FasterTransformer
v5.3 release
Примечание. Разработка FasterTransformer перешла на TensorRT-LLM. Всем разработчикам рекомендуется использовать TensorRT-LLM, чтобы получить последние улучшения LLM Inference. Репозиторий NVIDIA/FasterTransformer останется в силе, но не получит дальнейшего развития.
Этот репозиторий предоставляет сценарий и рецепт для запуска высокооптимизированного компонента кодера и декодера на основе преобразователя, который тестируется и поддерживается NVIDIA.
В НЛП кодер и декодер являются двумя важными компонентами, причем уровень преобразователя становится популярной архитектурой для обоих компонентов. FasterTransformer реализует высокооптимизированный уровень преобразователя как для кодера, так и для декодера для вывода. В графических процессорах Volta, Turing и Ampere вычислительная мощность тензорных ядер используется автоматически, когда точность данных и весов составляют FP16.
FasterTransformer построен на основе CUDA, cuBLAS, cuBLASLt и C++. Мы предоставляем как минимум один API для следующих платформ: TensorFlow, PyTorch и бэкэнд Triton. Пользователи могут напрямую интегрировать FasterTransformer в эти платформы. Для поддержки платформ мы также предоставляем примеры кода, демонстрирующие использование и производительность этих платформ.
| Модели | Рамки | РП16 | INT8 (после Тьюринга) | Разреженность (по Амперу) | Тензорная параллель | Трубопровод параллельный | FP8 (после Хоппера) |
|---|---|---|---|---|---|---|---|
| БЕРТ | ТензорФлоу | Да | Да | - | - | - | - |
| БЕРТ | PyTorch | Да | Да | Да | Да | Да | - |
| БЕРТ | Серверная часть Тритона | Да | - | - | Да | Да | - |
| БЕРТ | С++ | Да | Да | - | - | - | Да |
| XLNet | С++ | Да | - | - | - | - | - |
| Кодер | ТензорФлоу | Да | Да | - | - | - | - |
| Кодер | PyTorch | Да | Да | Да | - | - | - |
| Декодер | ТензорФлоу | Да | - | - | - | - | - |
| Декодер | PyTorch | Да | - | - | - | - | - |
| Декодирование | ТензорФлоу | Да | - | - | - | - | - |
| Декодирование | PyTorch | Да | - | - | - | - | - |
| GPT | ТензорФлоу | Да | - | - | - | - | - |
| GPT/ОПТ | PyTorch | Да | - | - | Да | Да | Да |
| GPT/ОПТ | Серверная часть Тритона | Да | - | - | Да | Да | - |
| ГПТ-МО | PyTorch | Да | - | - | Да | Да | - |
| ЦВЕСТИ | PyTorch | Да | - | - | Да | Да | - |
| ЦВЕСТИ | Серверная часть Тритона | Да | - | - | Да | Да | - |
| ГПТ-J | Серверная часть Тритона | Да | - | - | Да | Да | - |
| Лонгформер | PyTorch | Да | - | - | - | - | - |
| Т5/УЛ2 | PyTorch | Да | - | - | Да | Да | - |
| Т5 | ТензорФлоу 2 | Да | - | - | - | - | - |
| Т5/УЛ2 | Серверная часть Тритона | Да | - | - | Да | Да | - |
| Т5 | ТензорРТ | Да | - | - | Да | Да | - |
| Т5-МОЭ | PyTorch | Да | - | - | Да | Да | - |
| Свин Трансформатор | PyTorch | Да | Да | - | - | - | - |
| Свин Трансформатор | ТензорРТ | Да | Да | - | - | - | - |
| ВИТ | PyTorch | Да | Да | - | - | - | - |
| ВИТ | ТензорРТ | Да | Да | - | - | - | - |
| GPT-NeoX | PyTorch | Да | - | - | Да | Да | - |
| GPT-NeoX | Серверная часть Тритона | Да | - | - | Да | Да | - |
| БАРТ/мБАРТ | PyTorch | Да | - | - | Да | Да | - |
| WeNet | С++ | Да | - | - | - | - | - |
| ДеБЕРТа | ТензорФлоу 2 | Да | - | - | Непрерывный | Непрерывный | - |
| ДеБЕРТа | PyTorch | Да | - | - | Непрерывный | Непрерывный | - |
Более подробная информация о конкретных моделях содержится в xxx_guide.md docs/ , где xxx означает название модели. Некоторые распространенные вопросы и соответствующие ответы помещены в docs/QAList.md . Обратите внимание, что модели Encoder и BERT схожи, и мы поместили объяснение в bert_guide.md вместе.
В следующем коде представлена структура каталогов FasterTransformer:
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
Обратите внимание, что многие папки содержат множество подпапок для разделения разных моделей. Инструменты квантования перенесены в examples , такие как examples/tensorflow/bert/bert-quantization/ и examples/pytorch/bert/bert-quantization-sparsity/ .
FasterTransformer предоставляет несколько удобных переменных среды для отладки и тестирования.
FT_LOG_LEVEL : эта среда контролирует уровень журнала отладочных сообщений. Более подробная информация находится в src/fastertransformer/utils/logger.h . Обратите внимание, что программа будет печатать много сообщений, когда уровень ниже DEBUG , и программа будет работать очень медленно.FT_NVTX : если для него установлено значение ON например FT_NVTX=ON ./bin/gpt_example , программа вставит тег nvtx, чтобы помочь профилировать программу.FT_DEBUG_LEVEL : если установлено значение DEBUG , программа будет запускать cudaDeviceSynchronize() после каждого ядра. В противном случае ядро по умолчанию выполняется асинхронно. Во время отладки полезно найти точку ошибки. Но этот флаг существенно влияет на производительность программы. Поэтому его следует использовать только для отладки. Настройки оборудования:
Чтобы запустить следующий тест, нам нужно установить вычислительный инструмент Unix «bc» с помощью
apt-get install bc Результаты FP16 TensorFlow были получены путем запуска benchmarks/bert/tf_benchmark.sh .
Результаты INT8 TensorFlow были получены путем запуска benchmarks/bert/tf_int8_benchmark.sh .
Результаты FP16 для PyTorch были получены путем запуска benchmarks/bert/pyt_benchmark.sh .
Результаты INT8 для PyTorch были получены путем запуска benchmarks/bert/pyt_int8_benchmark.sh .
Дополнительные тесты помещены в docs/bert_guide.md .
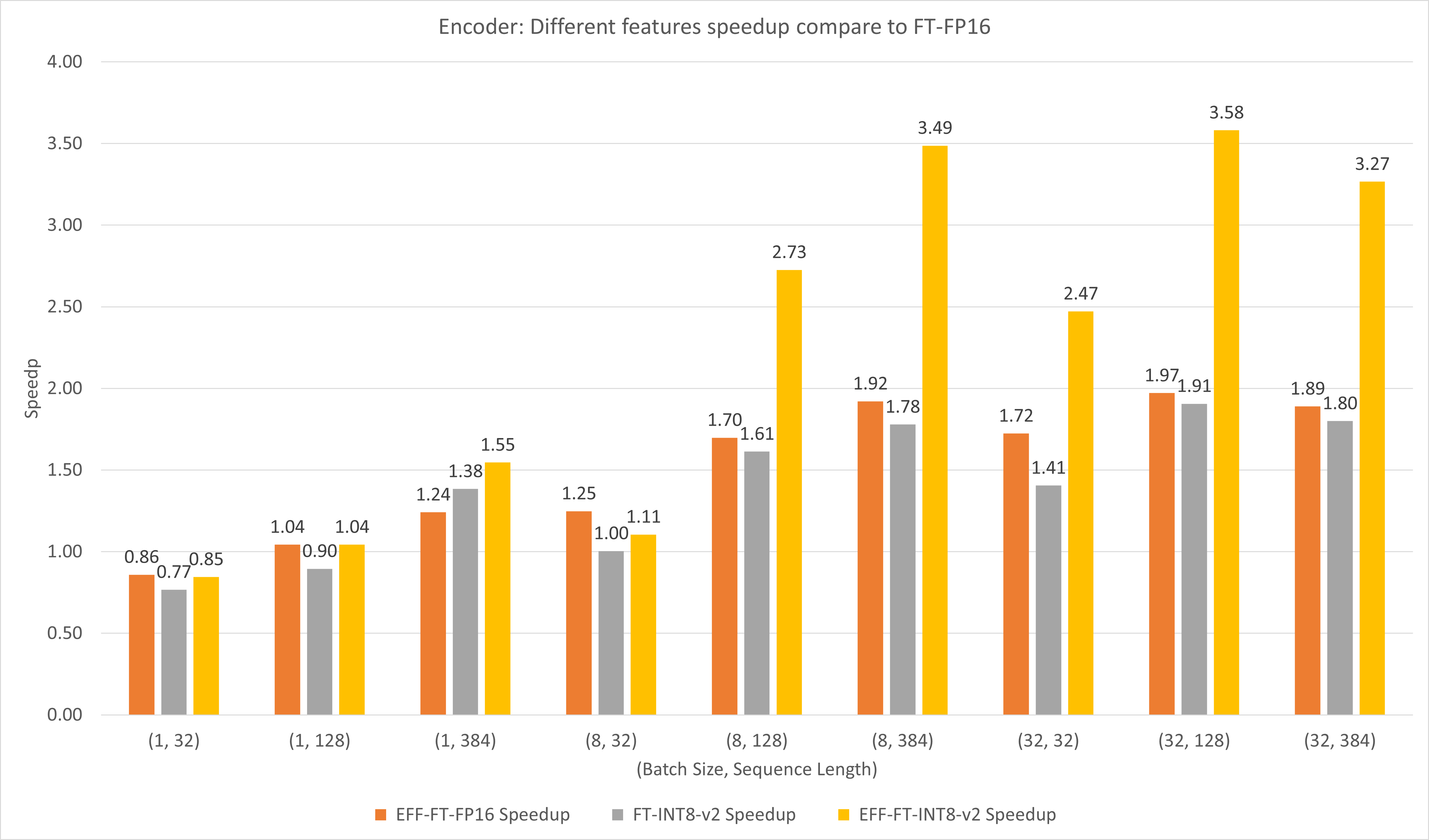
На следующем рисунке сравнивается производительность различных функций FasterTransformer и FasterTransformer в FP16 на T4.
Для большого размера пакета и длины последовательности как EFF-FT, так и FT-INT8-v2 обеспечивают двукратное ускорение. Одновременное использование эффективных FasterTransformer и int8v2 может привести к увеличению скорости примерно в 3,5 раза по сравнению с FasterTransformer FP16 для больших случаев.
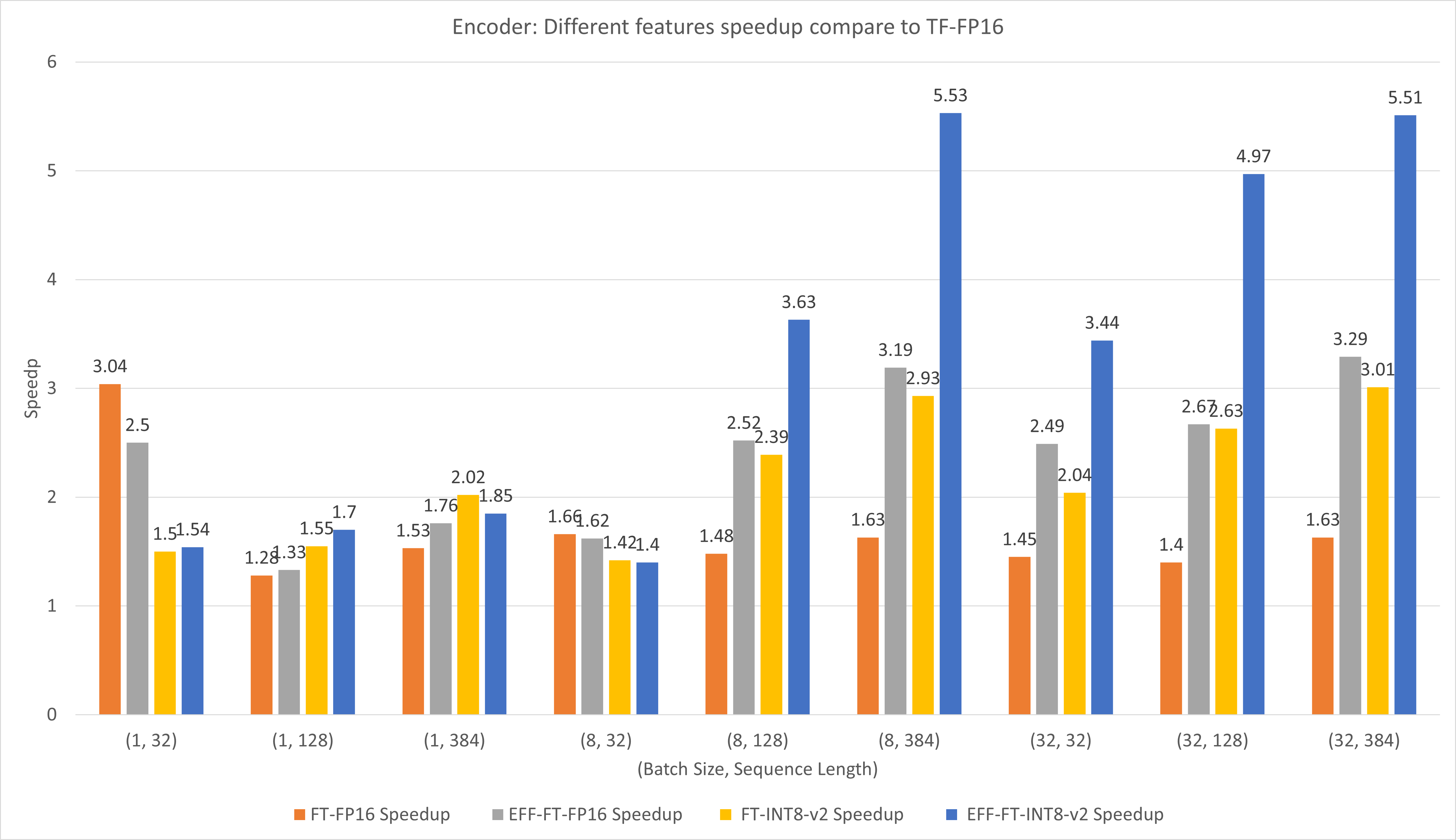
На следующем рисунке сравнивается производительность различных функций FasterTransformer и TensorFlow XLA в FP16 на T4.
Для небольшого размера пакета и длины последовательности использование FasterTransformer может привести к ускорению примерно в 3 раза.
Для большого размера пакета и длины последовательности использование эффективного FasterTransformer с квантованием INT8-v2 может привести к ускорению примерно в 5 раз.
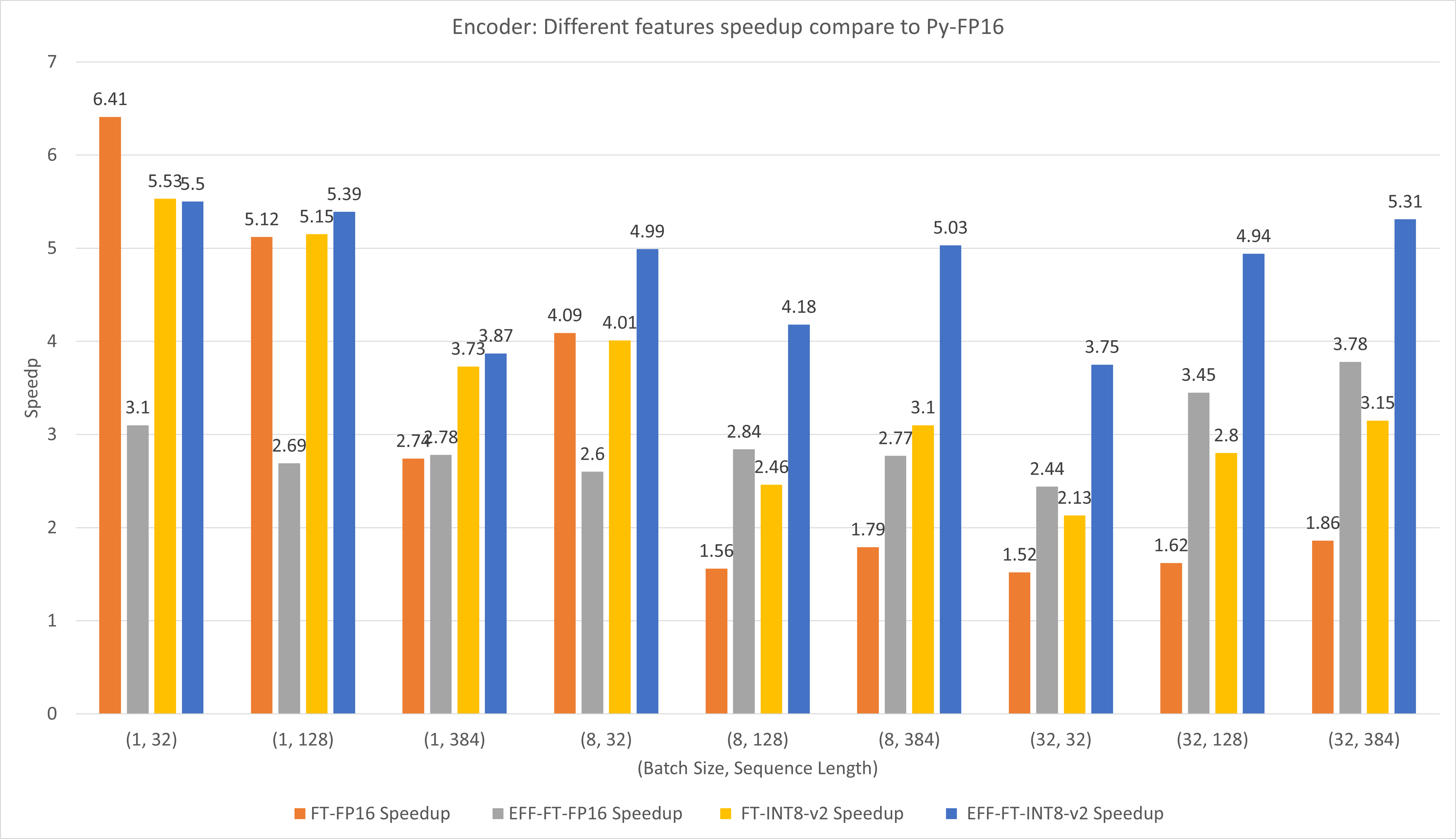
На следующем рисунке сравнивается производительность различных функций FasterTransformer и PyTorch TorchScript под управлением FP16 на T4.
Для небольшого размера пакета и длины последовательности использование FasterTransformer CustomExt может привести к ускорению примерно в 4–6 раз.
Для большого размера пакета и длины последовательности использование эффективного FasterTransformer с квантованием INT8-v2 может привести к ускорению примерно в 5 раз.
Результаты TensorFlow были получены путем запуска benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh и benchmarks/decoding/tf_decoding_sampling_benchmark.sh
Результаты PyTorch были получены путем запуска benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh .
В экспериментах по декодированию мы обновили следующие параметры:
Дополнительные тесты помещены в docs/decoder_guide.md .
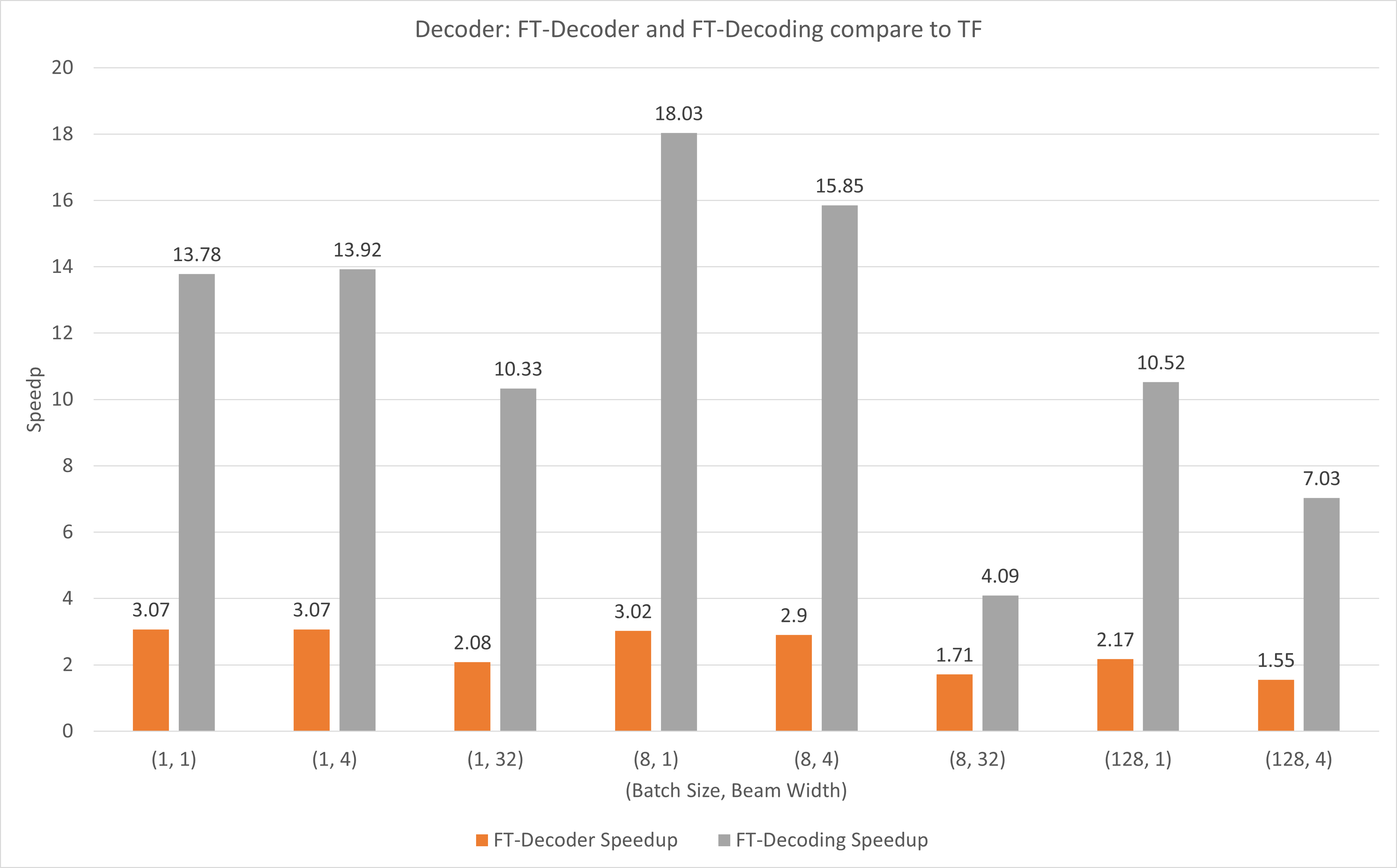
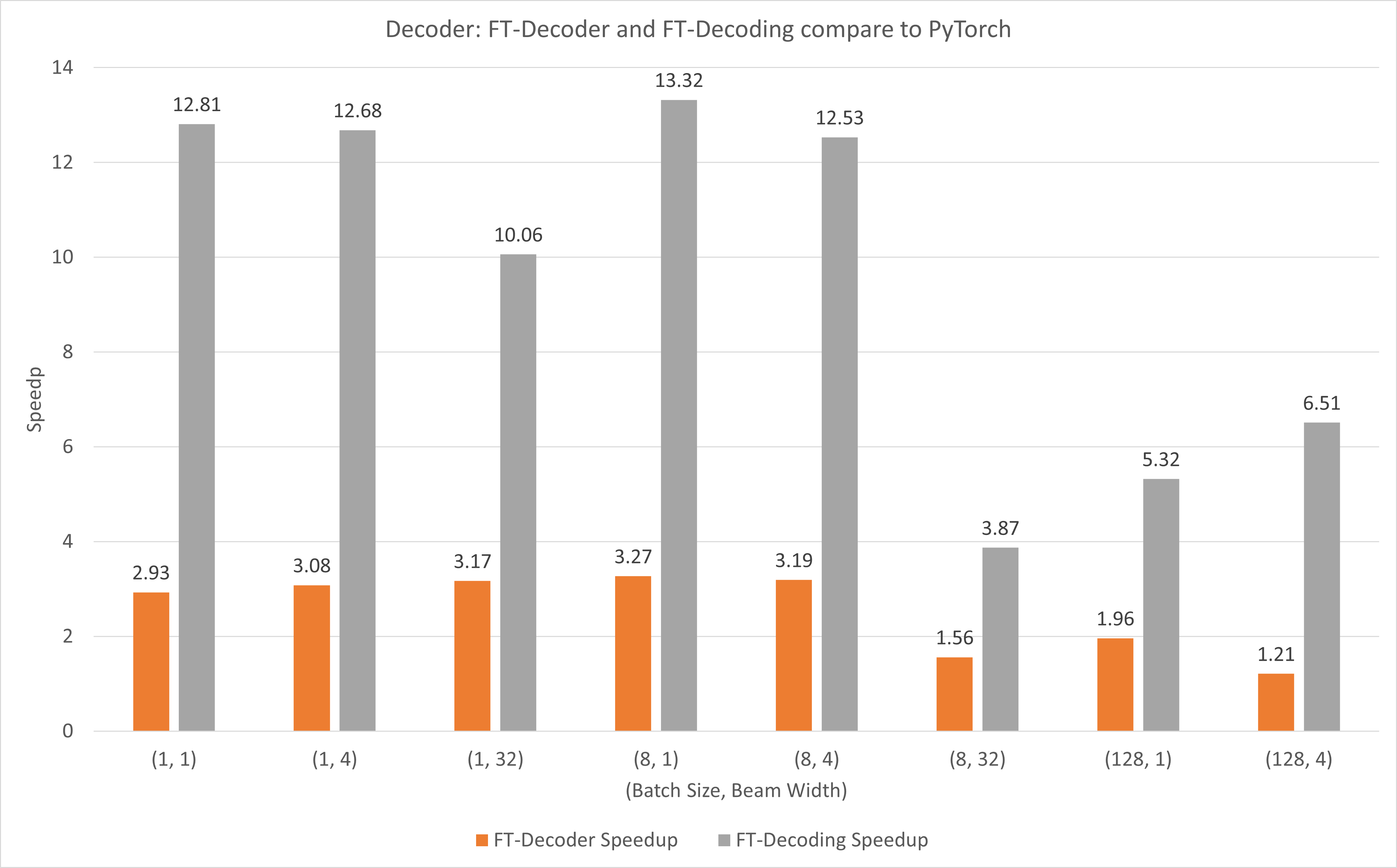
На следующем рисунке показано ускорение операций FT-декодера и операций FT-декодирования по сравнению с TensorFlow в FP16 с T4. Здесь мы используем пропускную способность трансляции тестового набора, чтобы предотвратить разное общее количество токенов каждого метода. По сравнению с TensorFlow, FT-Decoder обеспечивает ускорение в 1,5–3 раза; в то время как FT-декодирование обеспечивает ускорение в 4–18 раз.
На следующем рисунке показано ускорение операций FT-Decoder и FT-Decoding по сравнению с PyTorch под FP16 с T4. Здесь мы используем пропускную способность трансляции тестового набора, чтобы предотвратить разное общее количество токенов каждого метода. По сравнению с PyTorch, FT-Decoder обеспечивает ускорение в 1,2–3 раза; в то время как FT-декодирование обеспечивает ускорение в 3,8–13 раз.
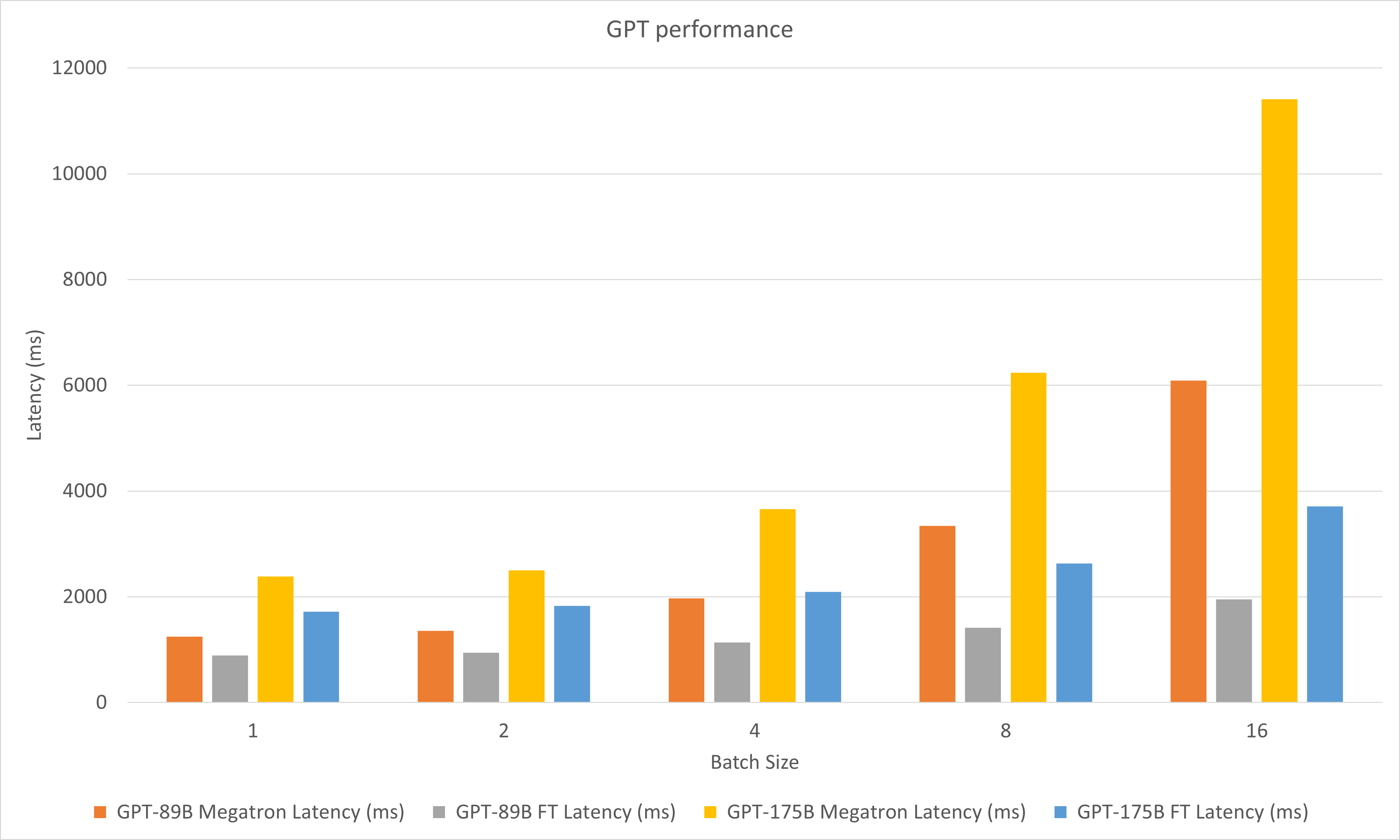
На следующем рисунке сравниваются характеристики Megatron и FasterTransformer при FP16 на A100.
В экспериментах по декодированию мы обновили следующие параметры:
май 2023 г.
январь 2023 г.
декабрь 2022 г.
ноябрь 2022 г.
октябрь 2022 г.
Сентябрь 2022 г.
август 2022 г.
июль 2022 г.
июнь 2022 г.
май 2022 г.
апрель 2022 г.
март 2022 г.
stop_ids и ban_bad_ids в GPT-J.start_id и end_id в GPT-J, GPT, T5 и декодировании.февраль 2022 г.
декабрь 2021 г.
ноябрь 2021 г.
август 2021 г.
layer_para в pipeline_para .size_per_head 96, 160, 192, 224, 256 для модели GPT.июнь 2021 г.
апрель 2021 г.
декабрь 2020 г.
ноябрь 2020 г.
сентябрь 2020 г.
август 2020 г.
июнь 2020 г.
май 2020 г.
translate_sample.py .апрель 2020 г.
decoding_opennmt.h в decoding_beamsearch.hdecoding_sampling.hbert_transformer_op.h , bert_transformer_op.cu.cc в bert_transformer_op.ccdecoder.h , decoder.cu.cc в decoder.ccdecoding_beamsearch.h , decoding_beamsearch.cu.cc в decoding_beamsearch.ccbleu_score.py в utils . Обратите внимание, что для оценки BLEU требуется python3.март 2020 г.
translate_sample.py , чтобы продемонстрировать, как переводить предложение, восстанавливая предварительно обученную модель OpenNMT-tf.февраль 2020 г.
июль 2019 г.
import torch . Если это произошло, то это связано с несовместимостью C++ ABI. Возможно, вам потребуется проверить, что PyTorch, используемый во время компиляции и выполнения, один и тот же, или вам нужно проверить, как компилируется ваш PyTorch, версию вашего GCC и т. д.

