horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod — это распределенная платформа обучения глубокому обучению для TensorFlow, Keras, PyTorch и Apache MXNet. Цель Horovod — сделать распределенное глубокое обучение быстрым и простым в использовании.
Хоровод организован Фондом LF AI & Data (LF AI & Data). Если вы — компания, которая глубоко привержена использованию технологий с открытым исходным кодом в области искусственного интеллекта, машин и глубокого обучения и хотите поддерживать сообщества проектов с открытым исходным кодом в этих областях, рассмотрите возможность присоединения к LF AI & Data Foundation. Подробности о том, кто в этом участвует и какую роль играет Хоровод, читайте в объявлении Linux Foundation.
Содержание
Основная мотивация этого проекта — упростить использование сценария обучения для одного графического процессора и успешно масштабировать его для параллельного обучения на многих графических процессорах. Это имеет два аспекта:
Внутри Uber мы обнаружили, что модель MPI гораздо более проста и требует гораздо меньше изменений кода, чем предыдущие решения, такие как Distributed TensorFlow с серверами параметров. После того, как сценарий обучения будет написан для масштабирования с помощью Horovod, он может работать на одном, нескольких графических процессорах или даже на нескольких хостах без каких-либо дальнейших изменений кода. Более подробную информацию смотрите в разделе «Использование».
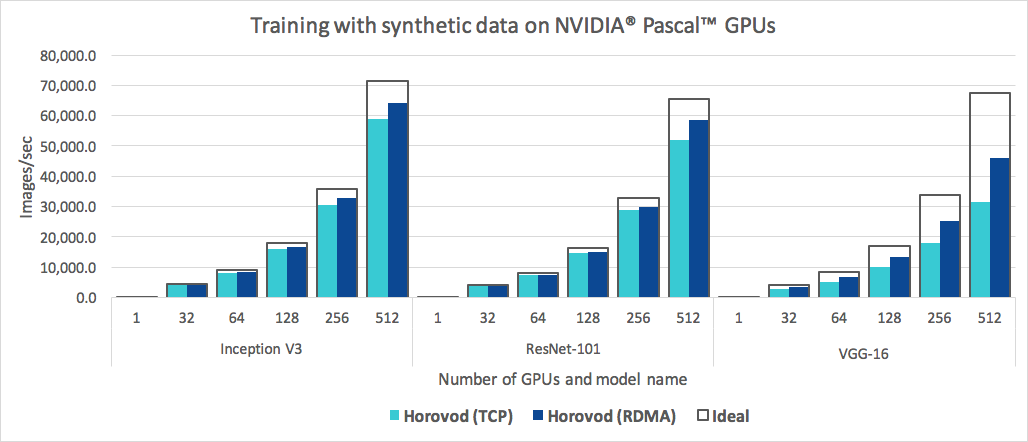
Помимо простоты использования, Horovod работает быстро. Ниже приведена диаграмма, представляющая тест, который был выполнен на 128 серверах с 4 графическими процессорами Pascal, каждый из которых был подключен сетью 25 Гбит/с с поддержкой RoCE:
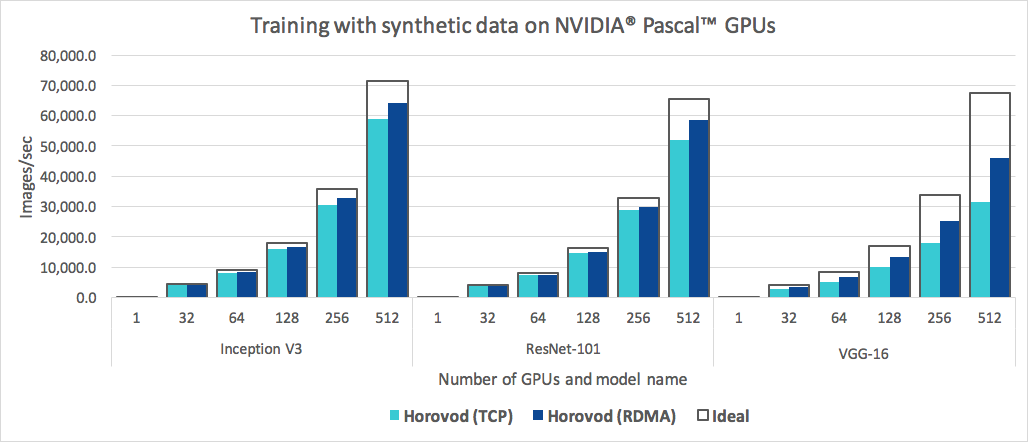
Horovod достигает эффективности масштабирования 90 % для Inception V3 и ResNet-101 и эффективности масштабирования 68 % для VGG-16. См. «Бенчмарки», чтобы узнать, как воспроизвести эти цифры.
Хотя установка MPI и NCCL сама по себе может показаться дополнительной проблемой, ее нужно сделать только один раз команде, занимающейся инфраструктурой, в то время как все остальные в компании, создающие модели, могут наслаждаться простотой их обучения в масштабе.
Чтобы установить Хоровод на Linux или macOS:
Если вы установили TensorFlow из PyPI, убедитесь, что установлен g++-5 или выше. Начиная с TensorFlow 2.10 потребуется компилятор, совместимый с C++17, например g++8 или выше.
Если вы установили PyTorch из PyPI, убедитесь, что установлен g++-5 или выше.
Если вы установили какой-либо пакет из Conda, убедитесь, что установлен пакет Conda gxx_linux-64 .
Установите пакет horovod pip.
Для запуска на процессорах:
$ pip install horovodДля запуска на графических процессорах с NCCL:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodДополнительные сведения об установке Horovod с поддержкой графического процессора см. в разделе Horovod на графическом процессоре.
Полный список вариантов установки Horovod читайте в Руководстве по установке.
Если вы хотите использовать MPI, прочтите Хоровод с MPI.
Если вы хотите использовать Conda, прочтите «Создание среды Conda с поддержкой графического процессора для Horovod».
Если вы хотите использовать Docker, прочтите Хоровод в Docker.
Чтобы скомпилировать Хоровод из исходного кода, следуйте инструкциям в Руководстве для участников.
Основные принципы Horovod основаны на таких понятиях MPI, как размер , ранг , локальный ранг , allreduce , allgather , широковещательная рассылка и alltoall . См. эту страницу для более подробной информации.
На этих страницах вы найдете примеры и лучшие практики Хоровода:
Чтобы использовать Хоровод, внесите в свою программу следующие дополнения:
hvd.init() для инициализации Хоровода.Прикрепите каждый графический процессор к одному процессу, чтобы избежать конкуренции за ресурсы.
При типичной настройке одного графического процессора на процесс установите для него локальный ранг . Первому процессу на сервере будет выделен первый графический процессор, второму процессу будет выделен второй графический процессор и т. д.
Масштабируйте скорость обучения по количеству работников.
Эффективный размер пакета при синхронном распределенном обучении масштабируется по количеству работников. Увеличение скорости обучения компенсирует увеличение размера пакета.
Оберните оптимизатор в hvd.DistributedOptimizer .
Распределенный оптимизатор делегирует вычисление градиента исходному оптимизатору, усредняет градиенты с помощью allreduce или allgather , а затем применяет эти усредненные градиенты.
Передайте начальные состояния переменных с ранга 0 всем остальным процессам.
Это необходимо для обеспечения согласованной инициализации всех воркеров при запуске обучения со случайными весами или восстановлении с контрольной точки.
Пример использования TensorFlow v1 (полные обучающие примеры см. в каталоге примеров):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )В примерах команд ниже показано, как запустить распределенное обучение. Дополнительные сведения см. в разделе «Запуск Хоровода», включая настройки RoCE/InfiniBand и советы по устранению зависаний.
Для запуска на машине с 4 графическими процессорами:
$ horovodrun -np 4 -H localhost:4 python train.pyДля запуска на 4 машинах с 4 графическими процессорами на каждой:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py Чтобы запустить Horovod с помощью Open MPI без оболочки horovodrun , см. Запуск Horovod с Open MPI.
Чтобы запустить в Docker, см. Хоровод в Docker.
Для работы в Kubernetes см. Helm Chart, Оператор Kubeflow MPI, FfDL и Polyaxon.
Чтобы запустить Spark, см. Хоровод на Spark.
Чтобы бежать на Рэе, см. Хоровод на Рэе.
Чтобы запустить Singularity, см. Singularity.
Для работы в кластере LSF HPC (например, Summit) см. LSF.
Чтобы работать с Hadoop Yarn, см. TonY.
Gloo — это библиотека коллективного общения с открытым исходным кодом, разработанная Facebook.
Gloo входит в состав Horovod и позволяет пользователям запускать Horovod без необходимости установки MPI.
Для сред, поддерживающих как MPI, так и Gloo, вы можете использовать Gloo во время выполнения, передав аргумент --gloo в horovodrun :
$ horovodrun --gloo -np 2 python train.pyHorovod поддерживает смешивание и сопоставление коллективов Horovod с другими библиотеками MPI, такими как mpi4py, при условии, что MPI был создан с поддержкой многопоточности.
Вы можете проверить поддержку многопоточности MPI, запросив функцию hvd.mpi_threads_supported() .
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()Вы также можете инициализировать Horovod с помощью субкоммуникатора mpi4py, и в этом случае каждый субкоммуникатор будет запускать независимое обучение Horovod.
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))Узнайте, как оптимизировать свою модель для вывода и удалить операции Хоровода из графика здесь.
Одной из уникальных особенностей Horovod является его способность чередовать обмен данными и вычисления в сочетании с возможностью пакетной обработки небольших операций allreduce , что приводит к повышению производительности. Мы называем эту функцию пакетной обработки Tensor Fusion.
Подробную информацию и инструкции по настройке можно найти здесь.
Horovod имеет возможность записывать временную шкалу своей деятельности, называемую Horovod Timeline.
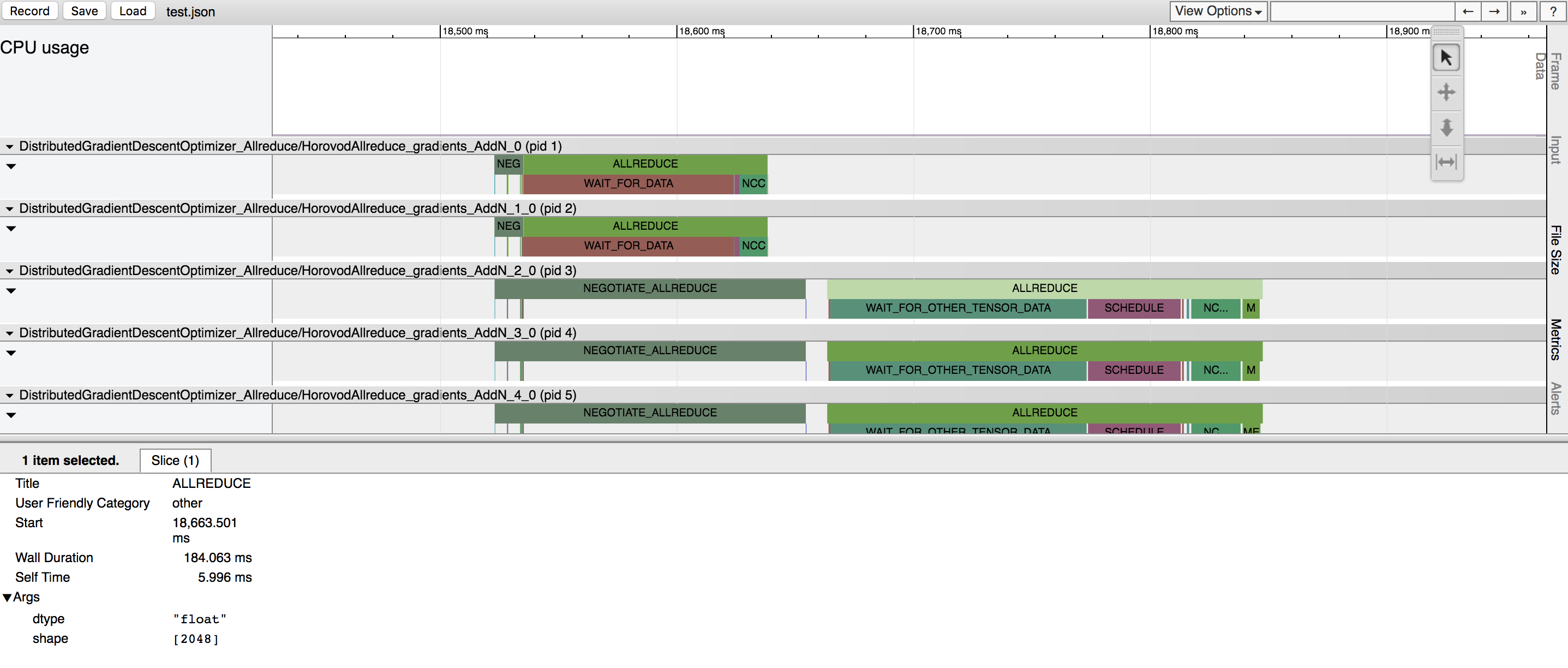
Используйте временную шкалу Horovod для анализа производительности Horovod. Подробную информацию и инструкции по использованию смотрите здесь.
Выбор правильных значений для эффективного использования Tensor Fusion и других расширенных функций Horovod может потребовать большого количества проб и ошибок. Мы предоставляем систему для автоматизации этого процесса оптимизации производительности, называемую автонастройкой , которую вы можете включить с помощью одного аргумента командной строки для horovodrun .
Подробную информацию и инструкции по использованию смотрите здесь.
Хоровод позволяет одновременно выполнять отдельные коллективные операции в разных группах процессов, участвующих в одном распределенном обучении. Настройте объекты hvd.process_set , чтобы использовать эту возможность.
Подробные инструкции см. в разделе «Наборы процессов».
Отправьте нам ссылки на любые руководства пользователя, которые вы хотите опубликовать на этом сайте.
См. раздел «Устранение неполадок» и отправьте заявку, если не можете найти ответ.
Пожалуйста, цитируйте Хоровода в своих публикациях, если это поможет вашему исследованию:
@article{sergeev2018horovod,
Автор = {Александр Сергеев и Майк Дель Бальсо},
Журнал = {препринт arXiv arXiv:1802.05799},
Title = {Горовод: быстрое и простое распределенное глубокое обучение в {TensorFlow}},
Год = {2018}
}
1. Сергеев А., Дель Бальсо М. (2017) Знакомьтесь: Хоровод: распределенная платформа глубокого обучения Uber с открытым исходным кодом для TensorFlow . Получено с https://eng.uber.com/horovod/.
2. Сергеев А. (2017) Хоровод — Distributed TensorFlow Made Easy . Получено с https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy.
3. Сергеев А., Дель Бальсо М. (2018) Хоровод: быстрое и простое распределенное глубокое обучение в TensorFlow . Получено из arXiv: 1802.05799.
Исходный код Horovod был основан на репозитории Baidu tensorflow-allreduce, написанном Эндрю Гибиански и Джоэлом Хестнессом. Их оригинальная работа описана в статье «Привнесение технологий HPC в глубокое обучение».