Q Bench
1.0.0
Как мультимодальные LLM работают с низкоуровневым компьютерным зрением?
Хаонин Ву 1 * , Цзычэн Чжан 2 * , Эрли Чжан 1 * , Чаофэн Чен 1 , Лян Ляо 1 ,
Аннань Ван 1 , Чуньи Ли 2 , Вэньсю Сунь 3 , Цюн Янь 3 , Гуантао Чжай 2 , Вэйси Линь 1 #
1 Наньянский технологический университет, 2 Шанхайский университет Цзяотун, 3 Исследовательский институт Sensetime
* Равный вклад. # Автор переписки.
ICLR2024 В центре внимания
Бумага | Страница проекта | Гитхаб | Данные (LLVisionQA) | Данные (LLDescribe) |质衡 (Китайский-Q-Bench)


Предлагаемый Q-Bench включает три области зрения низкого уровня: восприятие (A1), описание (A2) и оценку (A3).
Для восприятия (A1)/описания (A2) мы собираем два эталонных набора данных LLVisionQA/LLDescribe.
Мы открыты для оценки этих двух задач на основе представленных материалов . Подробности подачи следующие.
Для оценки (A3), поскольку мы используем общедоступные наборы данных , мы предоставляем абстрактный код оценки для произвольных MLLM, который может протестировать каждый.
datasets Для Q-Bench-A1 (с вопросами с несколькими вариантами ответов) мы преобразовали их в наборы данных в формате HF, которые можно автоматически загружать и использовать с API datasets . Пожалуйста, обратитесь к следующей инструкции:
наборы данных установки pip
из наборов данных import load_datasetds = load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,### 'question': 'Как это освещение здание?',### 'option0': 'Высокий',### 'option1': 'Низкий',### 'option2': 'Средний',### 'option3': 'Н/Д', ### 'question_type': 2,### 'question_concern': 3,### 'correct_choice': 'B'} из наборов данных import load_datasetds = load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image image mode=размер RGB=4032x3024>,### 'image2': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=864x1152>,### 'question': 'Какова четкость второго изображения по сравнению с первым изображением?',### 'option0': 'Более размытым',### 'option1 ': 'Четче',### 'option2': 'Примерно то же самое',### 'option3': 'N/A',### 'question_type': 2,### 'question_concern': 0,### 'correct_choice': 'B'}[2024/8/8] Часть задачи низкоуровневого сравнения зрения в Q-bench+ (также называемая Q-Bench2) только что была принята TPAMI! Приходите и протестируйте свой MLLM с помощью Q-bench+_Dataset.
[2024/8/1] Q-Bench выпущен на VLMEvalKit, приходите и протестируйте свой LMM с помощью одной команды, например `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'.
[2024/6/17] Q-Bench , Q-Bench2 (Q-bench+) и A-Bench теперь присоединились к lmms-eval, что упрощает тестирование LMM !!
[2024/6/3] Репозиторий A-Bench на Github доступен онлайн. Хотите узнать, является ли ваш LMM мастером оценки изображений, созданных ИИ? Приходите и протестируйте на A-Bench !!
[3/1] Мы выпускаем Co-instruct « На пути к открытому визуальному сравнению качества» здесь. Более подробная информация появится в ближайшее время.
[2/27] Наша работа Q-Insturct была принята CVPR 2024. Попробуйте узнать подробности о том, как инструктировать MLLM по низкоуровневому зрению!
[2/23] Часть Q-bench+ для низкоуровневого сравнения изображений теперь доступна в Q-bench+(Dataset)!
[2/10] Мы выпускаем расширенный тест Q-bench+, который бросает вызов MLLM как с отдельными изображениями, так и с парами изображений при низком уровне зрения. Таблица лидеров находится на месте, проверьте способность ваших любимых MLLM к низкоуровневому зрению! Более подробная информация скоро появится.
[1/16] Наша работа «Q-Bench: эталон для базовых моделей общего назначения для низкоуровневого зрения» принята ICLR2024 в качестве презентации .

Мы тестируем три модели API с закрытым исходным кодом: GPT-4V-Turbo ( gpt-4-vision-preview , замена более недоступной старой версии результатов GPT-4V), Gemini Pro ( gemini-pro-vision ) и Qwen. -ВЛ-Плюс ( qwen-vl-plus ). Немного улучшенный по сравнению со старой версией, GPT-4V по-прежнему лидирует среди всех MLLM и по производительности почти соответствует человеческому уровню младшего уровня. Gemini Pro и Qwen-VL-Plus следуют за ними, но все же лучше, чем лучшие MLLM с открытым исходным кодом (общий показатель 0,65).
Обновление от [2024/7/18]. Мы рады представить новую версию SOTA BlueImage-GPT (с закрытым исходным кодом).
Восприятие, А1-Одиночный
| Имя участника | Да или нет | что | как | искажение | другие | искажение контекста | в контексте другие | общий |
|---|---|---|---|---|---|---|---|---|
Квен-ВЛ-Плюс ( qwen-vl-plus ) | 0,7574 | 0,7325 | 0,5733 | 0,6488 | 0,7324 | 0,6867 | 0,7056 | 0,6893 |
BlueImage-GPT ( from VIVO New Champion ) | 0,8467 | 0,8351 | 0,7469 | 0,7819 | 0,8594 | 0,7995 | 0,8240 | 0,8107 |
Близнецы-Про ( gemini-pro-vision ) | 0,7221 | 0,7300 | 0,6645 | 0,6530 | 0,7291 | 0,7082 | 0,7665 | 0,7058 |
GPT-4V-Турбо ( gpt-4-vision-preview ) | 0,7722 | 0,7839 | 0,6645 | 0,7101 | 0,7107 | 0,7936 | 0,7891 | 0,7410 |
| ГПТ-4В ( старая версия ) | 0,7792 | 0,7918 | 0,6268 | 0,7058 | 0,7303 | 0,7466 | 0,7795 | 0,7336 |
| человек-1-младший | 0,8248 | 0,7939 | 0,6029 | 0,7562 | 0,7208 | 0,7637 | 0,7300 | 0,7431 |
| человек-2-старший | 0,8431 | 0,8894 | 0,7202 | 0,7965 | 0,7947 | 0,8390 | 0,8707 | 0,8174 |
Восприятие, пара А1
| Имя участника | Да или нет | что | как | искажение | другие | сравнивать | соединение | общий |
|---|---|---|---|---|---|---|---|---|
Квен-ВЛ-Плюс ( qwen-vl-plus ) | 0,6685 | 0,5579 | 0,5991 | 0,6246 | 0,5877 | 0,6217 | 0,5920 | 0,6148 |
Квен-ВЛ-Макс ( qwen-vl-max ) | 0,6765 | 0,6756 | 0,6535 | 0,6909 | 0,6118 | 0,6865 | 0,6129 | 0,6699 |
BlueImage-GPT ( from VIVO New Champion ) | 0,8843 | 0,8033 | 0,7958 | 0,8464 | 0,8062 | 0,8462 | 0,7955 | 0,8348 |
Близнецы-Про ( gemini-pro-vision ) | 0,6578 | 0,5661 | 0,5674 | 0,6042 | 0,6055 | 0,6046 | 0,6044 | 0,6046 |
ГПТ-4В ( gpt-4-vision ) | 0,7975 | 0,6949 | 0,8442 | 0,7732 | 0,7993 | 0,8100 | 0,6800 | 0,7807 |
| Человек младшего уровня | 0,7811 | 0,7704 | 0,8233 | 0,7817 | 0,7722 | 0,8026 | 0,7639 | 0,8012 |
| Человек старшего уровня | 0,8300 | 0,8481 | 0,8985 | 0,8313 | 0,9078 | 0,8655 | 0,8225 | 0,8548 |
Недавно мы также оценили несколько новых моделей с открытым исходным кодом и скоро опубликуем их результаты.
Теперь мы предоставляем два способа загрузки наборов данных (LLVisionQA&LLDescribe).
через GitHub Релиз: подробности смотрите в нашем релизе.
через наборы данных Huggingface: Чтобы загрузить изображения, обратитесь к примечаниям к выпуску данных.
Настоятельно рекомендуется преобразовать вашу модель в формат Huggingface, чтобы беспрепятственно протестировать эти данные. Посмотрите примеры сценариев для IDEFICS-9B-Instruct от Huggingface и измените их для своей пользовательской модели для тестирования на ней.
Отправьте электронное письмо по адресу [email protected] чтобы отправить результат в формате json.
Вы также можете отправить нам свою модель (это может быть Huggingface AutoModel или ModelScope AutoModel) вместе со своими собственными сценариями оценки. Ваши пользовательские сценарии можно изменить из шаблонных сценариев, которые работают для LLaVA-v1.5 (для A1/A2), и здесь (для оценки качества изображения).
Если вы находитесь за пределами материкового Китая, отправьте электронное письмо по адресу [email protected] чтобы отправить свою модель. Если вы находитесь на территории материкового Китая, отправьте электронное письмо по адресу [email protected] , чтобы отправить свою модель.
Снимок набора эталонных данных LLVisionQA для способности восприятия низкого уровня MLLM выглядит следующим образом. Посмотреть таблицу лидеров можно здесь.
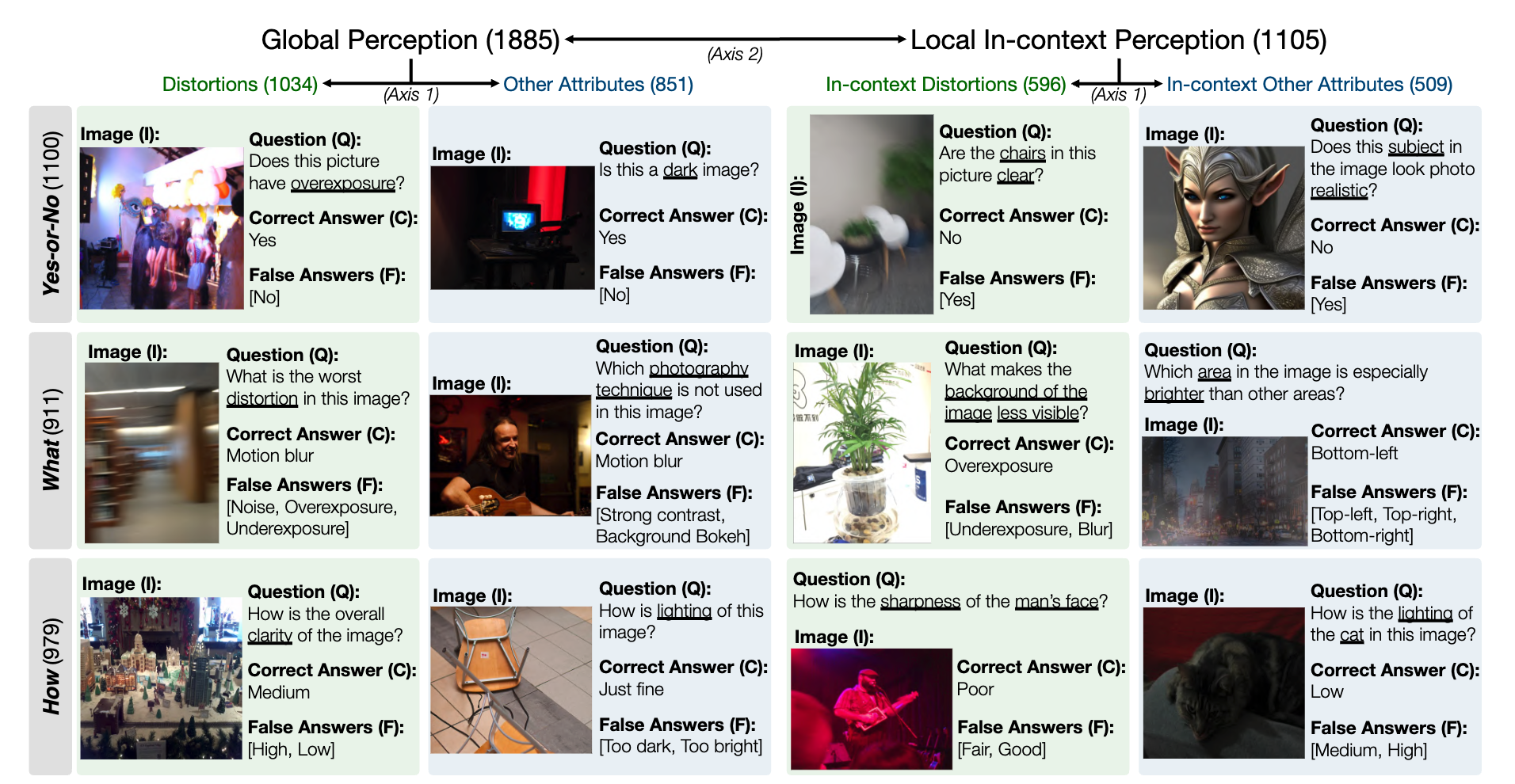
В качестве показателя здесь мы измеряем точность ответов MLLM (предоставляемых вместе с вопросом и всеми вариантами ответов).
Снимок эталонного набора данных LLDescribe для возможности низкоуровневого описания MLLM выглядит следующим образом. Посмотреть таблицу лидеров можно здесь.

В качестве показателя здесь мы измеряем полноту , точность и релевантность описаний MLLM.
Замечательная способность MLLM предсказывать количественные показатели IQA!
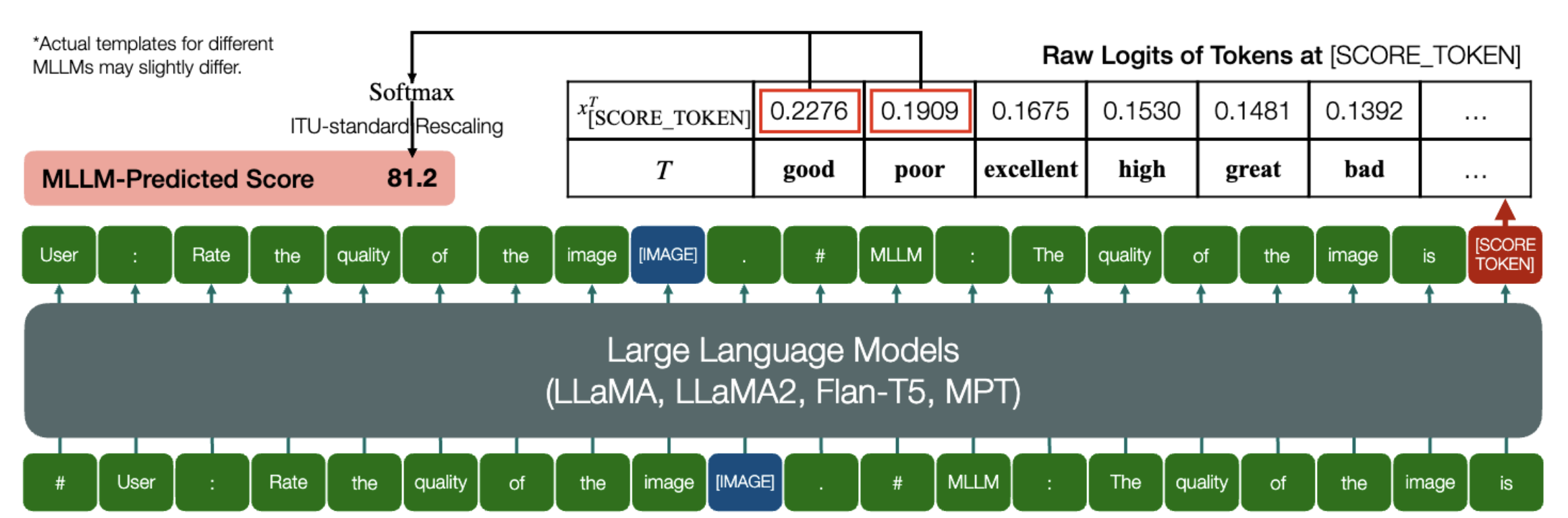
Аналогично вышеизложенному, пока модель (основанная на моделях причинного языка) имеет следующие два метода: embed_image_and_text (для обеспечения мультимодальных входных данных) и forward (для вычисления логитов), оценка качества изображения (IQA) с моделью может быть достигнуто следующим образом:
из PIL import Imagefrom my_mllm_model import Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##User: Оцените качество изображения.n"
"##Ассистент: Качество изображения" ### Эту строку можно изменить в зависимости от поведения MLLM по умолчанию.good_idx, bad_idx = tokenizer(["хорошо","плохо"]).tolist()image = Image. open("image_for_iqa.jpg")input_embeds = embed_image_and_text(изображение, подсказка)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, bad_idx]] / 100).softmax(0)[0]*Обратите внимание, что вы можете изменить вторую строку в соответствии с форматом вашей модели по умолчанию, например , для Shikra «##Ассистент: Качество изображения» изменяется на «##Ассистент: Ответ есть». Ничего страшного, если ваш MLLM сначала ответит: «Хорошо, я хотел бы помочь! Качество изображения хорошее», просто замените это во второй строке приглашения.
Далее мы обеспечиваем полную реализацию IDEFICS на IQA. См. пример того, как запустить IQA с помощью этого MLLM. Другие MLLM также могут быть изменены таким же образом для использования в IQA.
Мы подготовили оценки общественного мнения (MOS) в формате JSON для семи баз данных IQA, как оценивалось в нашем тесте.
Подробную информацию см. в IQA_databases.
Перенесено в списки лидеров. Пожалуйста, нажмите, чтобы увидеть подробности.
Пожалуйста, свяжитесь с любым из первых авторов этой статьи с вопросами.
Хаонин Ву, [email protected] , @teowu
Цзычэн Чжан, [email protected] , @zzc-1998
Эрли Чжан, [email protected] , @ZhangErliCarl
Если наша работа покажется вам интересной, пожалуйста, цитируйте нашу статью:
@inproceedings{wu2024qbench,author = {У, Хаонин и Чжан, Цзычэн и Чжан, Эрли и Чен, Чаофэн и Ляо, Лян и Ван, Аннан и Ли, Чуньи и Сунь, Вэньсю и Янь, Цюн и Чжай, Гуантао и Линь, Weisi},title = {Q-Bench: эталонный тест для моделей фундамента общего назначения на Низкоуровневое видение},booktitle = {ICLR},year = {2024}} 

