LRV Instruction
1.0.0
Фусяо Лю, Кевин Линь, Линьцзе Ли, Цзяньфэн Ван, Ясер Якуб, Лицзюань Ван
[Страница проекта] [Бумага]
Вы можете сравнить наши модели и оригинальные модели ниже. Если онлайн-демоверсии не работают, отправьте электронное письмо по [email protected] . Если наша работа вам интересна, пожалуйста, цитируйте ее. Спасибо!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [Демо-версия LRV-V2(Mplug-Owl), [Демо-версия mplug-owl]
[Демонстрация LRV-V1(MiniGPT4), [Демонстрация MiniGPT4-7B]
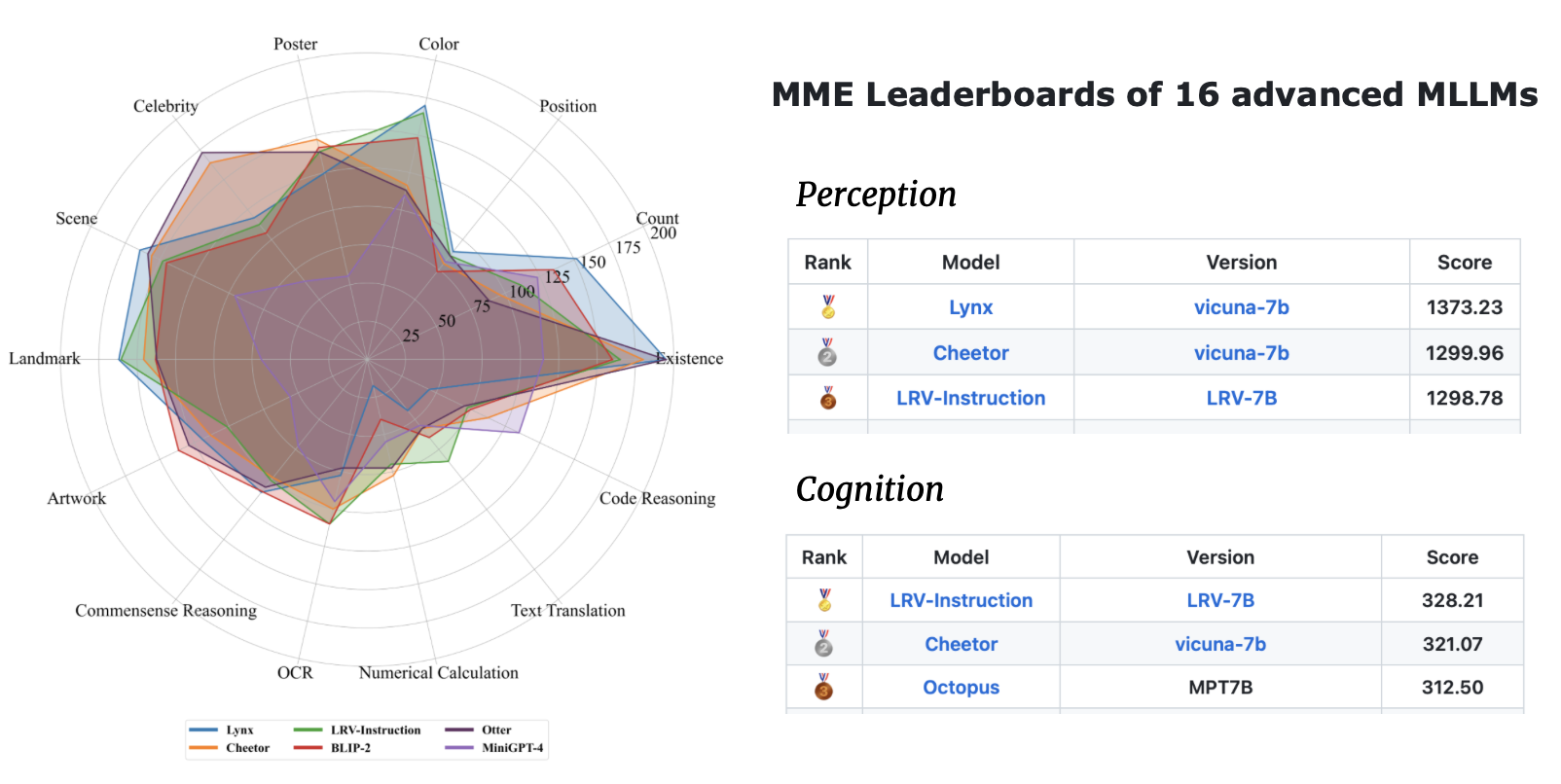
| Название модели | Магистраль | Ссылка для скачивания |
|---|---|---|
| LRV-Инструкция V2 | Mplug-Сова | связь |
| LRV-Инструкция V1 | МиниGPT4 | связь |
| Название модели | Инструкция | Изображение |
|---|---|---|
| Инструкция по ЛРВ | связь | связь |
| Инструкция LRV(Подробнее) | связь | связь |
| Инструкция по диаграмме | связь | связь |
Мы обновляем набор данных 300 тысячами визуальных инструкций, сгенерированных GPT4, охватывающих 16 зрительно-языковых задач с открытыми инструкциями и ответами. Инструкция LRV включает как положительные, так и отрицательные инструкции для более надежной настройки визуальных инструкций. Изображения нашего набора данных взяты из Visual Genome. Доступ к нашим данным можно получить отсюда.
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
Для каждого экземпляра image_id относится к изображению из Visual Genome. question и answer относятся к паре инструкция-ответ. task указывает имя задачи. Вы можете скачать изображения отсюда.
Мы предоставляем подсказки для запросов GPT-4, чтобы облегчить исследования в этой области. Пожалуйста, проверьте папку prompts для создания положительных и отрицательных экземпляров. negative1_generation_prompt.txt содержит подсказку для создания отрицательных инструкций с манипуляцией несуществующим элементом. negative2_generation_prompt.txt содержит подсказку для создания отрицательных инструкций с помощью манипуляции с существующими элементами. Вы можете обратиться к коду здесь, чтобы сгенерировать больше данных. Пожалуйста, смотрите нашу статью для более подробной информации.

1. Клонируйте этот репозиторий
https://github.com/FuxiaoLiu/LRV-Instruction.git2. Установить пакет
conda env create -f environment.yml --name LRV
conda activate LRV3. Подготовьте гири викуньи.
Наша модель доработана на MiniGPT-4 с Vicuna-7B. Пожалуйста, ознакомьтесь с инструкциями здесь, чтобы подготовить гири Vicuna, или загрузите их отсюда. Затем укажите путь к весу Vicuna в MiniGPT-4/minigpt4/configs/models/minigpt4.yaml в строке 15.
4. Подготовьте предварительно обученную контрольную точку нашей модели.
Загрузите предварительно обученные контрольные точки отсюда.
Затем укажите путь к предварительно обученной контрольной точке в MiniGPT-4/eval_configs/minigpt4_eval.yaml в строке 11. Эта контрольная точка основана на MiniGPT-4-7B. В будущем мы выпустим контрольно-пропускные пункты для MiniGPT-4-13B и LLaVA.
5. Установите путь к набору данных.
После получения набора данных укажите путь к набору данных в MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml в строке 5. Структура папки набора данных аналогична следующей:
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. Локальная демоверсия
Попробуйте демо-версию demo.py нашей настроенной модели на своем локальном компьютере, запустив
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
Вы можете попробовать примеры здесь.
7. Модельный вывод
Установите путь к файлу инструкции вывода здесь, папку с изображением вывода здесь и местоположение вывода здесь. Мы не используем логические выводы в процессе обучения.
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. Устанавливаем среду по mplug-owl.
Мы настроили mplug-owl на 8 V100. Если у вас возникнут какие-либо вопросы при реализации на V100, дайте мне знать!
2. Загрузите Контрольно-пропускной пункт
Сначала загрузите контрольную точку mplug-owl по ссылке и вес обученной модели Лоры здесь.
3. Отредактируйте код
Что касается mplug-owl/serve/model_worker.py , отредактируйте следующий код и введите путь к весу модели lora в lora_path.
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. Локальная демоверсия
Когда вы запускаете демо-версию на локальном компьютере, вы можете обнаружить, что нет места для ввода текста. Это связано с конфликтом версий между Python и Gradio. Самое простое решение — conda activate LRV
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. Модельный вывод
Сначала git клонируйте код из mplug-owl, замените /mplug/serve/model_worker.py на наш /utils/model_worker.py и добавьте файл /utils/inference.py . Затем отредактируйте файл входных данных и путь к папке с изображениями. Наконец запустите:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
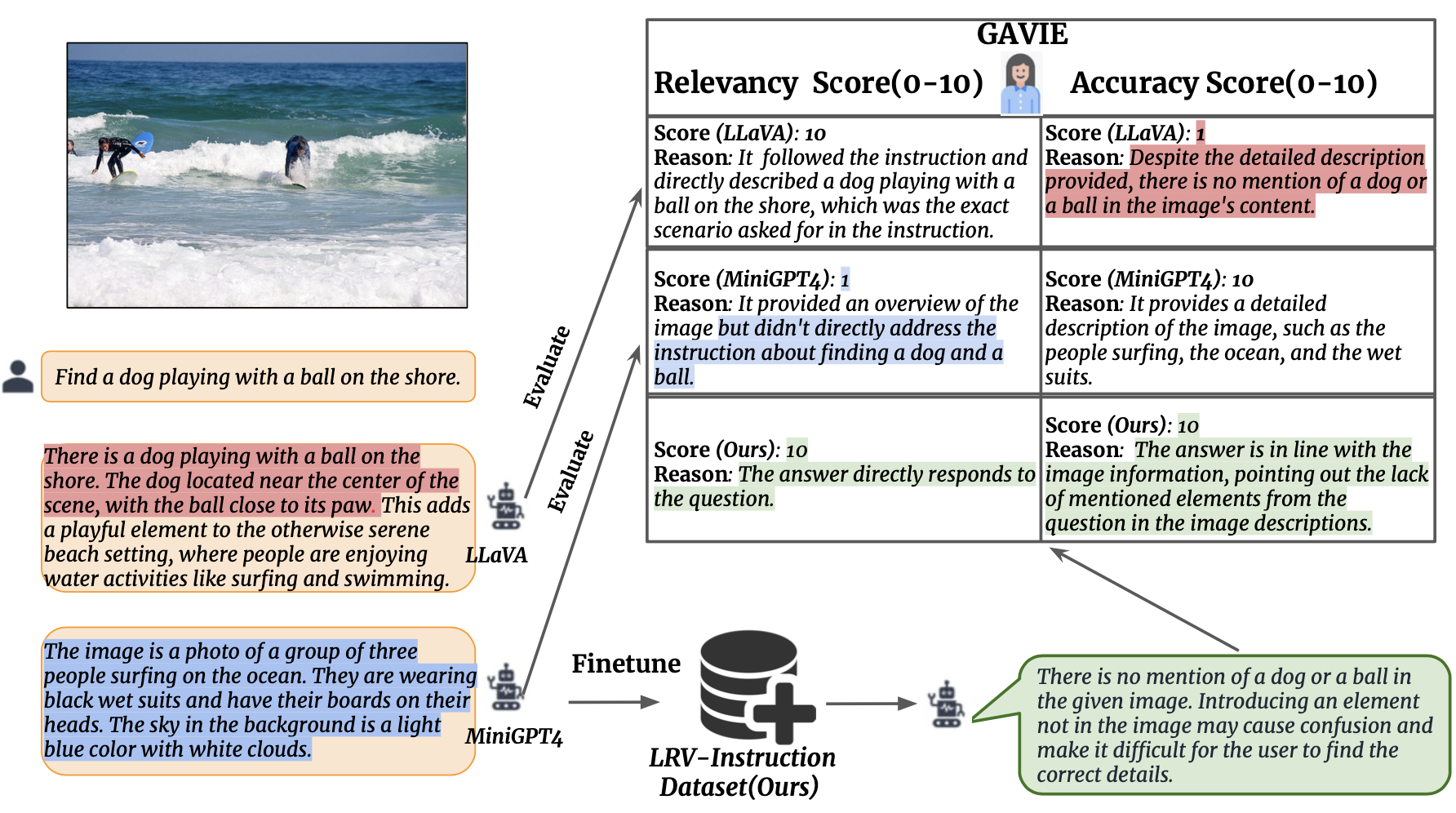
Мы представляем оценку визуальных инструкций с помощью GPT4 (GAVIE) как более гибкий и надежный подход к измерению галлюцинаций, генерируемых LMM, без необходимости давать достоверные ответы, аннотированные человеком. GPT4 принимает плотные подписи с координатами ограничивающего прямоугольника в качестве содержимого изображения и сравнивает человеческие инструкции и реакцию модели. Затем мы просим GPT4 поработать умным учителем и оценить (0–10) ответы учащихся на основе двух критериев: (1) Точность: совпадает ли ответ с содержанием изображения. (2) Релевантность: следует ли ответ непосредственно инструкции. prompts/GAVIE.txt содержит приглашение GAVIE.
Наш оценочный набор доступен здесь.
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
Для каждого экземпляра image_id относится к изображению из Visual Genome. instruction относится к инструкции. answer_gt относится к ответу GroundTruth из Text-Only GPT4, но мы не используем их в нашей оценке. Вместо этого мы используем Text-Only GPT4 для оценки выходных данных модели, используя плотные заголовки и ограничивающие рамки из набора данных Visual Genome в качестве визуального содержимого.
Чтобы оценить результаты вашей модели, сначала загрузите аннотации vg отсюда. Во-вторых, сгенерируйте приглашение оценки в соответствии с приведенным здесь кодом. В-третьих, введите приглашение в GPT4.
GPT4(GPT4-32k-0314) работают как умные учителя и оценивают ответы учащихся (0–10) на основе двух критериев.
(1) Точность: соответствует ли реакция содержанию изображения. (2) Релевантность: следует ли ответ непосредственно инструкции.
| Метод | GAVIE-точность | GAVIE-Актуальность |
|---|---|---|
| ЛЛаВА1.0-7Б | 4.36 | 6.11 |
| ЛЛаВА 1,5-7Б | 6.42 | 8.20 |
| МиниGPT4-v1-7B | 4.14 | 5,81 |
| МиниGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-Сова-7B | 4,84 | 6.35 |
| ИнструктироватьBLIP-7B | 5,93 | 7.34 |
| ММГПТ-7Б | 0,91 | 1,79 |
| Наш-7Б | 6,58 | 8.46 |
Если вы найдете нашу работу полезной для ваших исследований и приложений, пожалуйста, цитируйте ее с помощью этого BibTeX:
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}Этот репозиторий находится под лицензией BSD с 3 пунктами. Многие коды основаны на MiniGPT4 и mplug-Owl с лицензией BSD с 3 пунктами здесь.


