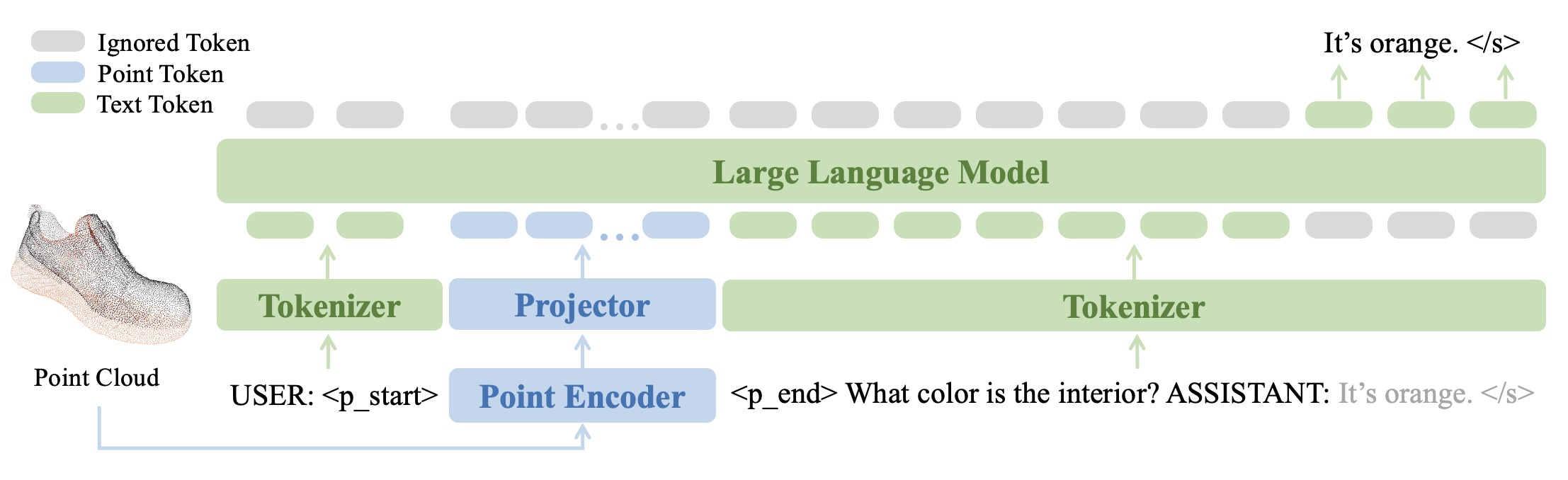
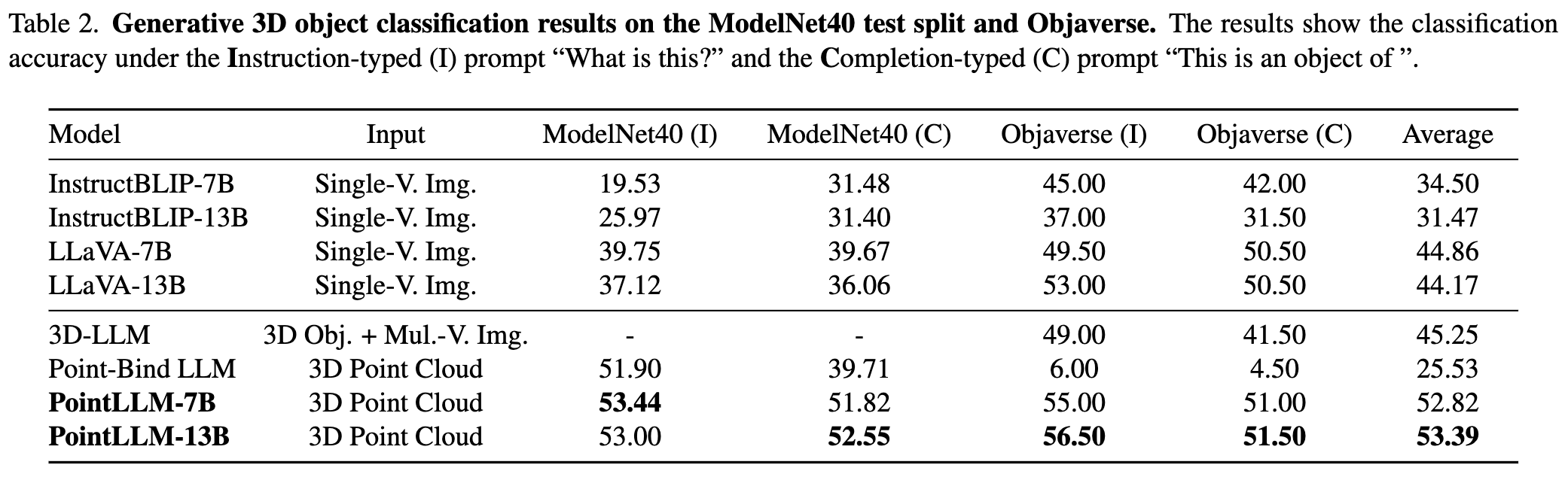
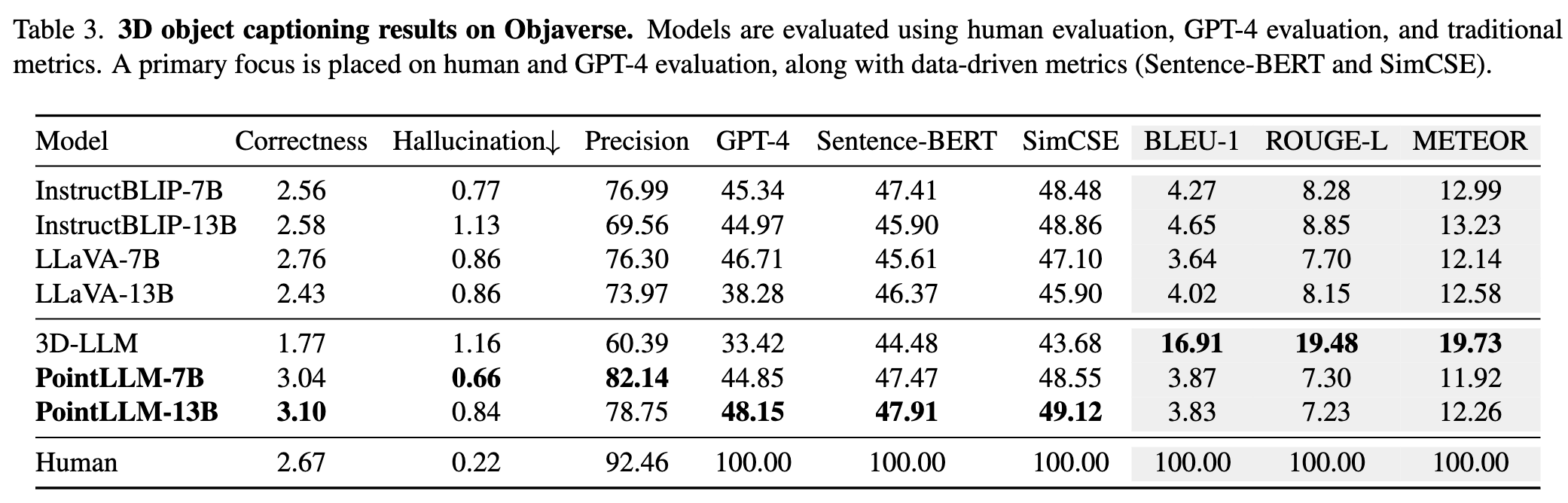
PointLLM
1.0.0
 PointLLM: расширение возможностей больших языковых моделей для понимания облаков точек
PointLLM: расширение возможностей больших языковых моделей для понимания облаков точек Рунсэн Сюй Сяолун Ван Тай Ван Илунь Чен Цзянмяо Пан* Дахуа Линь
Китайский университет Гонконга, Шанхайская лаборатория искусственного интеллекта, Чжэцзянский университет

PointLLM онлайн! Попробуйте это сделать по адресу http://101.230.144.196 или OpenXLab/PointLLM.
Вы можете поговорить с PointLLM о моделях набора данных Objaverse или о ваших собственных облаках точек!
Пожалуйста, не стесняйтесь сообщать нам, если у вас есть какие-либо отзывы! ?
| Диалог 1 | Диалог 2 | Диалог 3 | Диалог 4 |
|---|---|---|---|
 |  |  |  |
Пожалуйста, обратитесь к нашей статье для получения дополнительных результатов.
Пожалуйста, обратитесь к нашей статье для получения дополнительных результатов.

Мы тестируем наши коды в следующих условиях:
Для начала:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy , содержащая 660 тыс. файлов облаков точек с именем {Objaverse_ID}_8192.npy . Каждый файл представляет собой массив numpy с размерами (8192, 6), где первые три измерения — это xyz , а последние три измерения — rgb в диапазоне [0, 1]. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM создайте папку data и создайте мягкую ссылку на несжатый файл в каталоге. cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data создайте каталог с именем anno_data .anno_data . Каталог должен выглядеть так: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json фильтруется из PointLLM_brief_description_660K.json путем удаления 3000 объектов, которые мы зарезервировали в качестве набора проверки. Если вы хотите воспроизвести результаты из нашей статьи, вам следует использовать для обучения PointLLM_brief_description_660K_filtered.json . PointLLM_complex_instruction_70K.json содержит объекты из обучающего набора.pointllm/data/data_generation/system_prompt_gpt4_0613.txt . PointLLM_brief_description_val_200_GT.json которую мы используем для тестов набора данных Objaverse, и поместите его в PointLLM/data/anno_data . Мы также предоставляем здесь идентификаторы 3000 объектов, которые мы фильтруем во время обучения, и соответствующие им ссылки на GT здесь, которые можно использовать для оценки всех 3000 объектов.modelnet40_data в PointLLM/data . Загрузите тестовое разделение облаков точек ModelNet40 modelnet40_test_8192pts_fps.dat здесь и поместите его в PointLLM/data/modelnet40_data .PointLLM создайте каталог с именем checkpoints .checkpoints . cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.shОбычно вам не нужно беспокоиться о следующем содержимом. Они предназначены только для воспроизведения результатов из нашей статьи версии 1 (PointLLM-v1.1). Если вы хотите сравнить с нашими моделями или использовать наши модели для последующих задач, используйте PointLLM-v1.2 (см. наш документ по версии 2), который имеет более высокую производительность.
В PointLLM v1.1 и v1.2 используются немного разные предварительно обученные точечные кодеры и проекторы. Если вы хотите воспроизвести PointLLM v1.1, отредактируйте файл config.json в каталоге начальных весов LLM и кодировщика точек, например, vim checkpoints/PointLLM_7B_v1.1_init/config.json .
Измените ключ "point_backbone_config_name" , чтобы указать другую конфигурацию кодировщика точки:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 Отредактируйте путь контрольной точки кодера точки в scripts/train_stage1.sh :
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32 для обсуждения 3D-моделей Objaverse. Контрольные точки модели будут загружены автоматически. Вы также можете вручную загрузить контрольные точки модели и указать пути к ним. Вот пример: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32 Вы также можете легко изменить коды для использования облаков точек, отличных от Objaverse, при условии, что облака точек, входные в модель, имеют размеры (N, 6), где первые три измерения — xyz , а последние три измерения — rgb ( в диапазоне [0, 1]). Вы можете выбрать облака точек, чтобы получить 8192 точки, поскольку наша модель обучена на таких облаках точек.
В следующей таблице показаны требования к графическому процессору для различных моделей и типов данных. Мы рекомендуем использовать torch.bfloat16 , если это применимо, который используется в экспериментах в нашей статье.
| Модель | Тип данных | Память графического процессора |
|---|---|---|
| ТочкаLLM-7B | факел.float16 | 14 ГБ |
| ТочкаLLM-7B | факел.float32 | 28 ГБ |
| ТочкаLLM-13B | факел.float16 | 26 ГБ |
| ТочкаLLM-13B | факел.float32 | 52 ГБ |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation как словарь следующего формата: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C . Это позволит сохранить временные результаты. Если во время оценки произойдет ошибка, скрипт также сохранит текущее состояние. Вы можете возобновить оценку с того места, где она была остановлена, снова выполнив ту же команду.{model_name}/evaluation как еще один словарь. Некоторые из показателей объясняются следующим образом: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval и указав --gpt_type . Например: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_outputВклад сообщества приветствуется!? Если вам нужна поддержка, пожалуйста, не стесняйтесь открыть вопрос или свяжитесь с нами.
Если вы найдете нашу работу и эту кодовую базу полезными, рассмотрите возможность добавления этого репозитория в качестве звездочки. и цитируем:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
Эта работа находится под международной лицензией Creative Commons Attribution-NonCommercial-ShareAlike 4.0.
Давайте вместе сделаем LLM для 3D великолепным!


