CAMEL
1.0.0

Мы с гордостью представляем Asclepius , более совершенную клиническую модель большого языка. Поскольку эта модель была обучена на основе синтетических клинических записей, она общедоступна через Huggingface. Если вы планируете использовать CAMEL, мы настоятельно рекомендуем вместо этого перейти на Asclepius. Для получения дополнительной информации, пожалуйста, посетите эту ссылку.
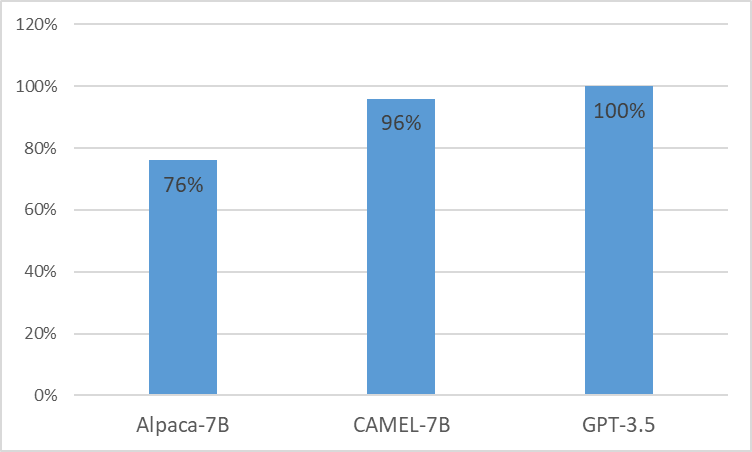
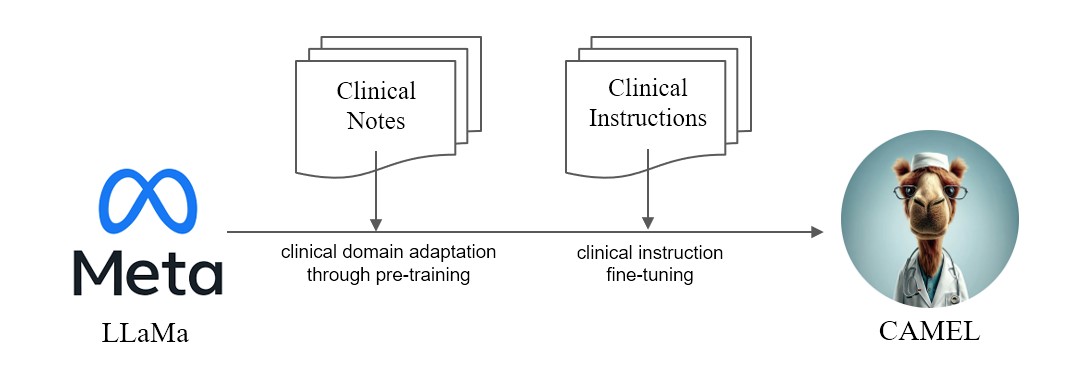
Мы представляем CAMEL , улучшенную клинически адаптированную модель от LLaMA. В качестве LLaMA для своего основания компания CAMEL дополнительно проходит предварительное обучение по клиническим записям MIMIC-III и MIMIC-IV и адаптируется к клиническим инструкциям (рис. 2). Наша предварительная оценка с использованием GPT-4 показывает, что CAMEL достигает более 96% качества OpenAI GPT-3.5 (рис. 1). В соответствии с политикой использования наших исходных данных, наш набор данных инструкций и модель будут опубликованы в PhysioNet с доступом с полномочиями. Чтобы облегчить тиражирование, мы также опубликуем весь код, что позволит отдельным медицинским учреждениям воспроизводить нашу модель, используя свои собственные клинические записи. Более подробную информацию можно найти в нашем блоге .
Из-за проблемы с лицензией на наборы данных MIMIC и i2b2 мы не можем публиковать набор данных инструкций и контрольные точки. Мы опубликуем нашу модель и данные через Physionet в течение нескольких недель.
conda create -n camel python=3.9 -y
conda activate camel
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install pandarallel pandas jupyter numpy datasets sentencepiece openai fire
pip install git+https://github.com/huggingface/transformers.git@871598be552c38537bc047a409b4a6840ba1c1e4
<eos> .$ python pretraining_preprocess/mimiciii_preproc.py --mimiciii_note_path {MIMICIII_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/mimiciv_preproc.py --discharge_note_path {DISCHAGE_NOTE_PATH} --radiology_note_path {RADIOLOGY_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/tokenize_data.py --data_path {DATA_PATH} --save_path {SAVE_PATH} $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/train.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {DATA_FILE}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 1
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
ПРИМЕЧАНИЕ. Для создания инструкций следует использовать сертифицированный API Azure Openai.
Генерация инструкций
OPENAI_API_KEYOPENAI_API_BASEOPENAI_DEPLOYMENT_NAME$ python instructino/preprocess_note.py$ python instruction/de_id_gen.py --input {PREPROCESSED_NOTES} --output {OUTPUT_FILE_1} --mode inst$ python instruction/de_id_postprocess.py --input {OUTPUT_FILE_1} --output {OUTPUT_FILE_2}$ python instruction/de_id_gen.py --input {OUTPUT__FILE_2} --output {inst_output/OUTPUT_FILE_deid} --mode ans$ python instruction/instructtion_gen.py --input {PREPROCESSED_NOTES} --output {inst_output/OUTPUT_FILE} --source {mimiciii, mimiciv, i2b2}$ python instruction/merge_data.py --data_path {inst_output} --output {OUTPUT_FILE_FINAL}Запустите точную настройку инструкции
nproc_per_node и gradient accumulate step в соответствии с вашим оборудованием (глобальный размер пакета = 128). $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/instruction_ft.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {OUTPUT_FILE_FINAL}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "epoch"
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
--ddp_timeout 18000
Запустить модель на MTSamples
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py
--model_name {MODEL_PATH}
--data_path eval/mtsamples_instructions.json
--output_path {OUTPUT_PATH}
mtsamples_results.json в папке eval .Запустите GPT-4 для оценки
python eval/gpt4_evaluate.py --input {INPUT_PATH} --output {OUTPUT_PATH}
@misc{CAMEL,
title = {CAMEL : Clinically Adapted Model Enhanced from LLaMA},
author = {Sunjun Kweon and Junu Kim and Seongsu Bae and Eunbyeol Cho and Sujeong Im and Jiyoun Kim and Gyubok Lee and JongHak Moon and JeongWoo Oh and Edward Choi},
month = {May},
year = {2023}
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/starmpcc/CAMEL}},
}


