DiGIT
1.0.0
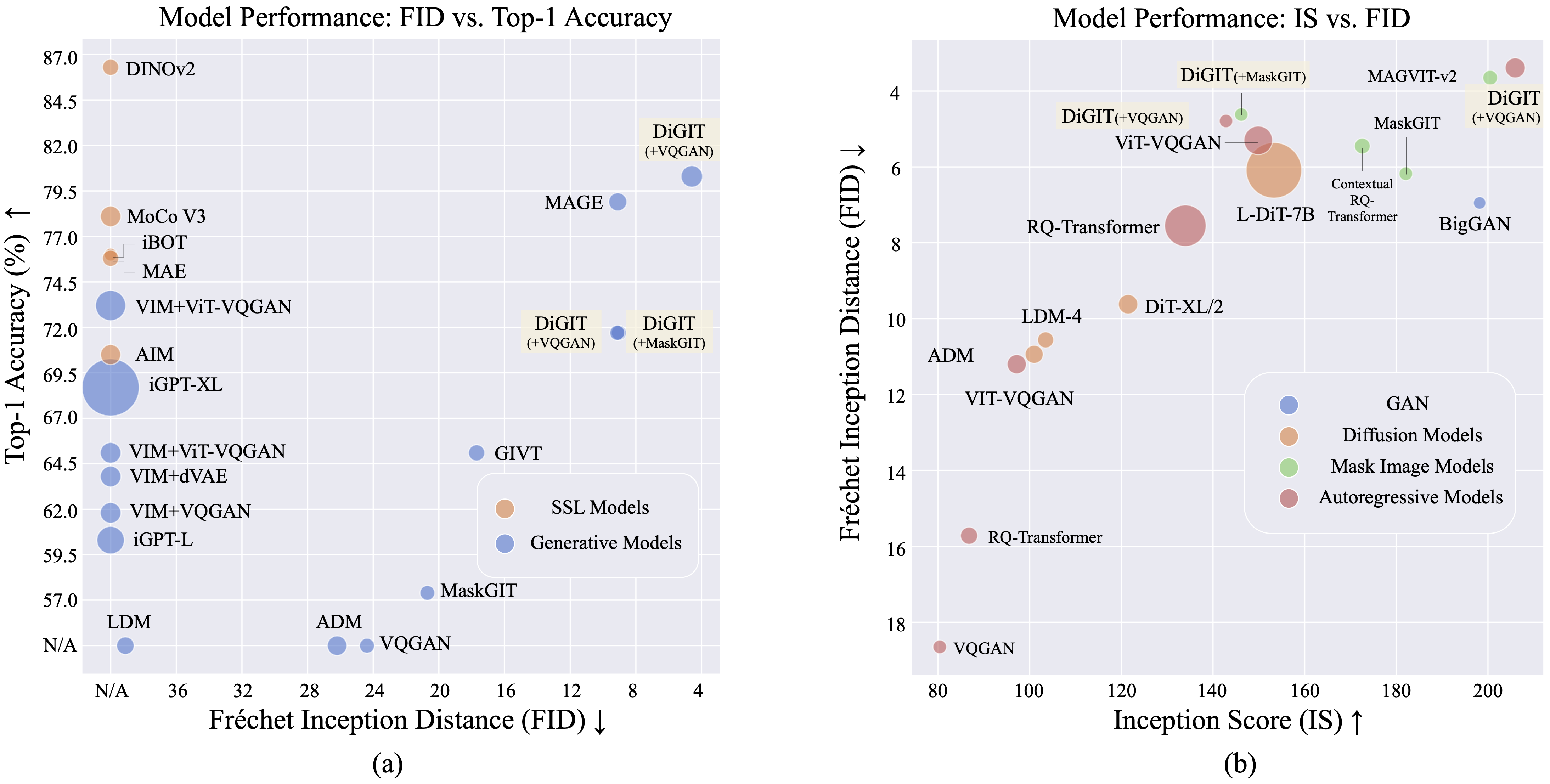
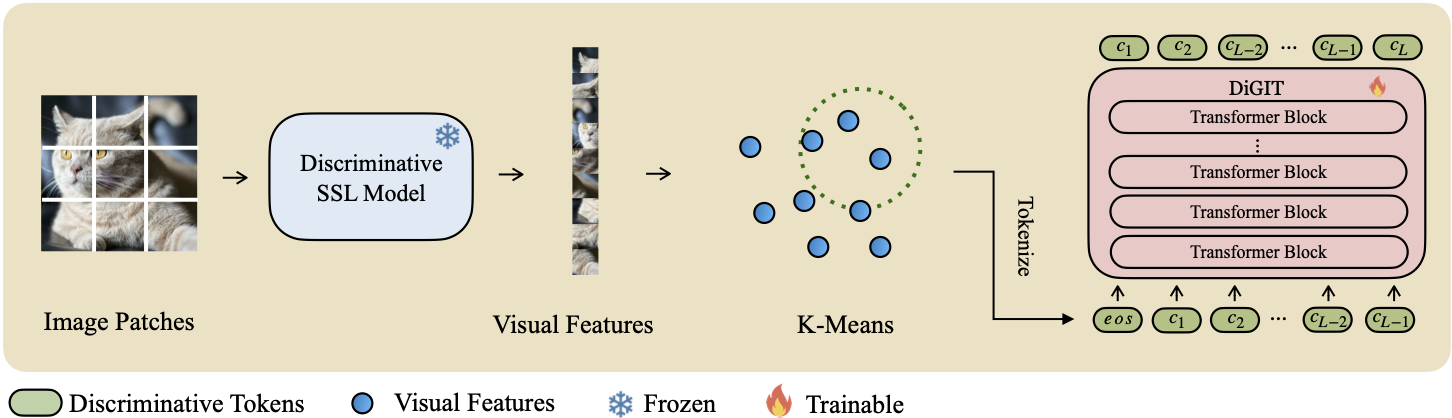
Мы представляем DiGIT , авторегрессионную генеративную модель, выполняющую прогнозирование следующего токена в абстрактном скрытом пространстве, полученном на основе моделей самоконтролируемого обучения (SSL). Применяя кластеризацию K-средних в скрытых состояниях модели DINOv2, мы эффективно создаем новый дискретный токенизатор. Этот метод значительно повышает производительность генерации изображений в наборе данных ImageNet, достигая оценки FID 4,59 для задач с безусловным классом и 3,39 для задач с условным классом . Кроме того, модель улучшает понимание изображений, достигая точности линейного зонда 80,3 .
| Методы | # Токенов | Функции | # Параметры | Топ-1 Акк. |
|---|---|---|---|---|
| iGPT-L | 32 | 1536 | 1362М | 60,3 |
| iGPT-XL | 64 | 3072 | 6801М | 68,7 |
| ВИМ+ВКГАН | 32 | 1024 | 650М | 61,8 |
| ВИМ+дВАЭ | 32 | 1024 | 650М | 63,8 |
| ВИМ+ВиТ-ВКГАН | 32 | 1024 | 650М | 65,1 |
| ВИМ+ВиТ-ВКГАН | 32 | 2048 | 1697М | 73,2 |
| ЦЕЛЬ | 16 | 1536 | 0,6Б | 70,5 |
| ДиГИТ (Наш) | 16 | 1024 | 219М | 71,7 |
| ДиГИТ (Наш) | 16 | 1536 | 732М | 80,3 |
| Тип | Методы | # Парам | # Эпоха | ПИД | ЯВЛЯЕТСЯ |
|---|---|---|---|---|---|
| ГАН | БигГАН | 70М | - | 38,6 | 24.70 |
| Диф. | ЛДМ | 395М | - | 39,1 | 22.83 |
| Диф. | АДМ | 554М | - | 26,2 | 39,70 |
| МИМ | МАГ | 200М | 1600 | 11.1 | 81,17 |
| МИМ | МАГ | 463М | 1600 | 9.10 | 105,1 |
| МИМ | МаскаGIT | 227М | 300 | 20,7 | 42.08 |
| МИМ | Цифра (+МаскаГИТ) | 219М | 200 | 9.04 | 75.04 |
| АР | ВКГАН | 214М | 200 | 24.38 | 30.93 |
| АР | ЦИФРА (+VQGAN) | 219М | 400 | 9.13 | 73,85 |
| АР | ЦИФРА (+VQGAN) | 732М | 200 | 4,59 | 141,29 |
| Тип | Методы | # Парам | # Эпоха | ПИД | ЯВЛЯЕТСЯ |
|---|---|---|---|---|---|
| ГАН | БигГАН | 160М | - | 6,95 | 198,2 |
| Диф. | АДМ | 554М | - | 10.94 | 101,0 |
| Диф. | ЛДМ-4 | 400М | - | 10.56 | 103,5 |
| Диф. | ДиТ-XL/2 | 675М | - | 9,62 | 121,50 |
| Диф. | Л-ДиТ-7Б | 7Б | - | 6.09 | 153,32 |
| МИМ | CQR-Транс | 371М | 300 | 5.45 | 172,6 |
| МИМ+АР | ВАР | 310М | 200 | 4,64 | - |
| МИМ+АР | ВАР | 310М | 200 | 3,60* | 257,5* |
| МИМ+АР | ВАР | 600М | 250 | 2,95* | 306,1* |
| МИМ | МАГВИТ-v2 | 307М | 1080 | 3,65 | 200,5 |
| АР | ВКВАЭ-2 | 13,5Б | - | 31.11 | 45 |
| АР | РК-Транс | 480М | - | 15,72 | 86,8 |
| АР | РК-Транс | 3,8Б | - | 7.55 | 134,0 |
| АР | ВиТВКГАН | 650М | 360 | 11.20 | 97,2 |
| АР | ВиТВКГАН | 1,7Б | 360 | 5.3 | 149,9 |
| МИМ | МаскаGIT | 227М | 300 | 6.18 | 182,1 |
| МИМ | Цифра (+МаскаГИТ) | 219М | 200 | 4,62 | 146,19 |
| АР | ВКГАН | 227М | 300 | 18.65 | 80,4 |
| АР | ЦИФРА (+VQGAN) | 219М | 400 | 4,79 | 142,87 |
| АР | ЦИФРА (+VQGAN) | 732М | 200 | 3.39 | 205,96 |
*: VAR обучается с использованием руководства без классификатора, в то время как все остальные модели — нет.
Файл K-Means npy и контрольные точки модели можно загрузить по адресу:
| Модель | Связь |
|---|---|
| ВЧ-веса? | Обнимающее лицо |
Для базовой модели мы используем DINOv2-base и DINOv2-large для модели большого размера. Мы используем тот же VQGAN, что и MAGE.
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITfairseq с помощью pip install fairseq . Загрузите набор данных ImageNet и поместите его в каталог своего набора данных $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012 .
Извлеките функции SSL и сохраните их как файлы .npy. Используйте алгоритм K-Means с faiss для вычисления центроидов. Вы также можете использовать наши предварительно обученные центроиды, доступные на Huggingface.
bash preprocess/run.shШаг 1
Обучите модель GPT с помощью дискриминационного токенизатора. Вы можете найти сценарии обучения в scripts/train_stage1_ar.sh , а гиперпараметры — в config/stage1/dino_base.yaml . Для настройки условного создания классов см. scripts/train_stage1_classcond.sh .
Шаг 2
Обучите пиксельный декодер (модель AR или модель NAR), основанный на дискриминационных токенах. Вы можете найти сценарии авторегрессионного обучения в scripts/train_stage2_ar.sh и сценарии обучения NAR в scripts/train_stage2_nar.sh .
Для сохранения контрольных точек будет создана папка с именем outputs/EXP_NAME/checkpoints . Файлы журналов TensorBoard сохраняются в outputs/EXP_NAME/tb . Журналы будут записываться в outputs/EXP_NAME/train.log .
Вы можете отслеживать процесс обучения с помощью tensorboard --logdir=outputs/EXP_NAME/tb .
Первая выборка дискриминационных токенов с помощью scripts/infer_stage1_ar.sh . Для размера базовой модели рекомендуется установить topk=200, а для модели большого размера — topk=400.
Затем запустите scripts/infer_stage2_ar.sh для выборки токенов VQ на основе ранее отобранных дискриминативных токенов.
Сгенерированные токены и синтезированные изображения будут храниться в каталоге с именем outputs/EXP_NAME/results .
Подготовьте набор проверки ImageNet для оценки FID:
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val Установите инструмент оценки, запустив pip install torch-fidelity .
Выполните следующую команду для оценки FID:
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shЭтот проект лицензируется по лицензии MIT — подробности см. в файле LICENSE.
Если наш проект окажется для вас полезным, надеемся, что вы сможете отметить наш репозиторий и процитировать нашу работу следующим образом.
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

