xcodec
1.0.0
Единый семантический и акустический кодек для модели аудиоязыка.
Название : Кодек имеет значение: исследование семантических недостатков кодека для модели языка аудио
Авторы : Чжэнь Е, Пейвэнь Сунь, Цзяхэ Лэй, Хунчжан Линь, Сюй Тан, Чжэци Дай, Цюцян Конг, Цзяньи Чен, Цзяхао Пан, Цифэн Лю, Ике Го*, Вэй Сюэ*
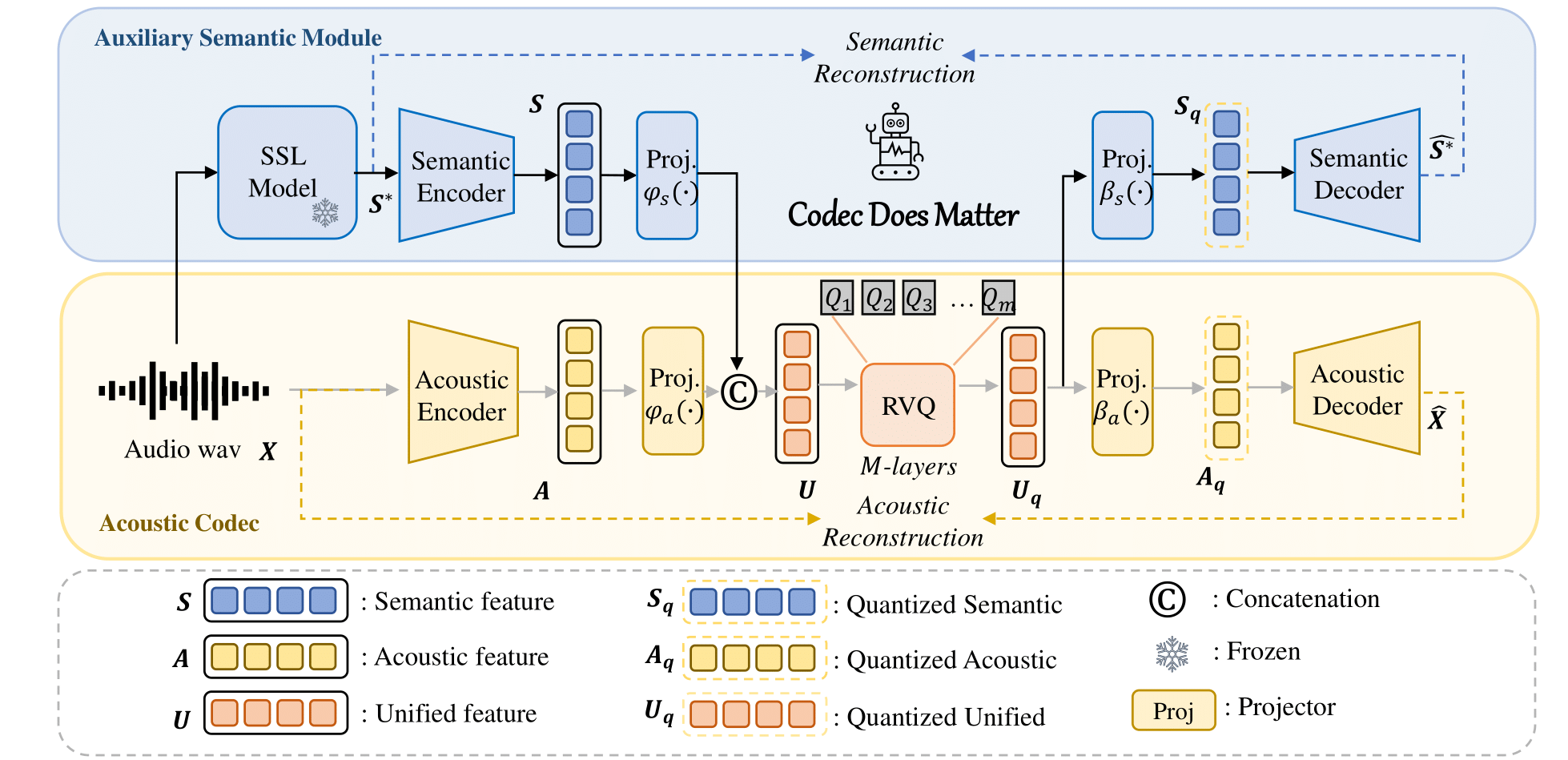
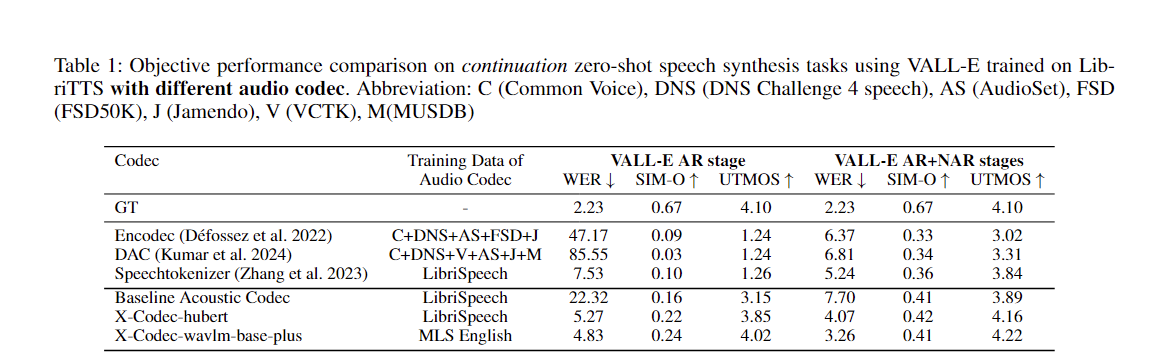
Вы можете легко применить наш подход для улучшения любого существующего акустического кодека:
Например
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) Для получения более подробной информации, пожалуйста, обратитесь к нашему коду.
? ссылки на центр моделей Huggingface.
| Название модели | Обнимающее лицо | Конфигурация | Семантическая модель | Домен | Данные обучения |
|---|---|---|---|---|---|
| xcodec_hubert_librispeech | ? | ? | ? База Юбера | Речь | Либрисречь |
| xcodec_wavlm_mls (не упоминается в статье) | ? | ? | ? Wavlm-база-плюс | Речь | МЛС английский |
| xcodec_wavlm_more_data (не упоминается в статье) | ? | ? | ? Wavlm-база-плюс | Речь | MLS английский + Внутренние данные |
| xcodec_hubert_general_audio | ? | ? | ?Губерт-база-общее-аудио | Общий звук | 200 тыс. часов внутренних данных |
| xcodec_hubert_general_audio_more_data (не упоминается в статье) | ? | ? | ?Губерт-база-общее-аудио | Общий звук | Более сбалансированные данные |
Чтобы выполнить вывод, сначала загрузите модель и конфигурацию обнимающего лица.
python inference.pyПодготовьте файл Training_file и Validation_file в конфигурации. В файле должны быть указаны пути к вашим аудиофайлам:
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...Затем:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.pyОсобую благодарность хотелось бы выразить авторам Uniaudio и DAC, поскольку наша кодовая база в основном заимствована у Uniaudio и DAC.
Если вы найдете этот репозиторий полезным, рассмотрите возможность цитирования в следующем формате:
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

