VideoX
1.0.0
Это коллекция наших работ по видеопониманию.
SeqTrack (
@CVPR'23): SeqTrack: последовательное обучение для визуального отслеживания объектов
X-CLIP (
@ECCV'22 Oral): расширение предварительно обученных моделей языка и изображения для общего распознавания видео
MS-2D-TAN (
@TPAMI'21): многомасштабные 2D временные смежные сети для мгновенной локализации с использованием естественного языка.
2D-TAN (
@AAAI'20): изучение двухмерных временных смежных сетей для мгновенной локализации с помощью естественного языка
Набираем стажеров-исследователей с сильными навыками программирования: [email protected] | [email protected]
Апрель 2023 г.: выпущен код для SeqTrack .
Февраль 2023 г.: SeqTrack принят на CVPR'23.
Сентябрь 2022 г.: X-CLIP теперь интегрирован в
Август 2022 г.: выпущен код для X-CLIP .
Июль 2022 г.: X-CLIP принят на ECCV'22 как Oral.
Октябрь 2021 г.: выпущен код для MS-2D-TAN .
Сентябрь 2021 г.: МС-2Д-ТАН принят на TPAMI'21.
Декабрь 2019 г.: выпущен код для 2D-TAN .
Ноябрь 2019 г.: 2D-TAN принят на AAAI'20.
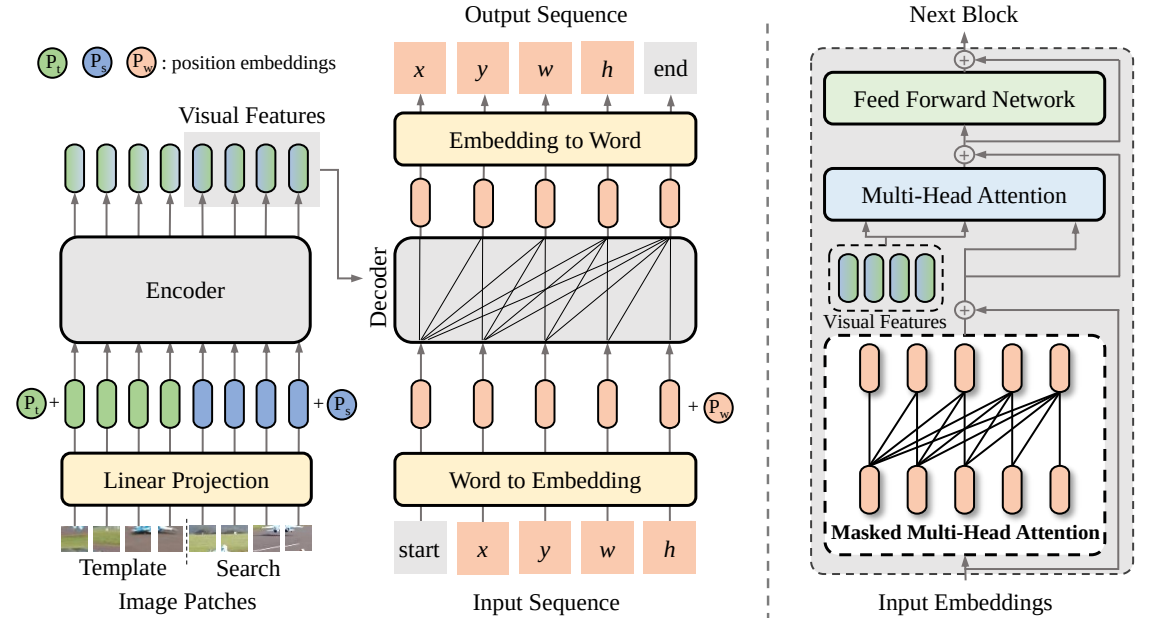
В этой статье мы предлагаем новую систему последовательного обучения для визуального отслеживания, получившую название SeqTrack. Он рассматривает визуальное отслеживание как задачу генерации последовательности, которая предсказывает ограничивающие объекты объекты авторегрессионным способом. SeqTrack использует только простую архитектуру преобразователя кодер-декодер. Кодер извлекает визуальные признаки с помощью двунаправленного преобразователя, а декодер генерирует последовательность значений ограничивающего прямоугольника авторегрессионно с помощью причинного декодера. Функция потерь представляет собой простую перекрестную энтропию. Такая парадигма последовательного обучения не только упрощает систему отслеживания, но и обеспечивает конкурентоспособную производительность по многим критериям.
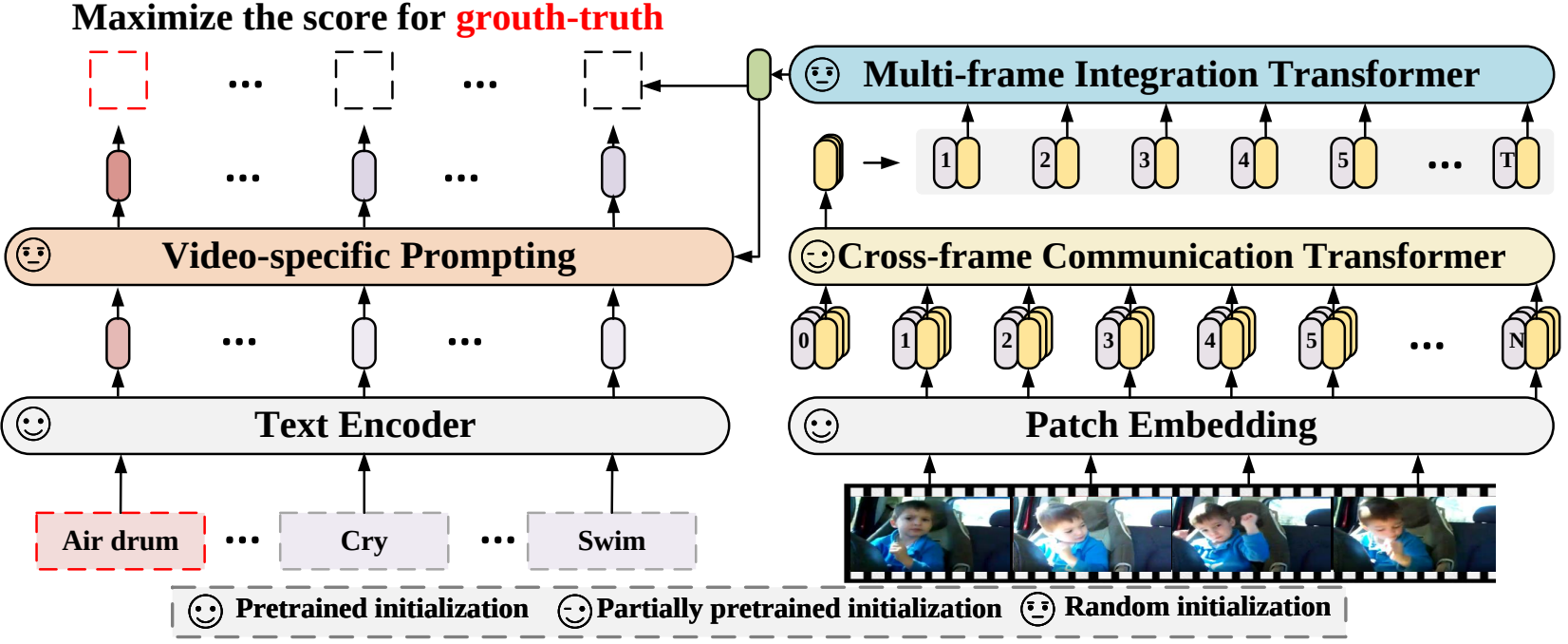
В этой статье мы предлагаем новую структуру распознавания видео, которая адаптирует предварительно обученные модели языка и изображения для распознавания видео. В частности, для захвата временной информации мы предлагаем механизм межкадрового внимания, который явно обменивается информацией между кадрами. Чтобы использовать текстовую информацию в категориях видео, мы разрабатываем специальную технику подсказок, которая может обеспечить различительное текстовое представление на уровне экземпляра. Обширные эксперименты показывают, что наш подход эффективен и может быть распространен на различные сценарии распознавания видео, включая полностью контролируемый, малокадровый и нулевой.
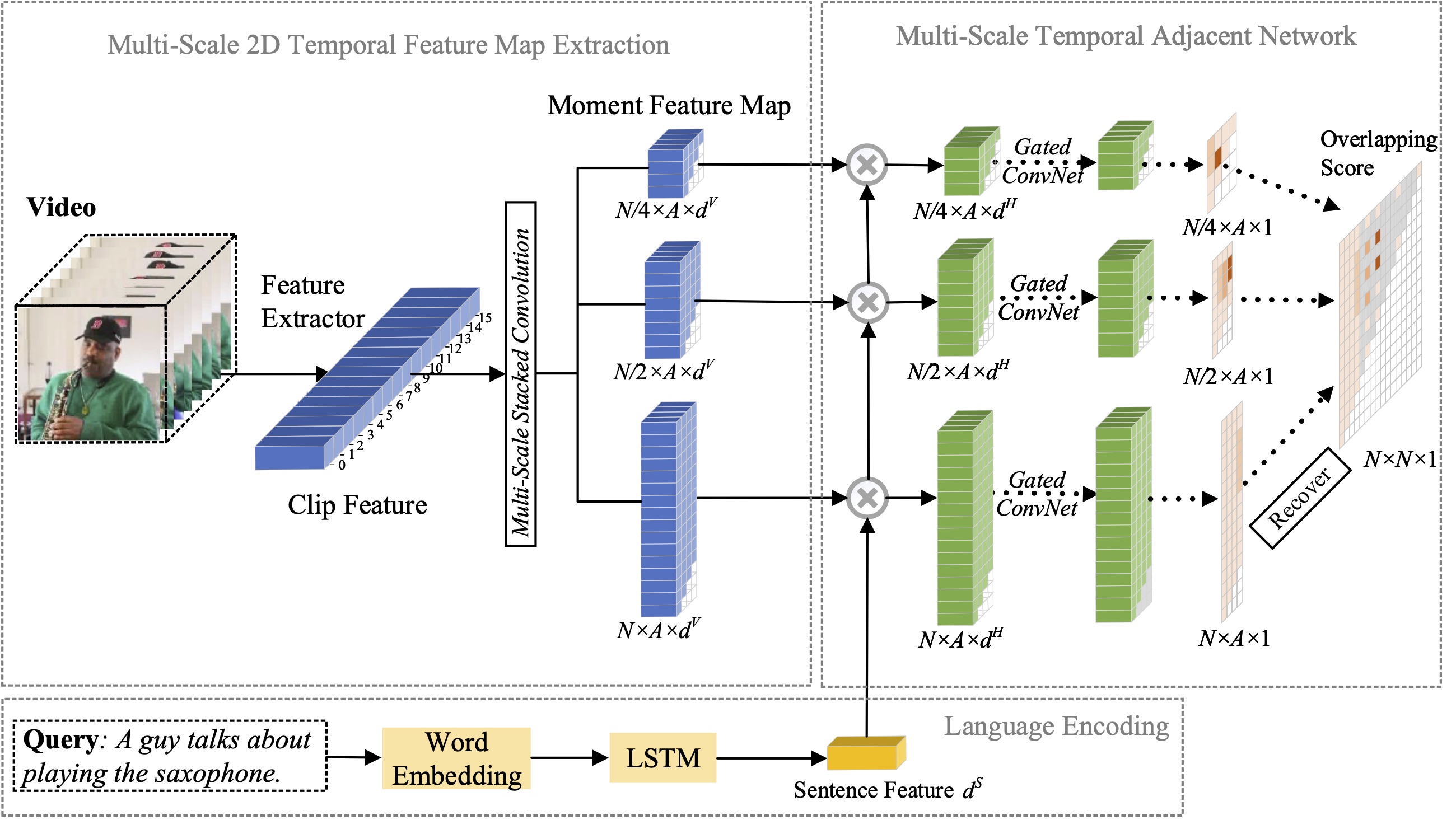
В этой статье мы изучаем проблему локализации моментов на естественном языке и предлагаем расширить наш предыдущий предложенный метод 2D-TAN до многомасштабной версии. Основная идея состоит в том, чтобы получить момент из двумерных временных карт в разных временных масштабах, при этом соседние кандидаты момента рассматриваются как временной контекст. Расширенная версия способна кодировать соседние временные отношения в разных масштабах, одновременно изучая отличительные функции для сопоставления видеомоментов с относящимися к ним выражениями. Наша модель проста по конструкции и обеспечивает конкурентоспособную производительность по сравнению с современными методами на трех контрольных наборах данных.
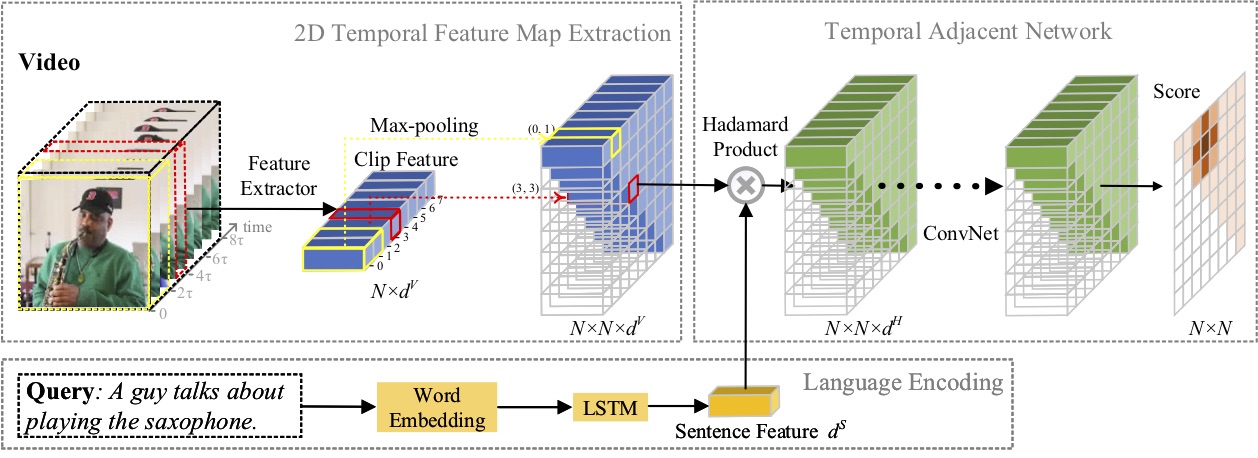
В этой статье мы изучаем проблему локализации моментов на естественном языке и предлагаем новый метод 2D-временных смежных сетей (2D-TAN). Основная идея состоит в том, чтобы получить момент на двумерной временной карте, которая рассматривает соседние кандидаты на момент как временной контекст. 2D-TAN способен кодировать смежные временные отношения, одновременно изучая отличительные функции для сопоставления видеомоментов с относящимися к ним выражениями. Наша модель проста по конструкции и обеспечивает конкурентоспособную производительность по сравнению с современными методами на трех контрольных наборах данных.
@InProceedings{SeqTrack, title={SeqTrack: последовательное обучение для визуального отслеживания объектов}, автор={Чен, Синь и Пэн, Хоувэнь и Ван, Донг и Лу, Хучуань и Ху, Хань}, booktitle={CVPR}, год={2023}}@InProceedings{XCLIP, title={Расширение предварительно обученных моделей языка и изображения для общего видео Признание}, автор={Ни, Болин и Пэн, Хоувэнь и Чен, Минхао и Чжан, Сунъян и Мэн, Гаофэн и Фу, Цзяньлун и Сян, Шиминг и Лин, Хайбин}, booktitle={Европейская конференция по компьютерному зрению (ECCV) }, год={2022}}@InProceedings{Zhang2021MS2DTAN,
автор = {Чжан, Сунъян и Пэн, Хоувэнь и Фу, Цзяньлун и Лу, Ицзюань и Ло, Цзебо},
title = {Многомасштабные 2D-смежные временные сети для мгновенной локализации на естественном языке},
booktitle = {TPAMI},
год = {2021}}@InProceedings{2DTAN_2020_AAAI,
автор = {Чжан, Сунъян и Пэн, Хоувэнь и Фу, Цзяньлун и Ло, Цзебо},
title = {Изучение двухмерных временных смежных сетей для мгновенной локализации с использованием естественного языка},
название книги = {AAAI},
год = {2020}}Лицензия по лицензии MIT.


