PatrickStar
v0.4.6

См. CHANGE_LOG.md.
Предварительно обученные модели (PTM) становятся горячей точкой как исследований НЛП, так и их отраслевого применения. Однако обучение PTM требует огромных аппаратных ресурсов, что делает его доступным лишь небольшой части людей в сообществе ИИ. Теперь ПатрикСтар сделает обучение ПТМ доступным каждому!
Ошибка нехватки памяти (OOM) — кошмар каждого инженера, обучающего PTM. Нам часто приходится использовать больше графических процессоров для хранения параметров модели, чтобы предотвратить такие ошибки. ПатрикСтар предлагает лучшее решение такой проблемы. Благодаря гетерогенному обучению (его также использует DeepSpeed Zero Stage 3) ПатрикСтар может полностью использовать память как ЦП, так и графического процессора, чтобы вы могли использовать меньшее количество графических процессоров для обучения более крупных моделей.
Идея Патрика такая. Немодельные данные (в основном активации) меняются во время обучения, но текущие гетерогенные решения для обучения статически разделяют данные модели на ЦП и ГП. Чтобы лучше использовать графический процессор, ПатрикСтар предлагает динамическое планирование памяти с помощью модуля управления памятью на основе фрагментов. Управление памятью в Патрике Стар поддерживает выгрузку всего, кроме текущей вычислительной части модели, на ЦП для экономии графического процессора. Кроме того, управление памятью на основе фрагментов эффективно для коллективного взаимодействия при масштабировании на несколько графических процессоров. См. статью и этот документ, чтобы узнать об идее ПатрикСтар.
В эксперименте Патрикстар v0.4.3 способен обучать модель с 18 миллиардами (18 байт) параметров с 8 графическими процессорами Tesla V100 и 240 ГБ памяти графического процессора в узле центра обработки данных WeChat, чья топология сети выглядит следующим образом. ПатрикСтар более чем в два раза больше, чем ДипСпид. Кроме того, производительность ПатрикСтар лучше для моделей одинакового размера. Pstar — это ПатрикСтар v0.4.3. Глубины указывают на производительность DeepSpeed v0.4.3 с использованием официального примера DeepSpeed, пример нулевой стадии 3, с оптимизацией активации, открывающейся по умолчанию.

Мы также протестировали ПатрикСтар v0.4.3 на одном узле A100 SuperPod. Он может обучать модель 68B на 8xA100 с памятью ЦП 1 ТБ, что более чем в 6 раз больше, чем у DeepSpeed v0.5.7. Помимо масштаба модели, ПатрикСтар намного эффективнее DeepSpeed. Тестовые скрипты находятся здесь.

Подробные результаты тестов в центре обработки данных WeChat AI и NVIDIA SuperPod опубликованы в этом документе Google.
Масштабируйте ПатрикСтар на несколько компьютеров (узлов) на SuperPod. Нам удалось обучить GPT3-175B на 32 графических процессорах. Насколько нам известно, это первая работа, запускающая GPT3 на таком небольшом кластере графических процессоров. Microsoft использовала 10 000 V100 для поддержки GPT3. Теперь вы можете настроить его или даже предварительно обучить свой собственный на 32 графических процессорах A100, потрясающе!

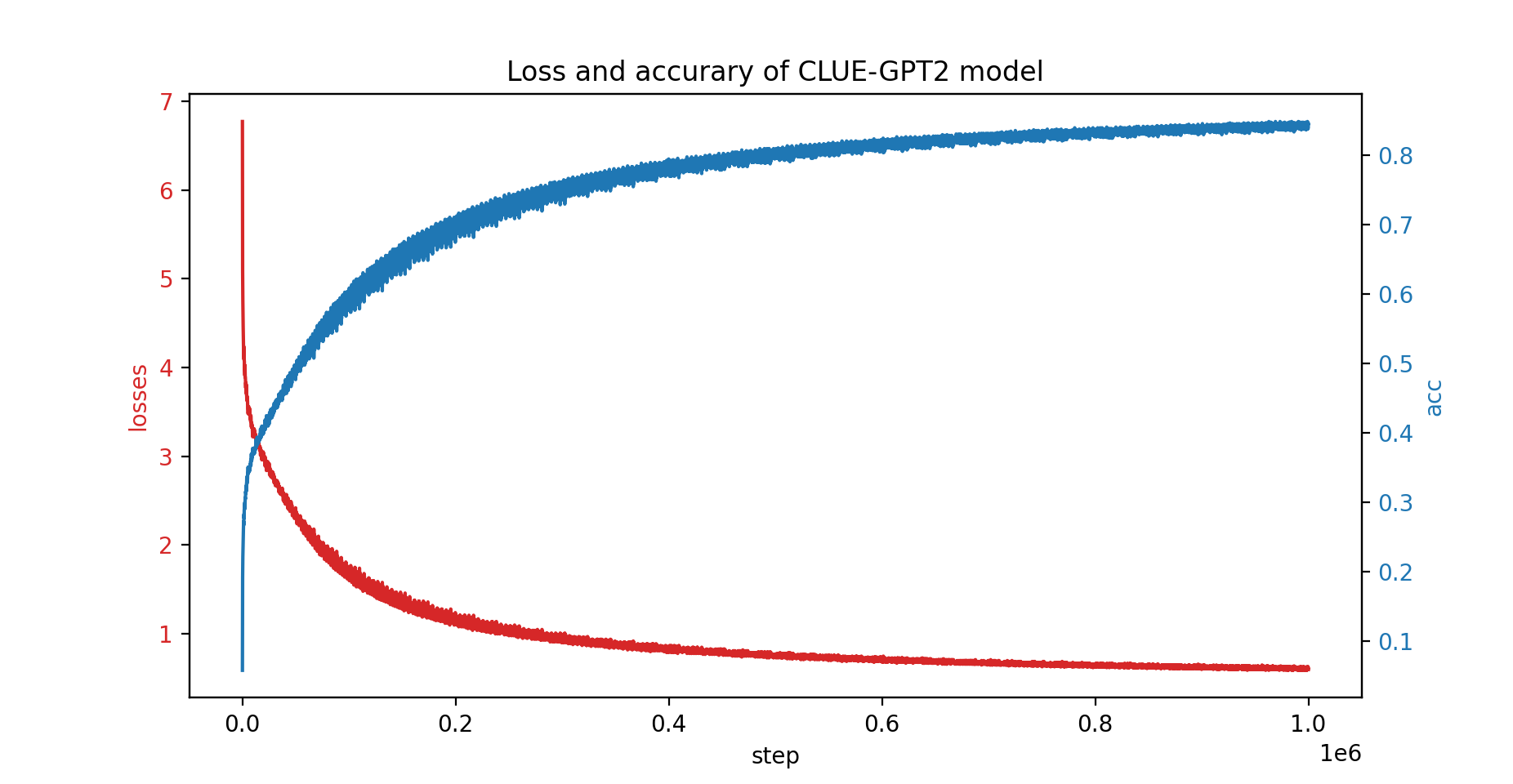
Мы также обучили модель CLUE-GPT2 с помощью ПатрикСтар, кривая потерь и точности показана ниже:
pip install .Обратите внимание, что для ПатрикСтар требуется gcc версии 7 или выше. Вы также можете использовать изображения NVIDIA NGC, протестировано следующее изображение:
docker pull nvcr.io/nvidia/pytorch:21.06-py3ПатрикСтар основан на PyTorch, что упрощает миграцию проекта Pytorch. Вот пример ПатрикСтар:
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () Мы используем тот же формат config , что и JSON конфигурации DeepSpeed, который в основном включает параметры оптимизатора, масштабатора потерь и некоторые конфигурации, специфичные для ПатрикСтар.
Подробное объяснение приведенного выше примера можно найти в руководстве здесь.
Дополнительные примеры можно найти здесь.
Сценарий быстрого запуска теста находится здесь. Он выполняется со случайно сгенерированными данными; поэтому вам не нужно готовить реальные данные. Также были продемонстрированы все методы оптимизации patrickstar. Дополнительные приемы оптимизации при выполнении теста см. в разделе «Параметры оптимизации».
Лицензия BSD, 3 пункта
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josephyu}@tencent.com
При поддержке команды WeChat AI и Tencent NLP Oteam.


