RWKV LM
v5
Домашняя страница RWKV: https://www.rwkv.com.
Бумага RWKV-5/6 Eagle/Finch : https://arxiv.org/abs/2404.05892
Потрясающий RWKV в Vision: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
Демонстрация RWKV-6 3B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
Демо-версия RWKV-6 7B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
Демонстрационный код режима GPT RWKV-6 (с комментариями и пояснениями) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
Демонстрация режима RWKV-6 RNN: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Для справки используйте python 3.10+, torch 2.5+, cuda 12.5+, последнюю версию deepspeed, но оставьте pytorch-lightning==1.9.5.
Обучите RWKV-6 : используйте /RWKV-v5/ и --my_testing "x060" в demo-training-prepare.sh и demo-training-run.sh.
Обучите RWKV-7 : используйте /RWKV-v5/ и --my_testing "x070" в demo-training-prepare.sh и demo-training-run.sh.
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
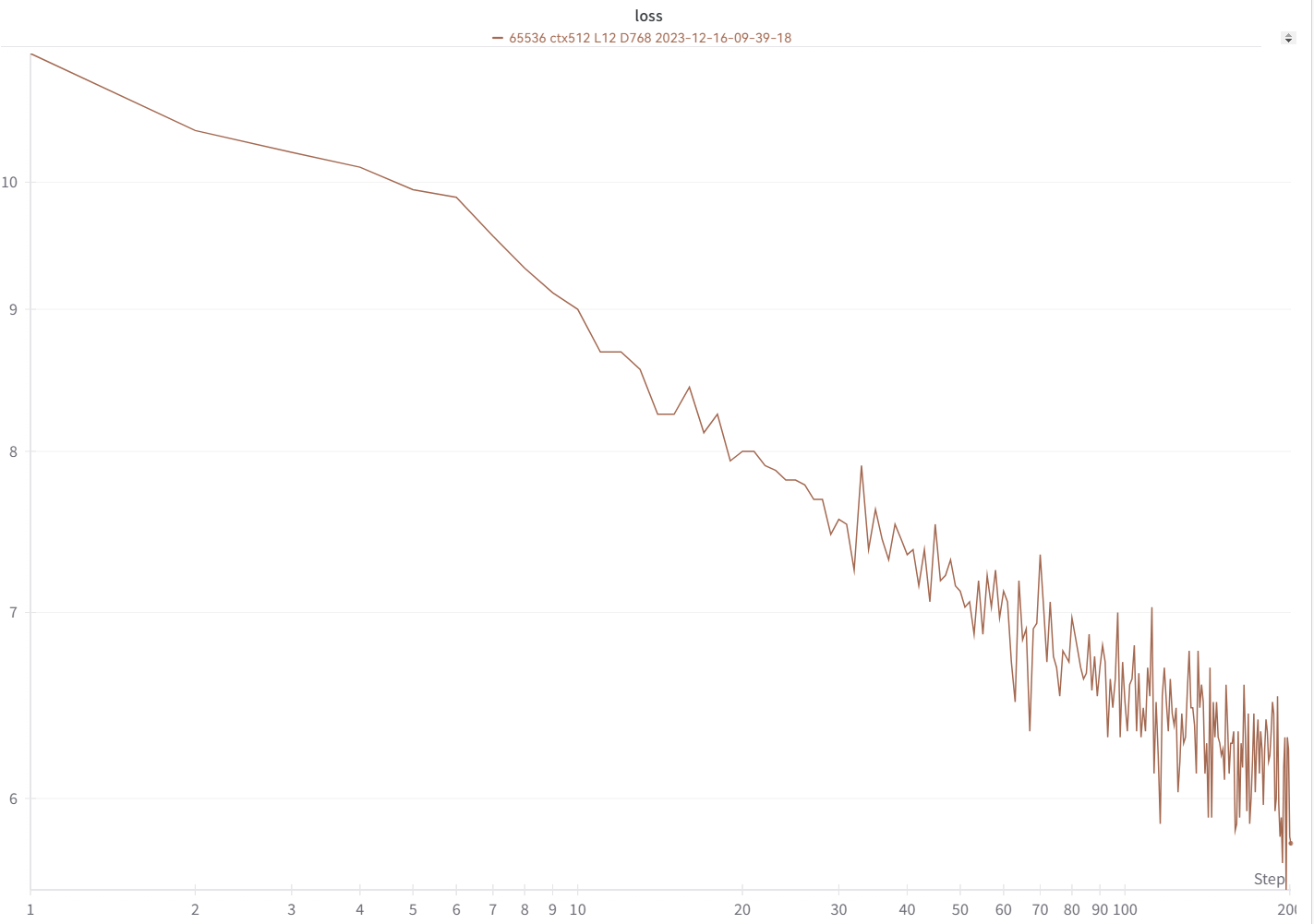
Ваша кривая потерь должна выглядеть почти точно так же, с теми же взлетами и падениями (если вы используете тот же bsz и конфигурацию):
Вы можете запустить свою модель, используя https://pypi.org/project/rwkv/ (используйте «rwkv_vocab_v20230424» вместо «20B_tokenizer.json»).
Используйте https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py, чтобы подготовить данные binidx из jsonl и вычислить «--my_exit_tokens» и «--magic_prime».
Гораздо более быстрый токенизатор больших данных: https://github.com/cahya-wirawan/json2bin.
«Эпоха» в train.py — это «мини-эпоха» (не настоящая эпоха. Только для удобства), а 1 мини-эпоха = 40320 * токенов ctx_len.
Например, если ваш binidx имеет 1498226207 токенов и ctxlen=4096, установите «--my_exit_tokens 1498226207» (это переопределит epoch_count), и оно будет 1498226207/(40320 * 4096) = 9,07 миниэпох. Тренер автоматически выйдет из игры после получения токена «--my_exit_tokens». Установите для «--magic_prime» наибольшее простое число 3n+2, меньшее, чем datalen/ctxlen-1 (= 1498226207/4096-1 = 365776), что в данном случае равно «--magic_prime 365759».
просто: подготовьте SFT jsonl => повторите данные SFT 3 или 4 раза в make_data.py. большее повторение приводит к переобучению.
продвинутый уровень: повторите данные SFT 3 или 4 раза в вашем jsonl (обратите внимание, что make_data.py перетасует все элементы jsonl) => добавьте некоторые базовые данные (например, slimpajama) в ваш jsonl => и повторите только 1 раз в make_data.py.
Исправление тренировочных шипов : см. раздел «Устранение шипов RWKV-6» на этой странице.
Простой вывод для RWKV-5 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Простой вывод для RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Примечание. В [state = kv + w *state] все должно быть в fp32, потому что w может быть очень близко к 1. Таким образом, мы можем сохранить состояние и w в fp32 и преобразовать kv в fp32.
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
демо-чат для разработчиков: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Советы для небольших моделей/небольших данных . Когда я тренирую музыкальные модели RWKV, я использую глубокие и узкие (например, L29-D512) размеры и применяю wd и dropout (например, wd=2 dropout=0,02). Примечание. Отсев RWKV-LM очень эффективен — используйте 1/4 обычного значения.
Используйте формат .jsonl для своих данных (см. форматы https://huggingface.co/BlinkDL/rwkv-5-world).
Используйте https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py, чтобы токенизировать его с помощью World tokenizer в binidx, что подходит для точной настройки мировых моделей.
Переименуйте базовую контрольную точку в папке вашей модели в rwkv-init.pth и измените команды обучения, чтобы использовать --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 для 7B.
0.1B = --n_layer 12 --n_embd 768 // 0.4B = --n_layer 24 --n_embd 1024 // 1.5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 / /7B = --n_layer 32 --n_embd 4096
В настоящее время реализация неоптимизирована, требует той же видеопамяти, что и полная версия SFT.
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
используйте rwkv 0.8.26+ для автоматической загрузки обученного «time_state»
Когда вы тренируете RWKV с нуля, попробуйте мою инициализацию для достижения наилучшей производительности. Проверьте функциюgener_init_weight() файла src/model.py:
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!! Если вы используете позиционное встраивание, возможно, лучше удалить блок.0.ln0 и использовать инициализацию по умолчанию для emb.weight вместо моей Uniform_(a=-1e-4, b=1e-4) !!!
при обучении с нуля добавьте «k = k * torch.clamp(w, max=0).exp()» перед «RUN_CUDA_RWKV6(r, k, v, w, u)» и не забудьте также изменить свой код вывода . вы увидите более быструю конвергенцию.
используйте «--adam_eps 1e-18»
«--beta2 0.95», если вы видите всплески
в Train.py сделайте «lr = lr * (0,01 + 0,99 * тренер.global_step / w_step)» (изначально 0,2 + 0,8) и «--warmup_steps 20»
«--weight_decay 0.1» приводит к лучшим окончательным потерям, если вы обучаете большое количество данных. при этом установите lr_final на 1/100 от lr_init.
RWKV — это RNN с производительностью LLM на уровне трансформатора, которую также можно обучать напрямую, как трансформатор GPT (параллелизуемый). И это на 100% без внимания. Вам нужно только скрытое состояние в позиции t, чтобы вычислить состояние в позиции t+1. Вы можете использовать режим «GPT» для быстрого вычисления скрытого состояния для режима «RNN».
Таким образом, он сочетает в себе лучшее от RNN и преобразователя — отличную производительность, быстрый вывод, экономию VRAM, быстрое обучение, «бесконечный» ctx_len и свободное встраивание предложений (с использованием конечного скрытого состояния).
Графический интерфейс RWKV Runner https://github.com/josStorer/RWKV-Runner с установкой в один клик и API
Все последние веса RWKV: https://huggingface.co/BlinkDL
ВЧ-совместимые гири RWKV: https://huggingface.co/RWKV
Пакет пакетов RWKV : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (для обучения не требуется специальное ядро CUDA, работает для любого графического процессора/процессора)
Твиттер : https://twitter.com/BlinkDL_AI
Домашняя страница : https://www.rwkv.com
Крутые проекты сообщества RWKV :
Все (300+) проектов RWKV: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories.
https://github.com/OpenGVLab/Vision-RWKV Видение RWKV
https://github.com/feizc/Diffusion-RWKV Диффузия RWKV
https://github.com/cgisky1980/ai00_rwkv_server Самый быстрый вывод WebGPU (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv серверная часть для ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp Вывод по быстрому процессору/cuBLAS/CLBlast: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state Tuning
https://github.com/RWKV/RWKV-infctx-trainer Тренер Infctx
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md Цифровой помощник с RWKV
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda Быстрый вывод графического процессора с помощью cuda/amd/vulkan
RWKV v6 в 250 строк (также с токенизатором): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 в 250 строк (также с токенизатором): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 в 150 строк (модель, вывод, генерация текста): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
Препринт RWKV v4 https://arxiv.org/abs/2305.13048
Введение в RWKV v4 и 100 строк numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
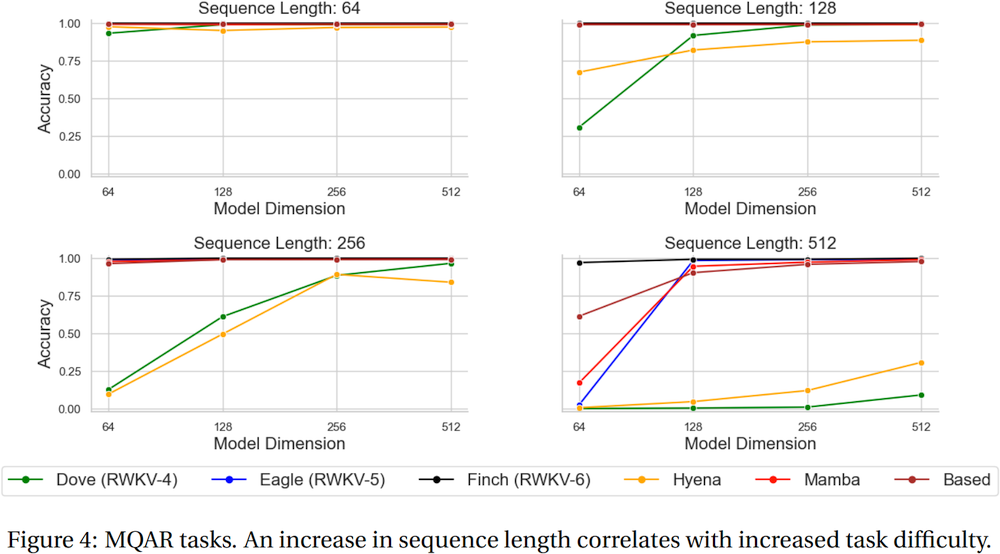
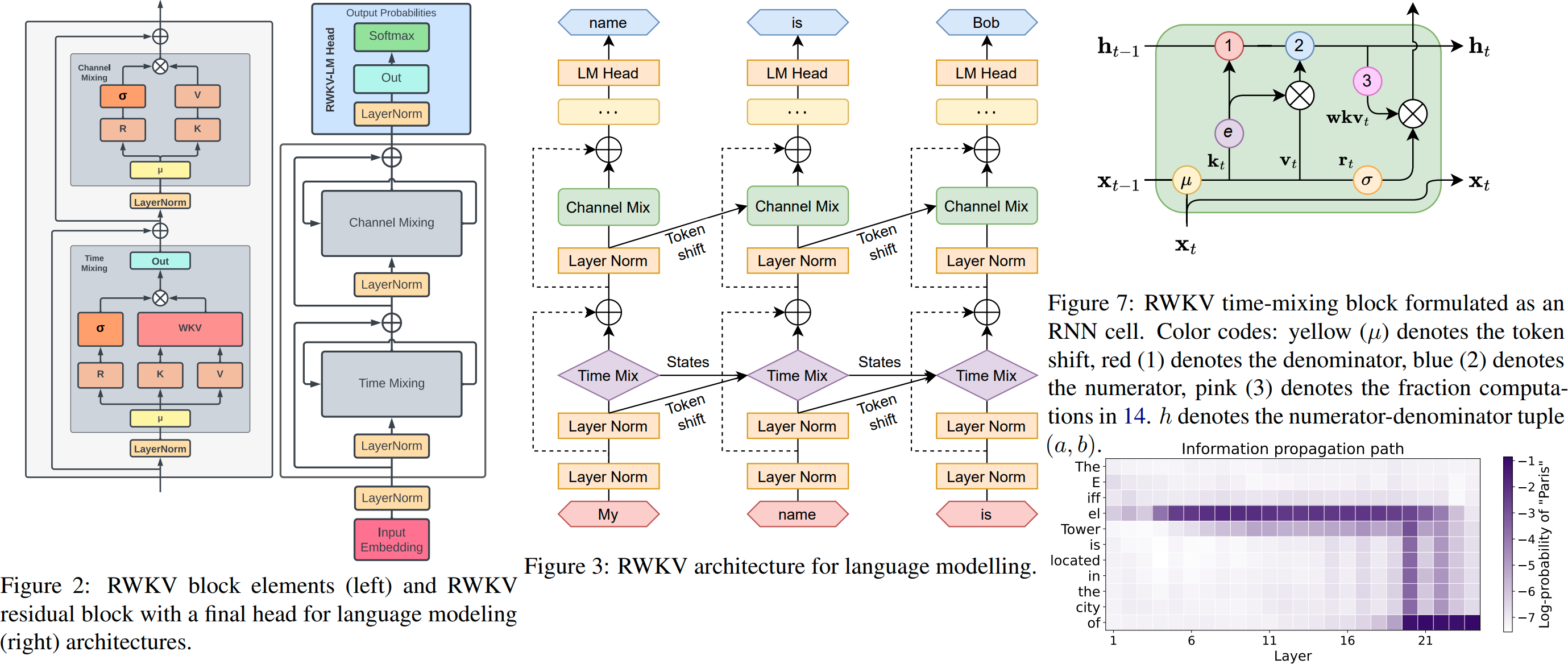
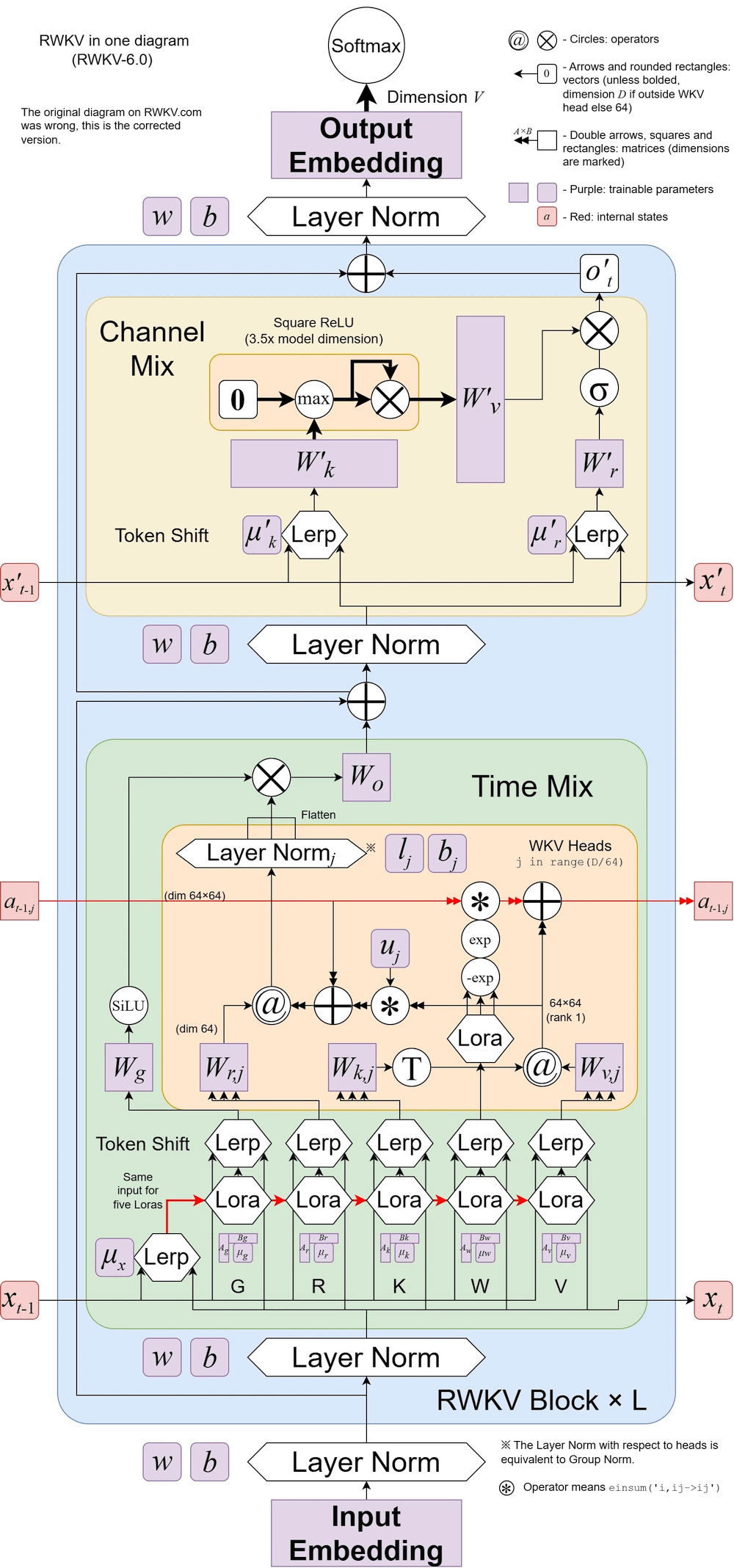
На иллюстрации RWKV v6:
Классная статья (Spiking Neural Network) с использованием RWKV: https://github.com/ridgerchu/SpikeGPT.
Вы можете присоединиться к дискорду RWKV https://discord.gg/bDSBUMeFpc, чтобы развивать его. Сейчас у нас есть много потенциальных вычислительных ресурсов (A100 40G) (спасибо Stability и EleutherAI), поэтому, если у вас есть интересные идеи, я могу их реализовать.

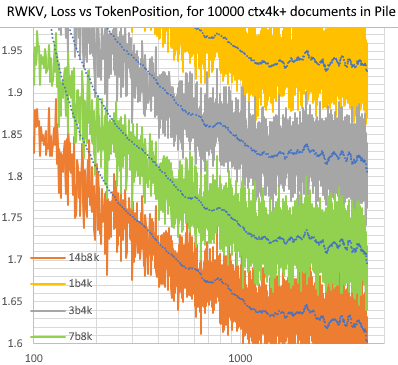
RWKV [убыток против позиции токена] для 10 000 документов ctx4k+ в Pile. RWKV 1B5-4k после ctx1500 в основном ровный, но у 3B-4k, 7B-4k и 14B-4k есть некоторые наклоны, и они становятся лучше. Это развенчивает старое мнение о том, что RNN не могут моделировать длинные ctxlens. Можно спрогнозировать, что RWKV 100B будет отличным, а RWKV 1T — это, пожалуй, все, что вам нужно :)
ЧатRWKV с RWKV 14B ctx8192:

Я считаю, что RNN — лучший кандидат для фундаментальных моделей, потому что: (1) Он более удобен для ASIC (без kv-кэша). (2) Это более дружелюбно для RL. (3) Когда мы пишем, наш мозг больше похож на RNN. (4) Вселенная тоже похожа на RNN (из-за локальности). Трансформеры — это нелокальные модели.
RWKV-3 1.5B на A40 (tf32) = всегда 0,015 с/токен, протестировано с использованием простого кода Pytorch (без CUDA), загрузка графического процессора 45 %, VRAM 7823M
GPT2-XL 1.3B на A40 (tf32) = 0,032 сек/токен (для ctxlen 1000), тестировалось с использованием HF, загрузка графического процессора тоже 45% (интересно), VRAM 9655M
Скорость обучения: (новый код обучения) RWKV-4 14B BF16 ctxlen4096 = 114 тыс. токенов/с на 8x8 A100 80G (ZERO2+CP). (старый код обучения) RWKV-4 1.5B BF16 ctxlen1024 = 106 тыс. токенов/с на 8xA100 40G.
Я тоже провожу эксперименты с изображениями (например: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder), и RWKV сможет выполнять диффузию txt2img :) Моя идея: изображение RGB 256x256 -> скрытые 32x32x13 бит - > примените RWKV для вычисления вероятности перехода для каждой сетки 32x32 -> притворитесь, что сетки независимы и «разбросаны» используя эти вероятности.
Плавное обучение – никаких скачков потерь! (lr и bsz меняются в отношении токенов 15G) 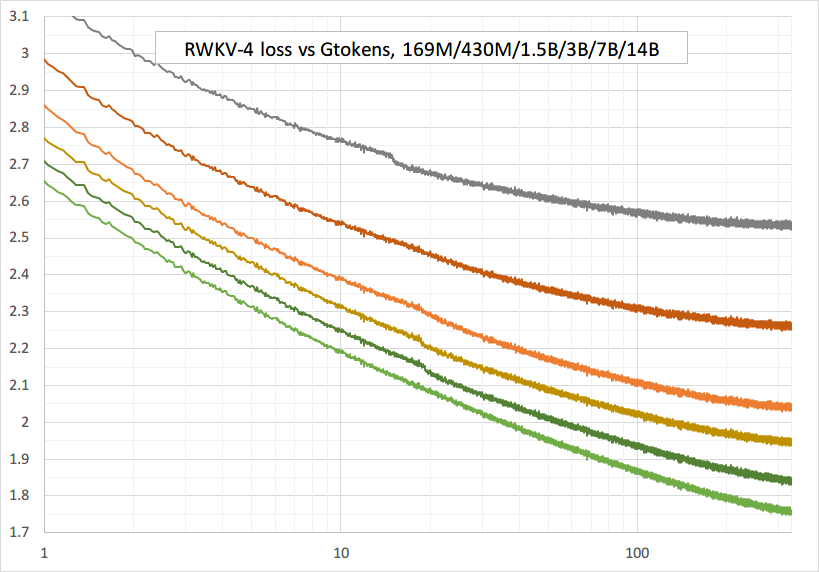
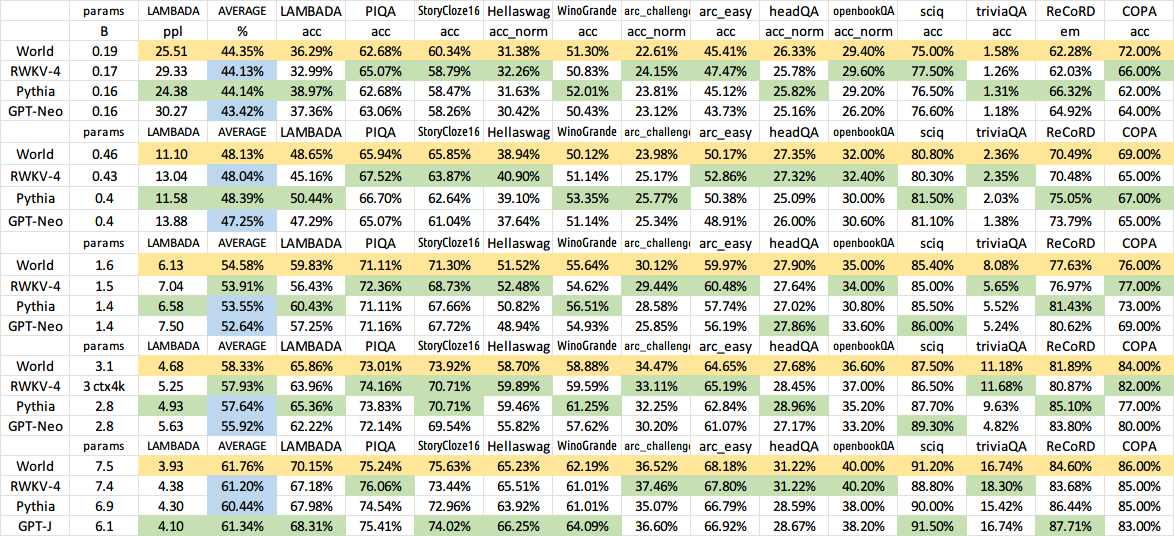
Все обученные модели будут иметь открытый исходный код. Вывод выполняется очень быстро (только матрично-векторное умножение, без матрично-матричных умножений) даже на процессорах, поэтому вы даже можете запустить LLM на своем телефоне.
Как это работает: RWKV собирает информацию по множеству каналов, которые также затухают с разной скоростью при переходе к следующему токену. Это очень просто, как только вы это поймете.
RWKV можно распараллеливать, поскольку затухание времени каждого канала не зависит от данных (и поддается обучению) . Например, в обычном RNN вы можете регулировать время затухания канала, скажем, от 0,8 до 0,5 (это называется «воротами»), а в RWKV вы просто перемещаете информацию из канала W-0,8 в канал W-0,5. -канал для достижения того же эффекта. Более того, вы можете тонко настроить RWKV в непараллелизуемую RNN (тогда вы сможете использовать выходные данные более поздних уровней предыдущего токена), если вам нужна дополнительная производительность.

Вот некоторые из моих TODO. Давайте работать вместе :)
Интеграция HuggingFace (проверьтеhuggingface/transformers#17230) и оптимизированный вывод CPU, iOS, Android, WASM и WebGL. RWKV — это RNN, очень удобный для периферийных устройств. Давайте сделаем возможным запуск LLM на вашем телефоне.
Протестируйте его на двунаправленных задачах и задачах MLM, а также на токенах изображений, аудио и видео. Я думаю, что RWKV может поддерживать Encoder-Decoder посредством этого: для каждого токена декодера используйте изученную смесь [предыдущее скрытое состояние декодера] и [окончательное скрытое состояние кодировщика]. Следовательно, все токены декодера будут иметь доступ к выходу кодера.
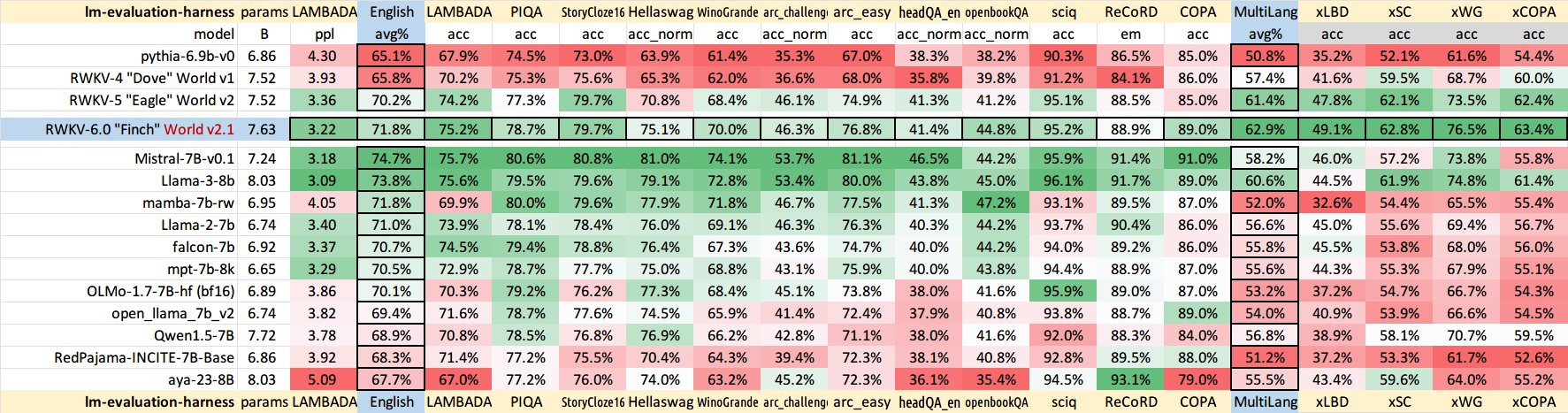
Теперь тренируем RWKV-4a с одним небольшим дополнительным вниманием (всего несколько дополнительных строк по сравнению с RWKV-4), чтобы еще больше улучшить некоторые сложные задачи с нулевым выстрелом (например, LAMBADA) для меньших моделей. См. https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829.
Отзывы пользователей:
До сих пор я экспериментировал с моделью на основе символов на нашем относительно небольшом наборе данных для предварительного обучения (около 10 ГБ текста), и результаты были чрезвычайно хорошими — аналогично моделям, обучение которых занимает гораздо больше времени.
Боже мой, rwkv очень быстрый. Я переключился на другую вкладку после того, как начал обучать ее с нуля, и когда я вернулся, она выдавала правдоподобные английские и маори слова, я ушел, чтобы приготовить в микроволновке немного кофе, а когда я вернулся, она выдавала полностью грамматически правильные предложения.
Твит Зеппа Хохрайтера (спасибо!): https://twitter.com/HochreiterSepp/status/1524270961314484227
Вы также можете найти меня (BlinkDL) в Discord EleutherAI: https://www.eleuther.ai/get-involved/
ВАЖНО: используйте deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 и cuda 11.7.1 или 11.7 (обратите внимание, что torch2 + deepspeed имеет странные ошибки и ухудшает производительность модели)
Используйте https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (последний код, совместимый с версией 4).
Вот отличная подсказка для тестирования вопросов и ответов по программам LLM. Работает для любой модели: (находится путем минимизации количества пользователей ChatGPT для RWKV 1.5B)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisЗапустите модели свай RWKV-4: загрузите модели с https://huggingface.co/BlinkDL. Установите TOKEN_MODE = 'pile' в run.py и запустите его. Это быстро даже на процессоре (режим по умолчанию).
Colab для сваи RWKV-4 1,5B : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
Запустите модели свай RWKV-4 в своем браузере (и версии onnx): см. эту проблему № 7.
Веб-демо RWKV-4: https://josephrocca.github.io/rwkv-v4-web/demo/ (примечание: пока только жадная выборка)
Для старого RWKV-2: см. здесь выпуск модели параметров 27M на enwik8 с 0,72 BPC(dev). Запустите run.py в https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN. Вы даже можете запустить его в своем браузере: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (при этом используется tf.js WASM в однопоточном режиме).
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // факел 1.13.1+cu117
ПРИМЕЧАНИЕ. Добавьте снижение веса (0,1 или 0,01) и отсев (0,1 или 0,01) при обучении на небольшом объеме данных. попробуйте x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) и т.д.
Обучение RWKV-4 с нуля: запустите train.py, который по умолчанию использует набор данных enwik8 (разархивируйте https://data.deepai.org/enwik8.zip).
Вы будете обучать версию «GPT», поскольку ее можно распараллеливать и обучать быстрее. RWKV-4 может экстраполировать, поэтому обучение с ctxLen 1024 может работать для ctxLen 2500+. Вы можете точно настроить модель с помощью более длинного ctxLen, и она быстро адаптируется к более длинному ctxLens.
Точная настройка моделей свай RWKV-4: используйте prepare-data.py в https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3, чтобы токенизировать .txt в поезд. данные npy. Затем используйте https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py для его обучения.
Прочтите код вывода в src/model.py и попробуйте использовать окончательное скрытое состояние (.xx .aa .bb) в качестве точного внедрения предложения для других задач. Вероятно, вам следует начать с .xx и .aa/.bb (.aa разделить на .bb).
Colab для точной настройки моделей свай RWKV-4: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
Большой корпус: используйте https://github.com/Abel2076/json2binidx_tool для преобразования .jsonl в .bin и .idx.
Пример формата jsonl (одна строка для каждого документа):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
генерируется таким кодом:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
Бесконечное обучение ctxlen (WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
Рассмотрим RWKV 14B. Состояние имеет 200 векторов, то есть по 5 векторов на каждый блок: fp16(xx), fp32(aa), fp32(bb), fp32(pp), fp16(xx).
Не используйте пул avg, поскольку разные векторы (xx aa bb pp xx) в состоянии имеют очень разные значения и диапазоны. Вероятно, вы можете удалить pp.
Я предлагаю сначала собрать статистику среднего + стандартного отклонения каждого канала каждого вектора и нормализовать их все (примечание: нормализация должна быть независимой от данных и собираться из различных текстов). Затем обучите линейный классификатор.
RWKV-5 имеет несколько головок, здесь показана одна головка. Для каждой головки также существует LayerNorm (отсюда и GroupNorm).
Динамический микс и динамический распад. Пример (сделайте это как для TimeMix, так и для ChannelMix):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

Используйте параллельный режим для быстрой генерации состояния, а затем используйте точно настроенную полную RNN (уровни токена n могут использовать выходные данные всех слоев токена n-1) для последовательной генерации.
Теперь время затухания равно 0,999^T (0,999 можно изучить). Измените его на что-то вроде (0,999^T + 0,1), где 0,1 тоже можно выучить. Часть 0,1 будет сохранена навсегда. Или A^T + B^T + C = быстрое затухание + медленное затухание + константа. Можно даже использовать разные формулы (например, K^2 вместо e^K для компонента распада или без нормализации).
Используйте комплексное затухание (то есть вращение вместо затухания) в некоторых каналах.
Внедрить какое-нибудь обучаемое и экстраполируемое позиционное кодирование?
Помимо 2d-вращения, мы можем попробовать другие группы Ли, такие как 3D-вращение (SO(3)). Неабелев RWKV лол.
RWKV может быть полезен для аналоговых устройств (поиск аналогового матричного векторного умножения и фотонного матричного векторного умножения). Режим RNN очень удобен для аппаратного обеспечения (обработка в памяти). Это также может быть SNN (https://github.com/ridgerchu/SpikeGPT). Интересно, можно ли его оптимизировать для квантовых вычислений?
Обучаемое начальное скрытое состояние (xx aa bb pp xx).
Послойно (или даже по строкам/столбцам, поэлементно) LR и протестируйте оптимизатор Lion.
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
Возможно, мы сможем улучшить запоминание, просто повторяя контекст (думаю, 2 раза будет достаточно). Пример: Ссылка -> Ссылка (снова) -> Вопрос -> Ответ.
Идея состоит в том, чтобы убедиться, что каждый токен в словаре понимает свою длину и необработанные байты UTF-8.
Пусть a = max(len(token)) для всех токенов в словаре. Определите AA: float[a][d_emb]
Пусть b = max(len_in_utf8_bytes(token)) для всех токенов в словаре. Определите BB: float[b][256][d_emb]
Для каждого токена X в словаре пусть [x0, x1, ..., xn] — его необработанные байты UTF-8. Мы добавим несколько дополнительных значений к его вставке EMB(X):
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (примечание: AA BB — обучаемые веса)
У меня есть идея улучшить токенизацию. Мы можем жестко запрограммировать некоторые каналы, чтобы они имели значение. Пример:
Канал 0 = «пространство»
Канал 1 = "первую букву писать заглавной буквой"
Канал 2 = «все буквы заглавные»
Поэтому:
Встраивание «abc»: [0, 0, 0, x0, x1, x2, ..]
Вложение "abc": [1, 0, 0, x0, x1, x2, ..]
Вложение "Abc": [1, 1, 0, x0, x1, x2, ..]
Встраивание «ABC»: [0, 0, 1, x0, x1, x2, ...]
......
поэтому они будут использовать большую часть встраивания. И мы можем быстро вычислить выходную вероятность всех вариантов «abc».
Примечание. В приведенном выше методе предполагается, что p("xyz")/p("xyz") одинаково для любого "xyz", что может быть ошибочным.
Лучше: определите emb_space emb_capitalize_first emb_capitalize_all как функцию emb.
Может быть, самое лучшее: пусть «abc» «abc» и т. д. поделятся последними 90% своих вложений.
В данный момент все наши токенизаторы тратят слишком много элементов, чтобы представить все варианты «abc» «abc» «Abc» и т. д. Более того, модель не может обнаружить, что они на самом деле похожи, если некоторые из этих вариантов редки в наборе данных. Этот метод может улучшить это. Я планирую протестировать это в новой версии RWKV.
Пример (вопросы и ответы в одном раунде):
Сгенерируйте окончательное состояние всех вики-документов.
Для любого пользователя Q найдите лучший вики-документ и используйте его конечное состояние в качестве начального.
Обучите модель, чтобы напрямую генерировать оптимальное начальное состояние для любого пользователя Q.
Однако это может быть немного сложнее для многораундовых вопросов и ответов :)
RWKV создан на основе AFT Apple (https://arxiv.org/abs/2105.14103).
Более того, он использует ряд моих приемов, таких как:
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb (применимо ко всем преобразователям), который помогает улучшить качество встраивания и стабилизирует Post-LN (это то, что я использую).
Токен-сдвиг: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (применимо ко всем преобразователям), особенно полезно для моделей уровня символов.
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (применимо ко всем трансформерам). Примечание: это полезно, но я отключил его в модели Pile, чтобы сохранить 100% RNN.
Дополнительный R-затвор в FFN (применимо ко всем трансформаторам). Я также использую reluSquared из Primer.
Лучшая инициализация: я инициализирую большинство матриц до НУЛЯ (см. RWKV_Init в https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py).
Вы можете перенести некоторые параметры из маленькой модели в большую (примечание: я их тоже сортирую и сглаживаю) для более быстрой и лучшей сходимости (см. https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with /).
Мое ядро CUDA: https://github.com/BlinkDL/RWKV-CUDA для ускорения обучения.

Факторы abcd работают вместе, чтобы построить кривую затухания во времени: [X, 1, W, W^2, W^3, ...].
Выпишите формулы для «жетона в позиции 2» и «жетона в позиции 3», и вы поймете:
кв/к – механизм памяти. Токен с высоким k можно запомнить надолго, если W в канале близко к 1.
R-ворота важны для производительности. k = информационная сила этого токена (для передачи в будущие токены). r = применять ли информацию к этому токену.
Используйте различные обучаемые коэффициенты TimeMix для R/K/V в слоях SA и FF. Пример:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )Используйте preLN вместо postLN (более стабильная и быстрая сходимость):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))Строительные блоки режима RWKV-3 GPT аналогичны обычному preLN GPT.
Единственная разница — дополнительный LN после встраивания. Обратите внимание, что вы можете включить этот LN во встраивание после завершения обучения.
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logitsВажно инициализировать emb крошечными значениями, такими как nn.init.uniform_(a=-1e-4, b=1e-4), чтобы использовать мой трюк https://github.com/BlinkDL/SmallInitEmb.
Для 1.5B RWKV-3 использую оптимизатор Adam (без wd, без дропаута) на 8*A100 40G.
BatchSz = 32 * 896, ctxLen = 896. Я использую tf32, поэтому BatchSz немного мал.
Для первых 15B токенов LR фиксирован на уровне 3e-4 и бета = (0,9, 0,99).
Затем я устанавливаю beta=(0,9, 0,999) и выполняю экспоненциальное затухание LR, достигая 1e-5 на 332B токенах.
Никакого внимания в обычном понимании у RWKV-3 нет, но мы все равно будем называть этот блок АТТ.
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionМатрицы self.key, self.receptance, self.output инициализируются нулем.
Векторы time_mix, time_decay, time_first переносятся из обученной модели меньшего размера (примечание: я их тоже сортирую и сглаживаю).
У блока FFN есть три особенности по сравнению с обычным GPT:
Мой трюк time_mix.
sqReLU из бумаги Primer.
Дополнительный входной элемент (аналогичный входному элементу в блоке АТТ).
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvМатрицы self.value и self.receptance инициализируются нулевым значением.

Пусть F[t] — состояние системы в момент t.
Пусть x[t] будет новым внешним входом в момент t.
В GPT прогнозирование F[t+1] требует рассмотрения F[0], F[1], .. F[t]. Таким образом, для создания последовательности длины T требуется O(T^2).
Упрощенная формула GPT:
Теоретически он очень эффективен, однако это не означает, что мы можем полностью использовать его возможности с помощью обычных оптимизаторов . Я подозреваю, что ситуация с потерями слишком сложна для наших нынешних методов.
Сравните с упрощенной формулой для RWKV (параллельный режим похож на AFT от Apple):
R, K, V — обучаемые матрицы, а W — обучаемый вектор (коэффициент затухания во времени для каждого канала).
В GPT вклад F[i] в F[t+1] взвешивается на .
В RWKV-2 вклад F[i] в F[t+1] взвешивается .
Вот изюминка: мы можем переписать это в RNN (рекурсивную формулу). Примечание:
Поэтому проверить несложно:
где A[t] и B[t] — числитель и знаменатель предыдущего шага соответственно.
Я считаю, что RWKV эффективен, потому что W подобен многократному применению диагональной матрицы. Обратите внимание (P^{-1} DP)^n = P^{-1} D^n P, поэтому это похоже на многократное применение общей диагонализуемой матрицы.
Более того, его можно превратить в непрерывный ОДУ (немного похожий на модели пространства состояний). Я напишу об этом позже.
У меня есть идея для [текста --> изображения RGB 32x32] с использованием LM (трансформатора, RWKV и т. д.). Скоро проверю.
Во-первых, потеря LM (вместо потери L2), поэтому изображение не будет размытым.
Во-вторых, квантование цвета. Например, разрешено только 8 уровней для R/G/B. Тогда размер словаря изображения составит 8x8x8 = 512 (для каждого пикселя) вместо 2^24. Следовательно, изображение RGB 32x32 = последовательность len1024 из vocab512 (токен изображения), которая является типичным входом для обычных LM. (Позже мы сможем использовать модели диффузии для повышения дискретизации и генерации изображений RGB888. Возможно, для этого мы также сможем использовать LM.)
В-третьих, 2D-позиционные встраивания, которые легко понять модели. Например, добавьте горячие координаты X и Y к первым 64 (=32+32) каналам. Скажем, если пиксель находится в точке x=8, y=20, то мы добавим 1 к каналу 8 и каналу 52 (=32+20). Более того, вероятно, мы можем добавить плавающие координаты X и Y (нормализованные к диапазону 0 ~ 1) еще к двум каналам. И другие периодические пос. кодирование тоже может помочь (проверю).
Наконец, RandRound, когда


