LLM4Decompile
1.0.0
![]()
Результаты | ? Модели | Быстрый старт | HumanEval-Декомпиляция | ? Цитирование | Бумага | Колаб |
Реверс-инжиниринг: декомпиляция двоичного кода с помощью больших языковых моделей
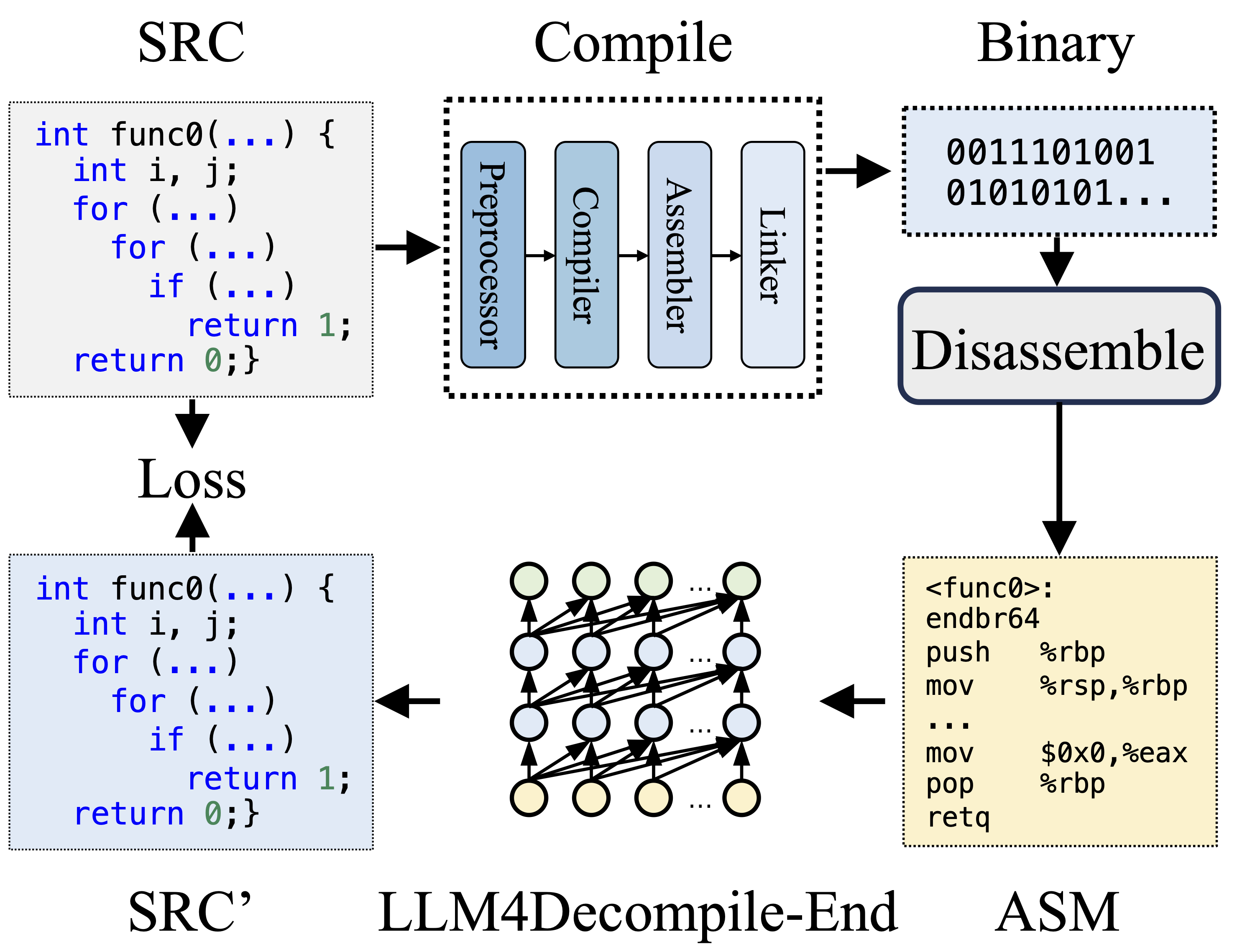
Во время компиляции препроцессор обрабатывает исходный код (SRC) для устранения комментариев и расширения макросов или включений. Очищенный код затем передается компилятору, который преобразует его в ассемблерный код (ASM). Этот ASM преобразуется ассемблером в двоичный код (0 и 1). Компоновщик завершает процесс, связывая вызовы функций для создания исполняемого файла. С другой стороны, декомпиляция предполагает преобразование двоичного кода обратно в исходный файл. LLM, обучающиеся работе с текстом, не имеют возможности напрямую обрабатывать двоичные данные. Поэтому двоичные файлы необходимо сначала дизассемблировать с помощью Objdump на язык ассемблера (ASM). Следует отметить, что двоичный и дизассемблированный ASM эквивалентны, их можно конвертировать друг в друга, и поэтому мы называем их взаимозаменяемыми. Наконец, для целей обучения вычисляются потери между декомпилированным кодом и исходным кодом. Для оценки качества декомпилированного кода (SRC') его функциональность проверяется посредством тестовых утверждений (переисполняемость).
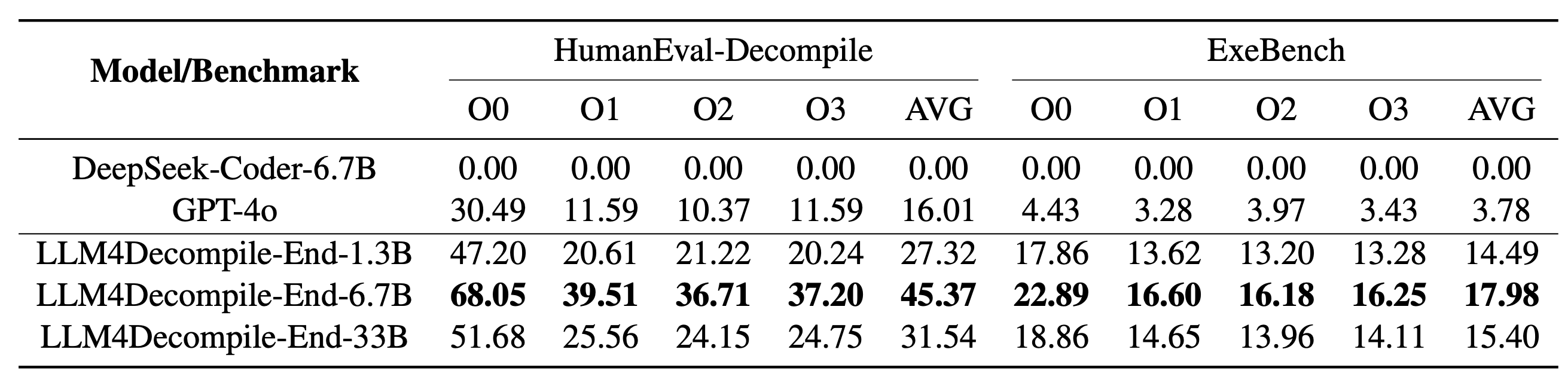
Наша LLM4Decompile включает модели размером от 1,3 до 33 миллиардов параметров, и мы сделали эти модели доступными на Hugging Face.
| Модель | Контрольно-пропускной пункт | Размер | Возможность повторного выполнения | Примечание |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ? ВЧ связь | 1,3Б | 27,3% | Примечание 3 |
| llm4decompile-6.7b-v1.5 | ? ВЧ связь | 6.7Б | 45,4% | Примечание 3 |
| llm4decompile-1.3b-v2 | ? ВЧ связь | 1,3Б | 46,0% | Примечание 4 |
| llm4decompile-6.7b-v2 | ? ВЧ связь | 6.7Б | 52,7% | Примечание 4 |
| llm4decompile-9b-v2 | ? ВЧ связь | 9Б | 64,9% | Примечание 4 |
| llm4decompile-22b-v2 | ? ВЧ связь | 22Б | 63,6% | Примечание 4 |
Примечание 3. Серия V1.5 обучается с использованием большего набора данных (15 миллиардов токенов) и максимального размера токена 4096, что обеспечивает замечательную производительность (улучшение более чем на 100 %) по сравнению с предыдущей моделью.
Примечание 4. Серия V2 построена на Ghidra и обучена на 2 миллиардах токенов для уточнения декомпилированного псевдокода Ghidra. Подробности проверьте в папке Ghidra.
Установка: используйте сценарий ниже, чтобы установить необходимую среду.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
Вот пример использования нашей модели (пересмотрена для версии 1.5. Информацию о предыдущих моделях см. на странице соответствующей модели на сайте HF). Примечание. Замените «func0» именем функции, которую вы хотите декомпилировать .
Предварительная обработка: скомпилируйте код C в двоичный файл и разберите его на инструкции ассемблера.
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )Инструкция по сборке должна быть в формате:
<FUNCTION_NAME>:nOPERATIONSnOPERATIONSn
Типичная инструкция по сборке может выглядеть так:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
Декомпиляция: используйте LLM4Decompile для перевода инструкций ассемблера на C:
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' ) Данные хранятся в llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json в формате списка JSON. Имеется 164*4 (O0, O1, O2, O3) семпла, каждый с пятью клавишами:
task_id : указывает идентификатор проблемы.type : этап оптимизации, один из [O0, O1, O2, O3].c_func : решение C для проблемы HumanEval.c_test : утверждения теста C.input_asm_prompt : инструкции по сборке с подсказками, которые можно получить, как в нашем примере предварительной обработки.Пожалуйста, проверьте сценарии оценки.
Этот репозиторий кода лицензируется по лицензиям MIT и DeepSeek.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


