 раза. Кроме того, это дает ускорение векторного поиска до 40 раз.
Оба метода объединены в BinaryVectorDB. В качестве примера предположим, что это английская Википедия с 42 млн вложений. Обычным встраиваниям float32 потребуется 42*10^6*1024*4 = 160 GB памяти только для размещения вложений. Поскольку поиск по float32 выполняется довольно медленно (около 45 секунд при 42M встраиваниях), нам нужно добавить индекс, например HNSW, который добавляет еще 20 ГБ памяти, поэтому в общей сложности вам понадобится 180 ГБ.
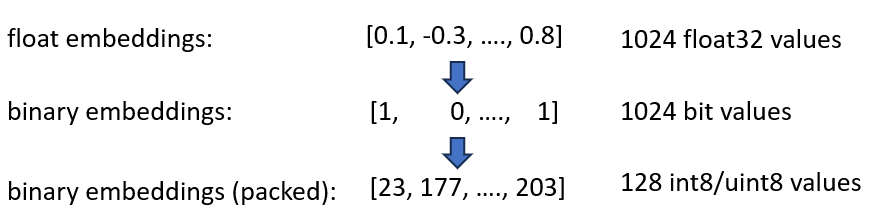
Двоичные представления представляют каждое измерение как 1 бит. Это уменьшает потребность в памяти до 160 GB / 32 = 5GB . Кроме того, поскольку поиск в двоичном пространстве выполняется в 40 раз быстрее, во многих случаях индекс HNSW больше не нужен. Вы сократили потребность в памяти со 180 ГБ до 5 ГБ, то есть хорошая экономия в 36 раз.
Когда мы запрашиваем этот индекс, мы также кодируем запрос в двоичном формате и используем расстояние Хэмминга. Расстояние Хэмминга измеряет разницу в 1 бит между двумя векторами. Это чрезвычайно быстрая операция: для сравнения двух двоичных векторов вам достаточно 2-х процессорных циклов: popcount(xor(vector1, vector2)) . XOR — самая фундаментальная операция на процессорах, поэтому она выполняется очень быстро. popcount подсчитывает число 1 в регистре, для чего также требуется всего 1 цикл процессора.
В целом это дает нам решение, которое сохраняет около 90% качества поиска.
Мы можем повысить качество поиска по сравнению с предыдущим шагом с 90% до 95% с помощью переоценки <float, binary> .
Мы берем, например, 100 лучших результатов из шага 1 и вычисляем dot_product(query_float_embedding, 2*binary_doc_embedding-1) .
Предположим, что наше внедрение запроса — [0.1, -0.3, 0.4] а наше внедрение двоичного документа — [1, 0, 1] . Затем на этом этапе вычисляется:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

Мы используем эти оценки и переоцениваем наши результаты. Это повышает качество поиска с 90% до 95%. Эту операцию можно выполнить очень быстро: мы получаем встраивание числа с плавающей точкой запроса из модели внедрения, двоичные представления находятся в памяти, поэтому нам просто нужно выполнить 100 операций суммирования.
Для дальнейшего улучшения качества поиска с 95% до 99,99% мы используем переоценку int8 с диска.
Мы сохраняем все встраивания документов int8 на диск. Затем мы берем топ-30 из предыдущего шага, загружаем int8-embeddings с диска и вычисляем cossim(query_float_embedding, int8_doc_embedding_from_disk)
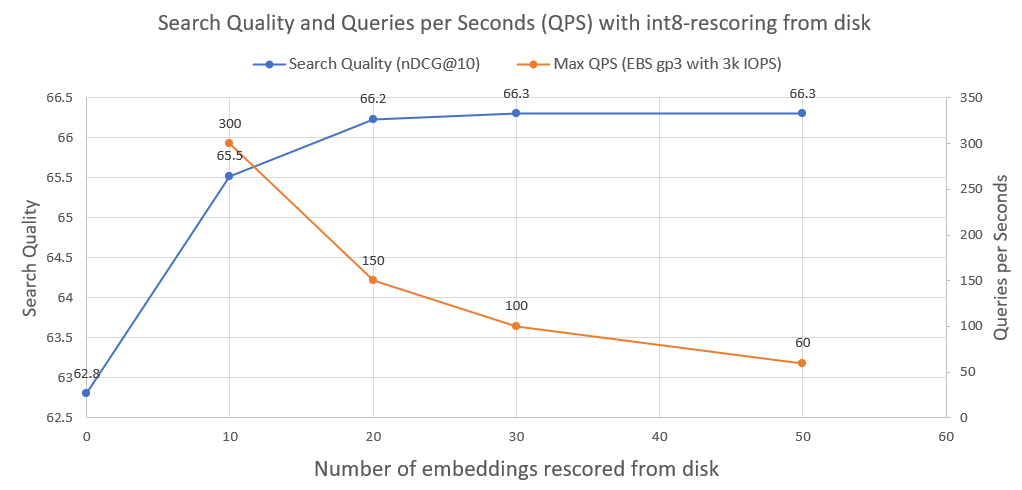
На следующем изображении вы можете увидеть, насколько int8-оцифрован и улучшена производительность поиска:
Мы также построили график количества запросов в секунду, которого может достичь такая система при работе на обычном сетевом диске AWS EBS с производительностью 3000 операций ввода-вывода в секунду. Как мы видим, чем больше вложений int8 нам нужно загрузить с диска, тем меньше QPS.
Для выполнения двоичного поиска мы используем индекс IndexBinaryFlat от faiss. Он просто хранит двоичные вложения, обеспечивает сверхбыструю индексацию и сверхбыстрый поиск.
Для хранения документов и вложений int8 мы используем RocksDict, дисковое хранилище «ключ-значение» для Python на основе RocksDB.
См. BinaryVectorDB для полной реализации класса.
Не совсем. Репозиторий предназначен в основном для образовательных целей, чтобы показать методы масштабирования для больших наборов данных. Основное внимание уделялось простоте использования, и в реализации отсутствуют некоторые важные аспекты, такие как многопроцессная безопасность, откаты и т. д.
Если вы действительно хотите заняться производством, используйте подходящую векторную базу данных, например Vespa.ai, которая позволит вам достичь аналогичных результатов.
В Cohere мы помогли клиентам запустить семантический поиск на десятках миллиардов вложений за небольшую плату. Не стесняйтесь обращаться к Нильсу Реймерсу, если вам нужно масштабируемое решение.


