LLM PuzzleTest
1.0.0
PuzzleVQA, наш новый набор данных раскрывает серьезные проблемы мультимодальных LLM в понимании простых абстрактных закономерностей. Бумага | Веб-сайт
Мы выпускаем AlgoPuzzleVQA, новый и сложный набор данных для мультимодальных рассуждений! Вскоре мы выпустим больше наборов данных мультимодальных головоломок. Следите за обновлениями! Бумага | Веб-сайт
Мы рады объявить о выпуске двух новых наборов данных VQA, посвященных головоломкам:
Производительность MLLM на обоих наборах данных явно недостаточна, что подчеркивает острую необходимость существенного улучшения их возможностей мультимодального рассуждения.
Большие мультимодальные модели расширяют впечатляющие возможности больших языковых моделей за счет интеграции возможностей мультимодального понимания. Однако неясно, как они могут имитировать общий интеллект и способность к рассуждению людей. Поскольку распознавание закономерностей и абстрагирование концепций являются ключом к общему интеллекту, мы представляем PuzzleVQA, коллекцию головоломок, основанных на абстрактных закономерностях. С помощью этого набора данных мы оцениваем большие мультимодальные модели с абстрактными шаблонами, основанными на фундаментальных понятиях, включая цвета, числа, размеры и формы. В ходе наших экспериментов с современными большими мультимодальными моделями мы обнаружили, что они не способны хорошо обобщаться на простые абстрактные шаблоны. Примечательно, что даже GPT-4V не может решить более половины головоломок. Чтобы диагностировать проблемы рассуждения в больших мультимодальных моделях, мы постепенно направляем модели с помощью наших основных истинных объяснений визуального восприятия, индуктивных рассуждений и дедуктивных рассуждений. Наш систематический анализ показывает, что основными узкими местами GPT-4V являются более слабое зрительное восприятие и способности к индуктивному рассуждению. Благодаря этой работе мы надеемся пролить свет на ограничения больших мультимодальных моделей и на то, как они могут лучше имитировать когнитивные процессы человека в будущем.
PuzzleVQA доступен здесь, а также на Huggingface.
На рисунке ниже показан пример вопроса, который включает в себя концепцию цвета в PuzzleVQA и неправильный ответ от GPT-4V. Обычно в процессе решения можно наблюдать три этапа: визуальное восприятие (синий), индуктивное рассуждение (зеленый) и дедуктивное рассуждение (красный). Здесь зрительное восприятие было неполным, что вызывало ошибку при дедуктивном рассуждении.

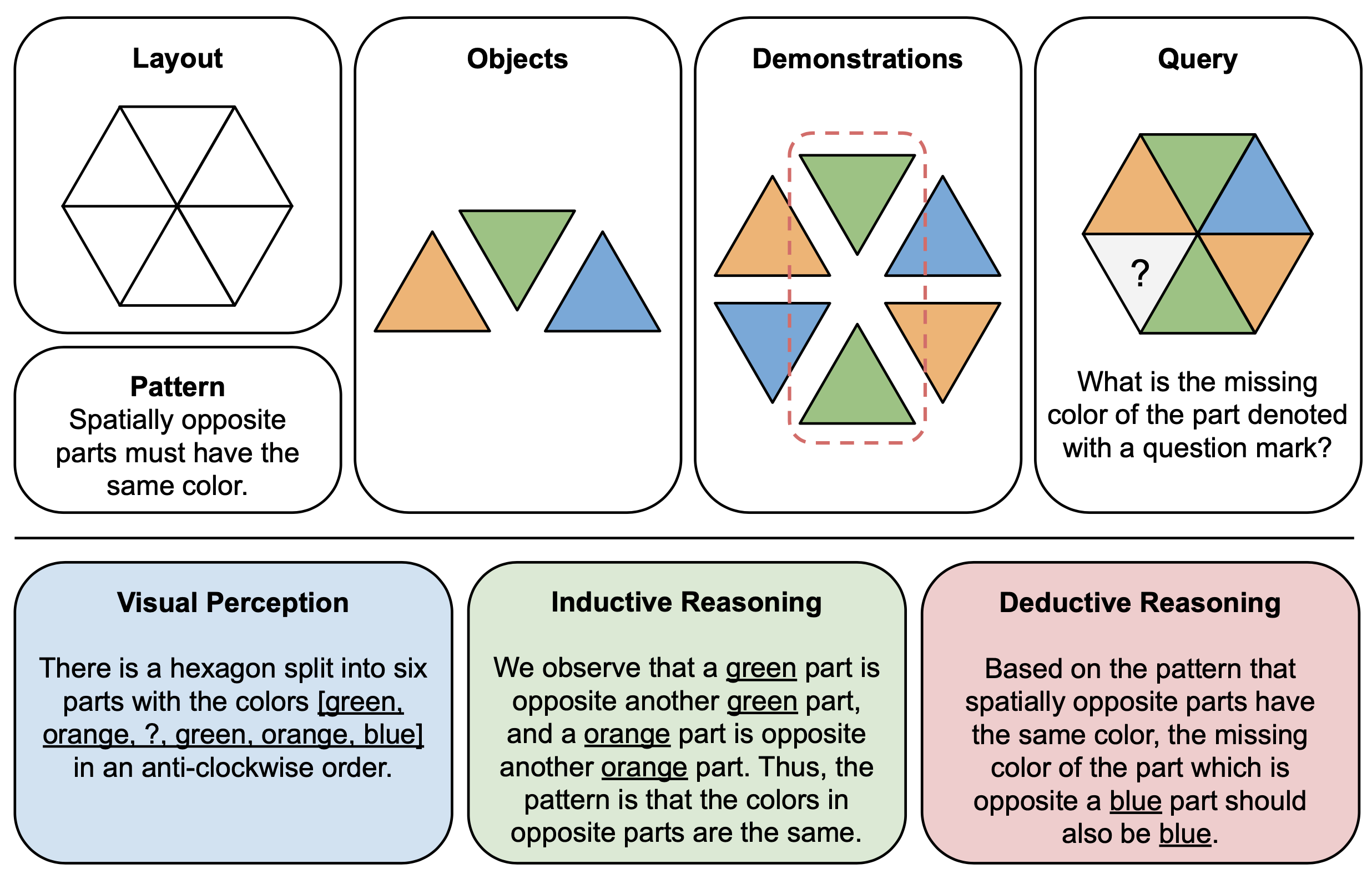
На рисунке ниже показан иллюстративный пример компонентов (вверху) и пояснений (внизу) для абстрактных головоломок в PuzzleVQA. Чтобы построить каждый экземпляр головоломки, мы сначала определяем макет и шаблон мультимодального шаблона и заполняем шаблон подходящими объектами, демонстрирующими базовый шаблон. Для интерпретируемости мы также создаем обоснованные объяснения, чтобы интерпретировать загадку и объяснять общие этапы решения.
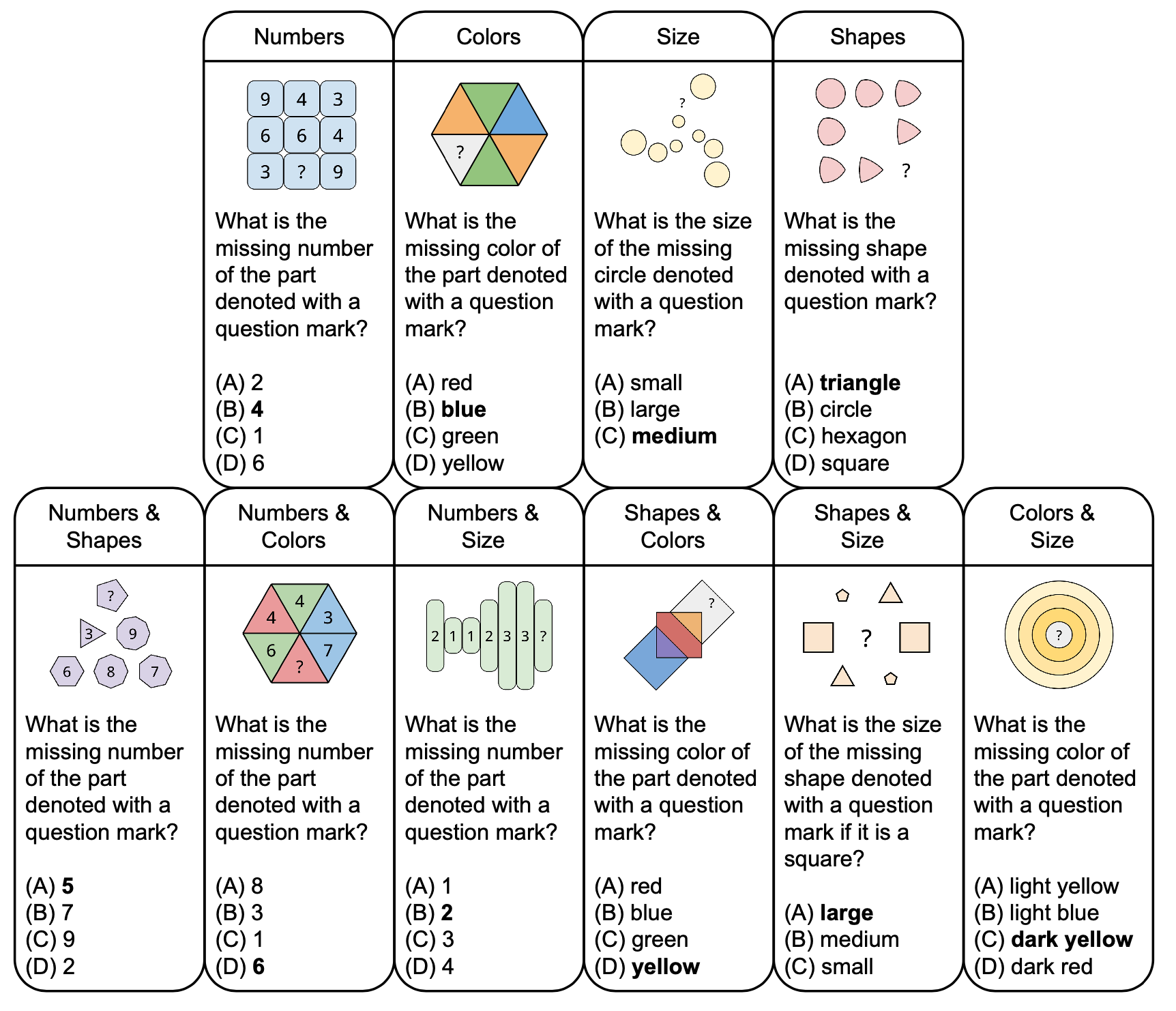
На рисунке ниже показана таксономия абстрактных головоломок в PuzzleVQA с примерами вопросов, основанных на фундаментальных понятиях, таких как цвета и размер. Чтобы увеличить разнообразие, мы разрабатываем головоломки как с одной, так и с двойной концепцией.
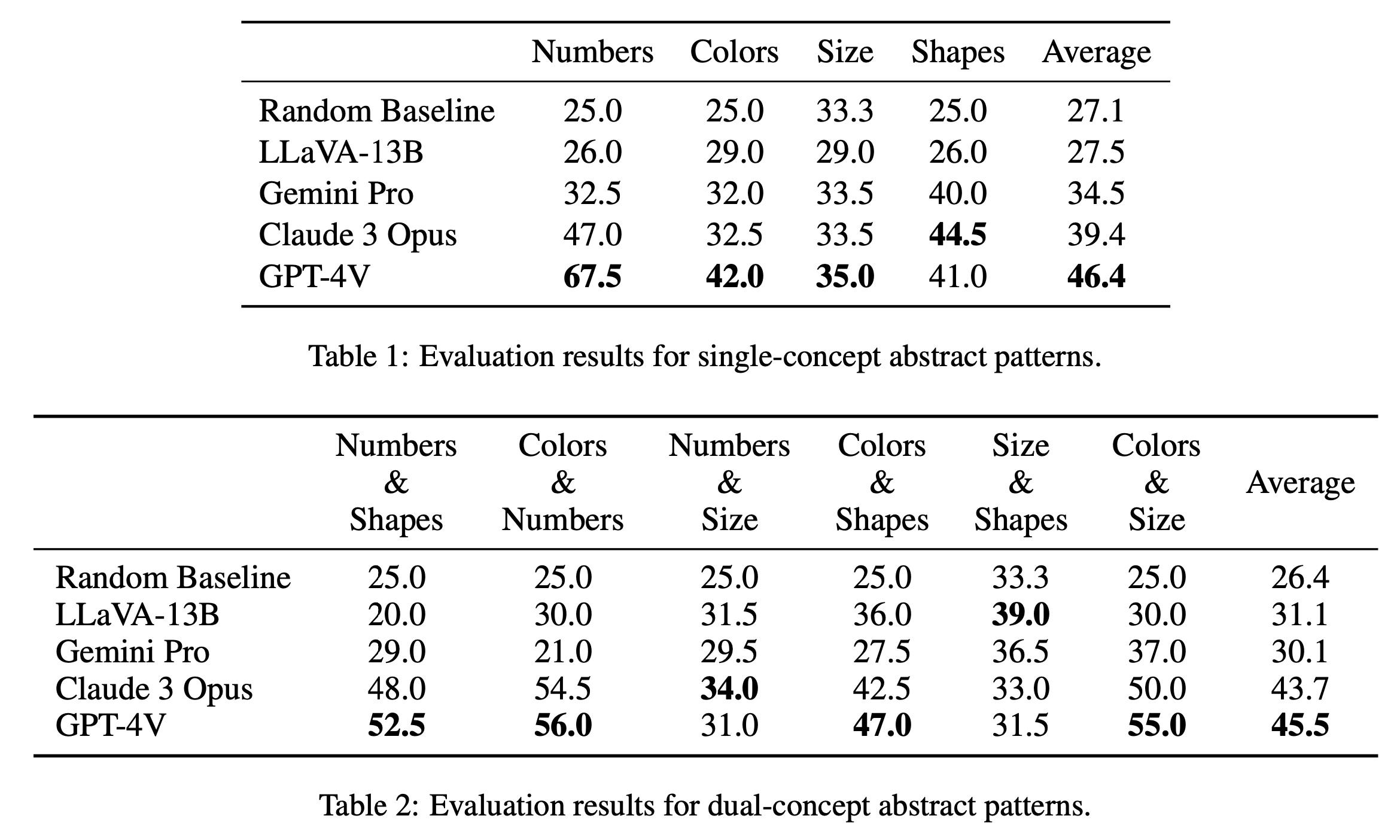
Мы сообщаем об основных результатах оценки головоломок с одной и двойной концепцией в Таблице 1 и Таблице 2 соответственно. Результаты оценки головоломок с одной концепцией, показанные в таблице 1, показывают заметные различия в производительности моделей с открытым и закрытым исходным кодом. GPT-4V выделяется наивысшим средним баллом 46,4, демонстрируя превосходное рассуждение по абстрактным шаблонам при решении головоломок с одним понятием, таких как числа, цвета и размер. Он особенно выделяется в категории «Числа» с результатом 67,5, значительно превосходя другие модели, что может быть связано с его преимуществом в математических задачах (Yang et al., 2023). Далее следует Claude 3 Opus с общим средним баллом 39,4, демонстрируя свою силу в категории «Формы» с высшим баллом 44,5. Остальные модели, в том числе Gemini Pro и LLaVA-13B, отстают со средними баллами 34,5 и 27,5 соответственно, демонстрируя аналогичные случайным базовым показателям в нескольких категориях.
В оценке головоломок с двойной концепцией, как показано в таблице 2, GPT-4V снова выделяется с самым высоким средним баллом 45,5. Особенно хорошие результаты он показал в таких категориях, как «Цвета и числа» и «Цвета и размер» с баллами 56,0 и 55,0 соответственно. Следом за ним следует Claude 3 Opus со средним баллом 43,7, демонстрируя высокие результаты в разделе «Числа и размер» с наивысшим баллом 34,0. Интересно, что LLaVA-13B, несмотря на более низкий общий средний балл (31,1), набирает самый высокий балл в категории «Размер и форма» — 39,0. Gemini Pro, с другой стороны, имеет более сбалансированную производительность по категориям, но с немного более низким общим средним показателем — 30,1. В целом мы обнаружили, что модели в среднем работают одинаково для шаблонов с одним и двумя понятиями, что предполагает, что они способны связывать вместе несколько понятий, таких как цвета и числа.
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Мы представляем новую задачу решения мультимодальных головоломок, сформулированную в контексте визуального ответа на вопросы. Мы представляем новый набор данных AlgoPuzzleVQA, предназначенный для проверки и оценки возможностей мультимодальных языковых моделей в решении алгоритмических головоломок, которые требуют как визуального понимания, понимания языка, так и сложных алгоритмических рассуждений. Мы создаем головоломки, охватывающие широкий спектр математических и алгоритмических тем, таких как булева логика, комбинаторика, теория графов, оптимизация, поиск и т. д., стремясь оценить разрыв между визуальной интерпретацией данных и навыками алгоритмического решения задач. Набор данных генерируется автоматически на основе кода, написанного людьми. Все наши головоломки имеют точные решения, которые можно найти с помощью алгоритма без утомительных человеческих вычислений. Это гарантирует, что наш набор данных можно масштабировать произвольно с точки зрения сложности рассуждений и размера набора данных. Наше исследование показывает, что большие языковые модели (LLM), такие как GPT4V и Gemini, демонстрируют ограниченную производительность при решении головоломок. Мы обнаружили, что их результаты почти случайны в системе вопросов и ответов с несколькими вариантами ответов для значительного количества головоломок. Результаты подчеркивают проблемы интеграции визуальных, языковых и алгоритмических знаний для решения сложных задач рассуждения.
PuzzleVQA доступен здесь, а также на Huggingface.
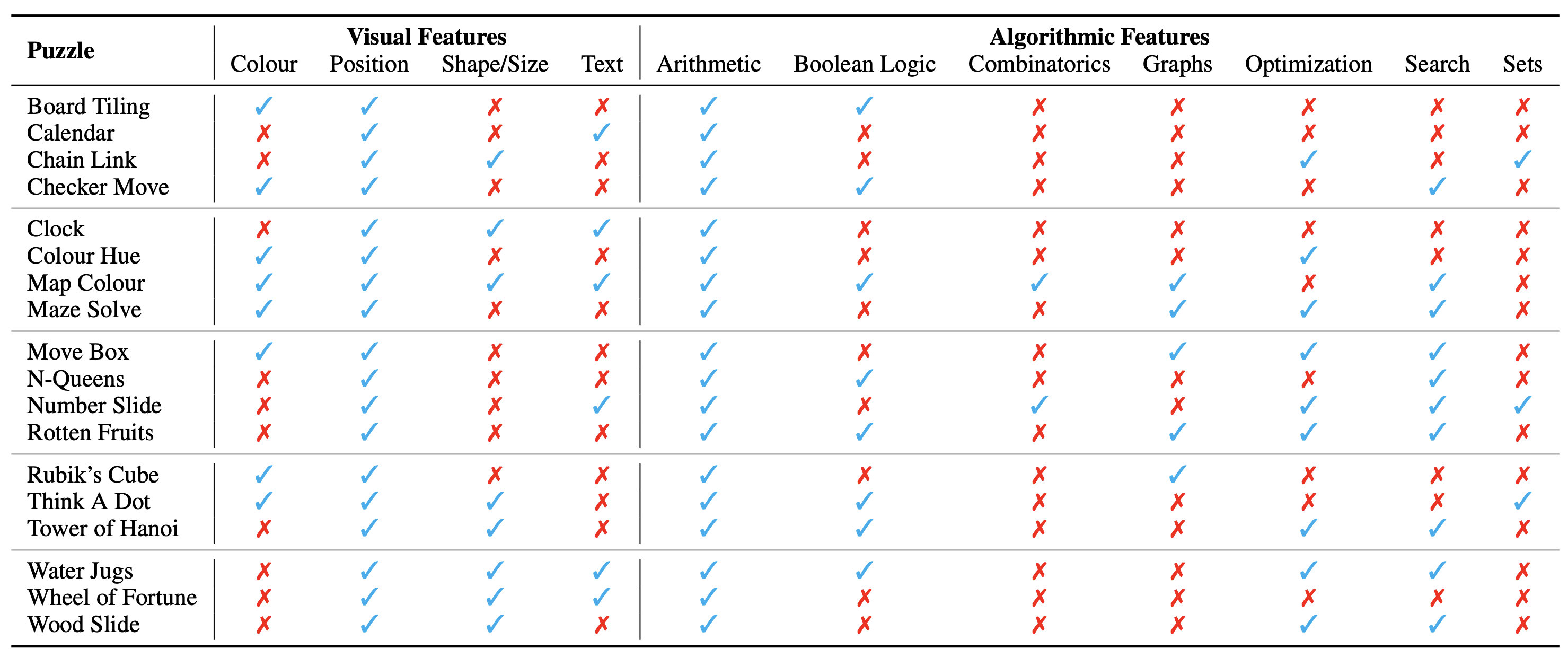
Конфигурация головоломки/проблемы отображается в виде изображения, которое составляет ее визуальный контекст. Мы выделяем следующие фундаментальные аспекты визуального контекста, влияющие на характер головоломок:

Мы также определяем алгоритмические концепции, необходимые для решения головоломок, т.е. для ответа на вопросы экземпляров головоломок. Они заключаются в следующем:

Алгоритмические категории не являются взаимоисключающими, поскольку для получения ответа на большинство головоломок нам необходимо использовать две или более категорий.
Набор данных доступен здесь в этом формате. Всего мы создали 18 различных головоломок, охватывающих различные алгоритмические и математические темы. Многие из этих головоломок популярны в различных развлекательных или академических учреждениях.
Всего у нас 1800 экземпляров 18 различных головоломок. Эти примеры аналогичны различным тестовым примерам головоломки, т. е. они имеют разные входные комбинации, начальное и целевое состояния и т. д. Надежное решение всех примеров потребует поиска точного алгоритма, который будет использоваться, а затем точного его применения. Это похоже на то, как мы проверяем точность компьютерной программы, направленной на решение конкретной задачи, с помощью широкого спектра тестовых примеров.
В настоящее время мы рассматриваем полный набор данных как ориентир только для оценки . Подробные примеры всех головоломок показаны здесь.
Инструкции по созданию набора данных можно найти здесь. Количество экземпляров и сложность головоломок можно произвольно масштабировать до любого желаемого размера или уровня.
Онтологическая классификация головоломок следующая:
Экспериментальную установку и сценарии можно найти в каталоге AlgoPuzzleVQA.
Пожалуйста, процитируйте следующую статью, если наша работа оказалась для вас полезной:
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

