thumb
1.0.0
Простая библиотека быстрого тестирования для студентов LLM.
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])По умолчанию каждое приглашение запускается 10 раз асинхронно, что примерно в 9 раз быстрее, чем их последовательное выполнение. В Jupyter Notebooks отображается простой пользовательский интерфейс для ответов на слепые оценки (вы не видите, какое приглашение сгенерировало ответ).
После того как все ответы будут оценены, рассчитывается следующая статистика производительности с разбивкой по шаблонам приглашений:
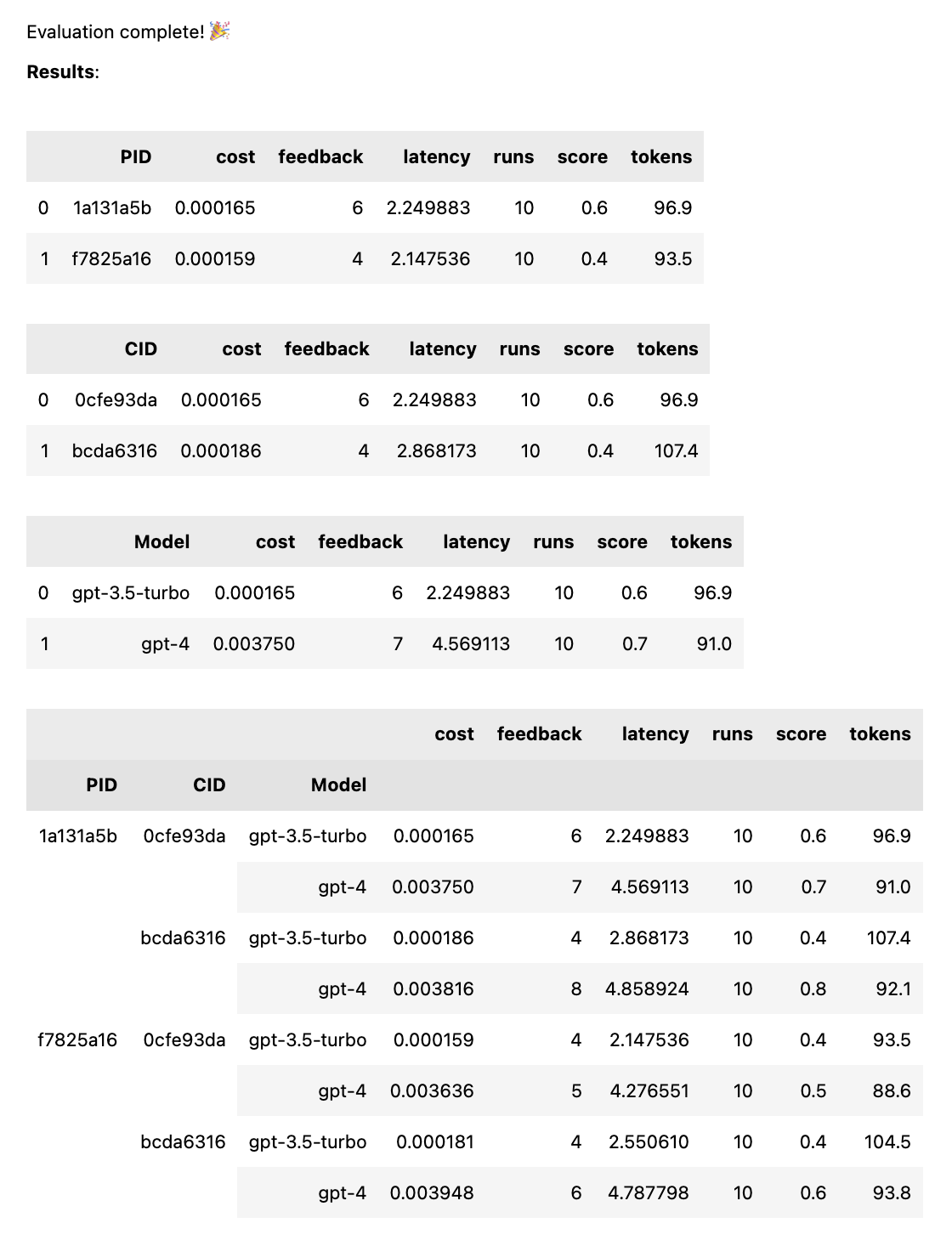
avg_score количество положительных отзывов в процентах от всех запусковavg_tokens : сколько токенов было использовано в приглашении и ответе.avg_cost : оценка средней стоимости запуска запроса. В блокноте отображается простой отчет, а полные данные сохраняются в CSV-файле thumb/ThumbTest-{TestID}.csv .

Тестовые случаи – это случаи, когда вы хотите протестировать шаблон приглашения с различными входными переменными. Например, если вы хотите протестировать шаблон приглашения, включающий переменную для имени комика, вы можете настроить тестовые сценарии для разных комиков.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Каждый тестовый пример будет выполняться для каждого шаблона приглашения, поэтому в этом примере вы получите 6 комбинаций (3 тестовых примера x 2 шаблона приглашения), каждая из которых будет выполняться 10 раз (всего 60 вызовов OpenAI). Каждый тестовый пример должен включать значение для каждой переменной в шаблоне приглашения.
В каждом тестовом примере подсказки могут иметь несколько переменных. Например, если вы хотите протестировать шаблон приглашения, включающий переменную для имени комика и темы шутки, вы можете настроить тестовые примеры для разных комиков и тем.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Каждый случай тестируется по каждому приглашению, чтобы получить справедливое сравнение производительности каждого приглашения при одних и тех же входных данных. С 4 тестовыми примерами и 2 приглашениями вы получите 8 комбинаций (4 тестовых примера x 2 шаблона приглашений), каждая из которых будет запускаться 10 раз (всего 80 вызовов OpenAI).
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])При этом каждое приглашение будет запускаться для каждой модели, чтобы получить объективное сравнение производительности каждого приглашения при одних и тех же входных данных. С 2 приглашениями и 2 моделями вы получите 4 комбинации (2 приглашения x 2 модели), каждая из которых будет запускаться 10 раз (всего 40 вызовов OpenAI).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) Подсказки могут быть строкой или массивом строк. Если приглашение представляет собой массив, первая строка используется как системное сообщение, а остальные приглашения чередуются между сообщениями Human и Assistant ( [system, human, ai, human, ai, ...] ). Это полезно для тестирования подсказок, которые включают системное сообщение или используют предварительный разогрев (вставка предыдущих сообщений в чат, чтобы направить ИИ к желаемому поведению).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )По завершении теста вы получите полный отчет об оценке с разбивкой по PID, CID и модели, а также общий отчет с разбивкой по всем комбинациям. Если вы тестируете только одну модель или один корпус, эти поломки отпадут. В отчете внизу отображается ключ, позволяющий увидеть, какой идентификатор соответствует какому приглашению или случаю.
Функция thumb.test принимает следующие параметры:
None )10 ).gpt-3.5-turbo ])True ) Если у вас есть 10 тестовых запусков с 2 шаблонами подсказок и 3 тестовыми примерами, это 10 x 2 x 3 = 60 вызовов OpenAI. Будьте осторожны: особенно в случае GPT-4, затраты могут быстро возрасти!
Трассировка Langchain в LangSmith автоматически включается, если LANGCHAIN_API_KEY установлен как переменная среды (необязательно).
функция .test() возвращает объект ThumbTest . Вы можете добавить в тест дополнительные запросы или случаи или запустить его несколько раз. Вы также можете в любое время генерировать, оценивать и экспортировать тестовые данные.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Каждый шаблон приглашения получает одни и те же входные данные из каждого тестового примера, но приглашение не обязательно должно использовать все переменные в тестовом примере. Как и в приведенном выше примере, подсказка tell me a knock knock joke не использует переменную subject , но она все равно генерируется один раз (без переменных) для каждого тестового примера.
Тестовые данные кэшируются в локальном файле JSON thumb/.cache/{TestID}.json после создания каждого набора запусков для комбинации приглашения и регистра. Если ваш тест прерван или вы хотите что-то добавить, вы можете использовать функцию thumb.load для загрузки тестовых данных из кэша.
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Каждый запуск для каждой комбинации приглашения и случая сохраняется в объекте (и в кеше), и поэтому повторный вызов test.generate() не будет генерировать новые ответы, если не будут добавлены дополнительные запросы, случаи или запуски. Аналогичным образом, повторный вызов test.evaluate() не приведет к повторной оценке ответов, которые вы уже оценили, а просто повторно отобразит результаты, если тест завершился.
Разница между людьми, которые просто играют с ChatGPT, и теми, кто использует ИИ в производстве, заключается в оценке. LLM реагируют недетерминированно, поэтому важно проверить, как выглядят результаты при масштабировании в широком диапазоне сценариев. Без системы оценки вам придется слепо гадать о том, что работает в ваших подсказках (или нет).
Серьезные оперативные инженеры надежно и в большом масштабе тестируют и изучают, какие входные данные приводят к полезным или желаемым результатам. Этот процесс называется оперативной оптимизацией и выглядит он следующим образом:
Тестирование «на пальцах» заполняет пробел между крупномасштабными механизмами профессиональной оценки и слепыми подсказками методом проб и ошибок. Если вы переносите приглашение в рабочую среду, использование thumb для проверки приглашения может помочь вам выявить крайние случаи и получить ранние отзывы пользователей или команды о результатах.
Эти люди строят thumb ради развлечения в свободное время. ?
Хаммер-МТ |


